

큐를 활용한 배치 시스템을 분석하고 개선해보자 (1)
1. 들어가며
부끄럽게도 사실 현재 운영중인 애플리케이션의 성능과 지표를 제대로 측정하고 검토해본적이 없었습니다. 늦었지만, 이제부터라도 반년 가량 운영해본 서비스의 성능과 지표를 측정해보려고 합니다. 그래서 현재 어떤 상태인지 확인하고, 이 지표를 가지고 개선할 것들을 판단하려고 합니다.
2. 지표를 보기전, 우리 상황을 검토해보기
지표를 깊게 살펴보기 전에 우리의 상황을 검토해보려고 합니다. 지표가 있는데 잘 쓰지 못하는 경우들이 무엇이 있을까요? 저희는 지표를 제대로 측정하지 않았었는데, 아래와 같은 경우들이 저희에게 해당하는 케이스로 보입니다.
측정을 안해서 문제를 모르는 경우
리소스를 깊게 살펴보기 전에 판단해야 하는 것들이 있습니다. 특정 API가 느려지고 있어도 측정하지 않아서, 뒤늦게 발견하고 체감하는 경우들이 있었습니다.
문제라고 느끼는 것들이 실제로 문제의 원인인가?
특정 API 호출이 느린 것 같은데, 막상 수집 데이터를 보니 문제가 없었던 경험이 있었는데요, 제대로 측정하지 않으면 보이는 것만 가지고 추측하게 되고 시간과 리소스를 낭비할 위험성이 있다고 생각합니다. 따라서 더 나은 선택을 하기 위해서는 데이터가 필요하고 측정이 가능해야 합니다.
3. 그라파나 대시보드 확인
우선 저희가 수집하고 있는 그라파나 대시보드부터 확인해보려고 합니다. 크게 메모리, CPU, 패킷, 대역폭을 살펴보려고 해요.
시작하기 전에 저희 서비스의 현실적인 트래픽 규모를 먼저 말씀드리면, 하루 약 93,000건, 초당 약 1.1건 수준입니다. 솔직히 트래픽이 거의 없는 수준이에요. 이 점을 염두에 두고 아래 지표들을 봐주시면 좋겠습니다.
메모리
평균 메모리 사용량
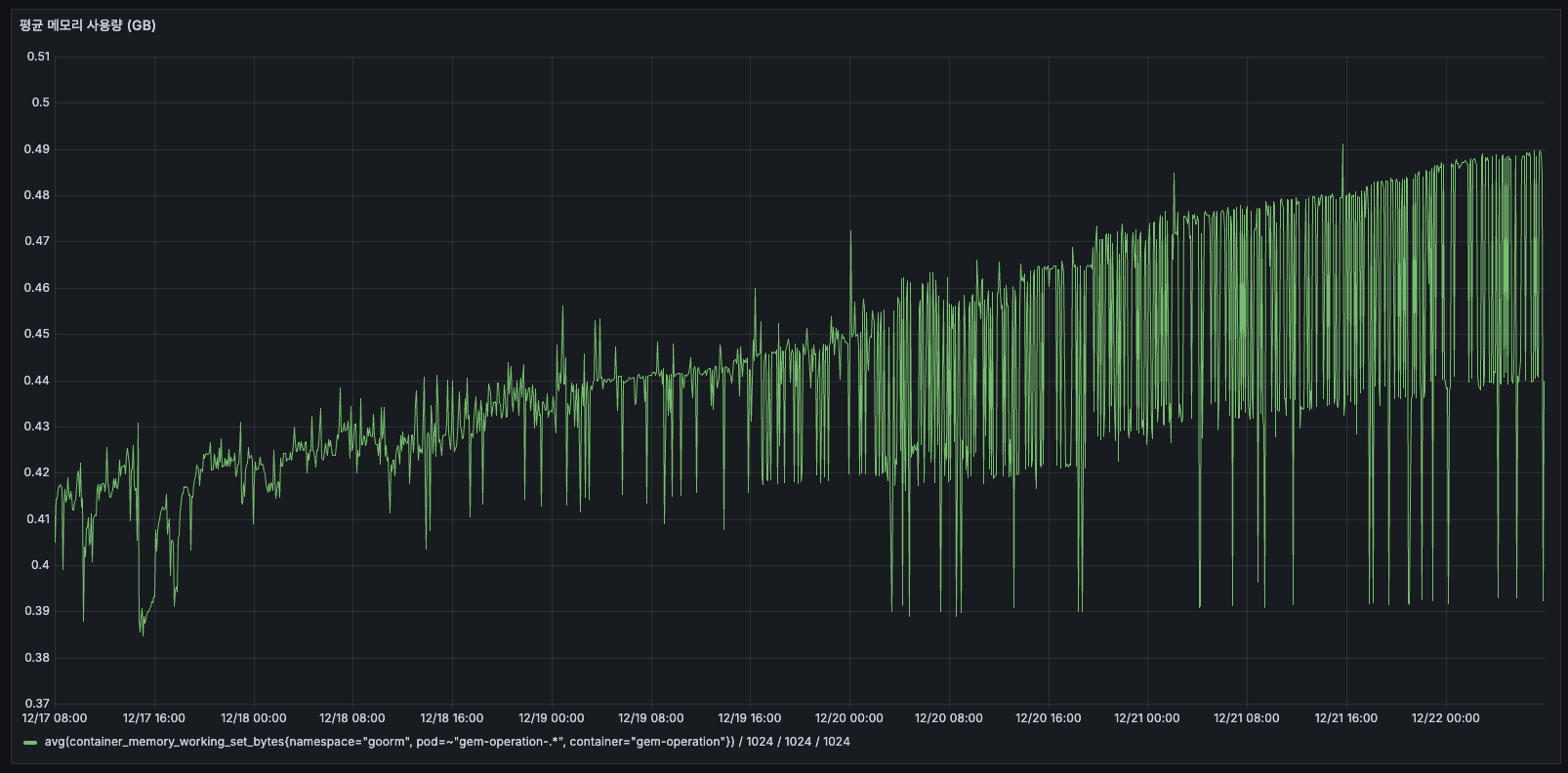
- 약 0.4GB 수준이지만, 계속해서 우상향하고 있음
최대 메모리 사용량
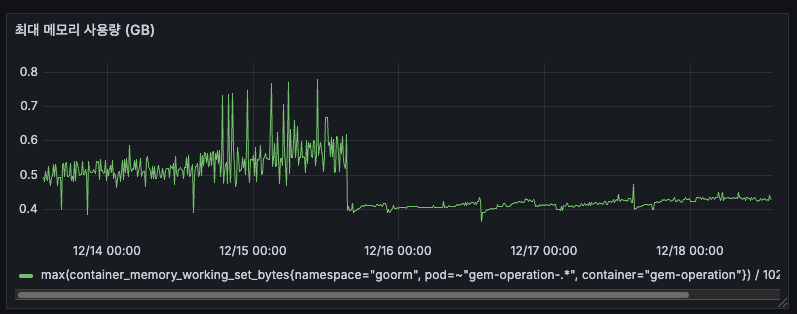
- 12/14 ~ 12/15: 최대 0.7GB까지 튐 (스파이크)
- 12/16 이후: 최대 0.5GB로 안정화 (배포 이후)
평균은 0.4GB인데, 0.5GB까지 올라가며 GC 하기 전 메모리를 축적하고 있습니다.
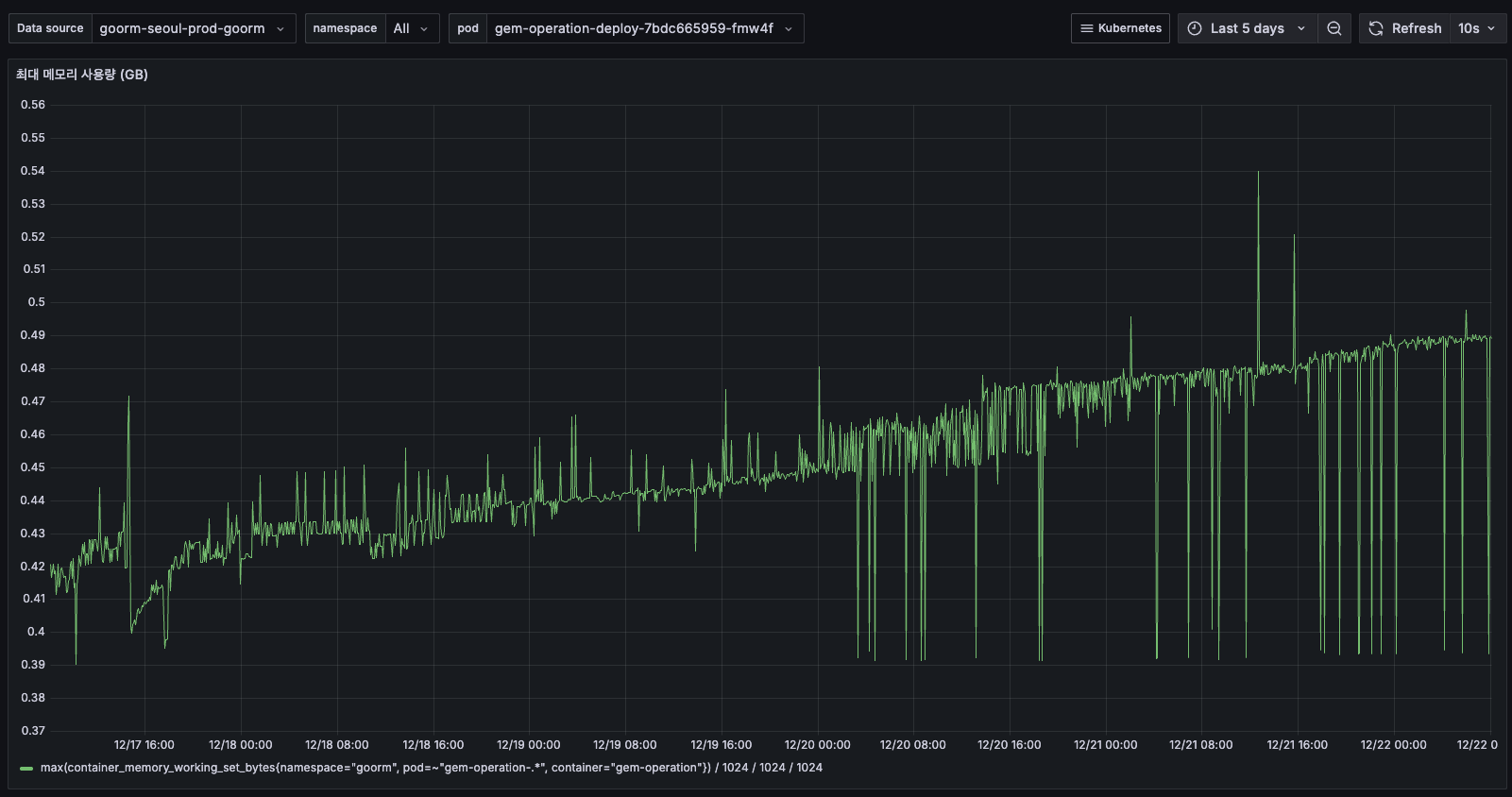
- 정말 작은 수치이지만 이후 5일간 최대 메모리 사용량이 지속적으로 증가하여 0.54GB까지 도달했습니다. 평균 메모리와 함께 상승하는 패턴으로 보아, 메모리 누수가 있는지 한번 확인을 고려해볼만합니다.
메모리 사용량
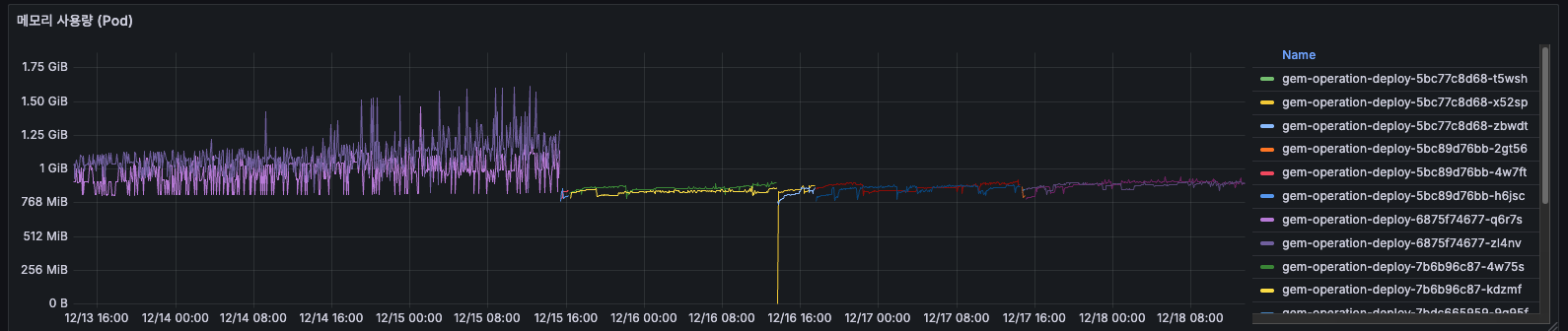
- 12/14 초반: 약 1GiB 사용 (여러 Pod 합산)
- 12/16 12:00 이후: 배포로 인해 Pod 전체 교체 후 갑자기 0으로 떨어짐
- 구 Pod: 1~1.5 GiB 사용
- 신 Pod: 0.75~1 GiB 사용
- 약 25~33% 메모리 감소
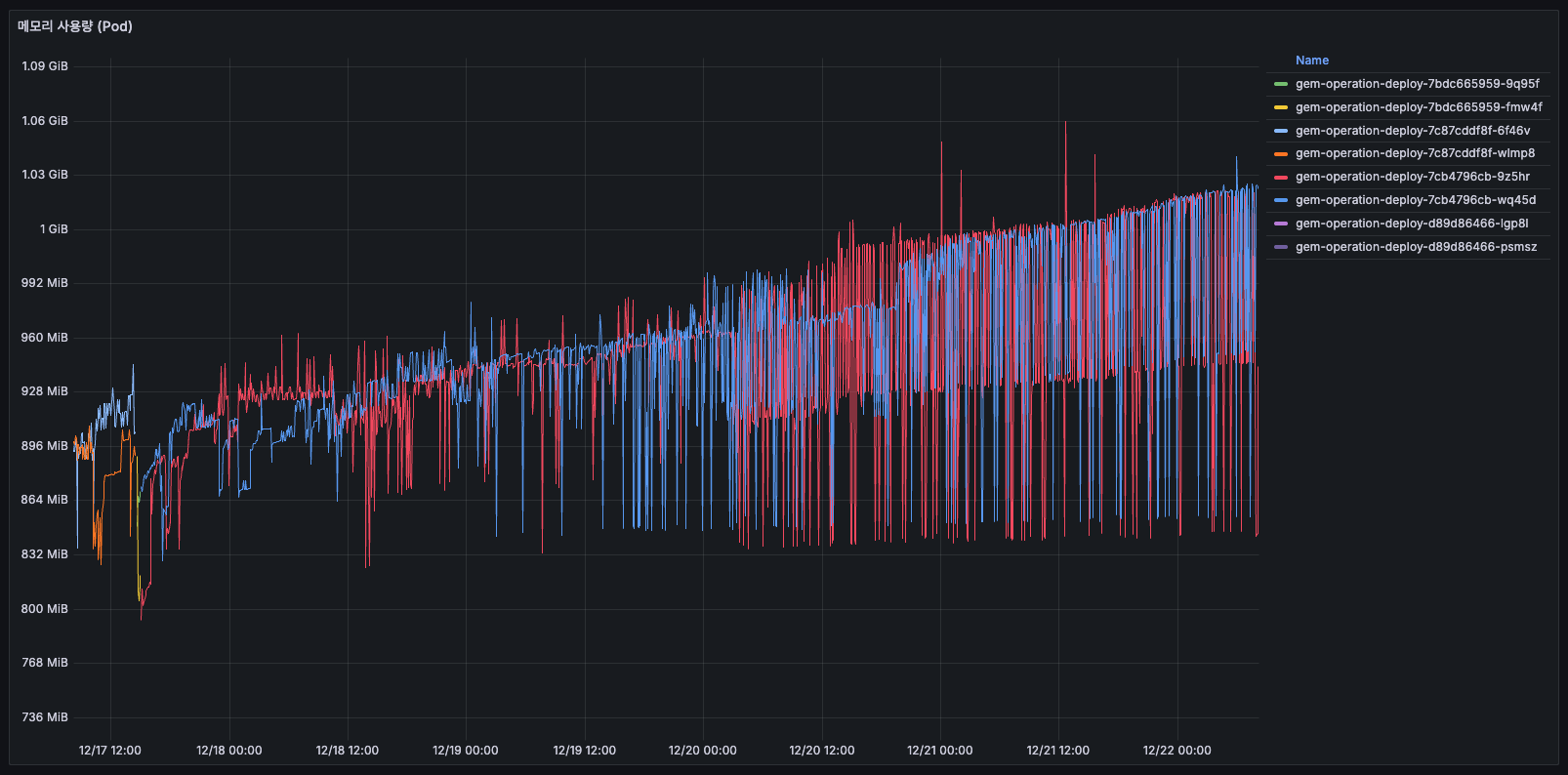
- 사용량이 이후 5일간 25% 증가(800MiB→1GiB)했고, 우상향 하고 있어 메모리 누수가 의심됩니다.
배포 이후 메모리가 줄어든 원인?
- 메모리 leak 있었는데, 시간 지나면서 쌓였다가 재시작으로 리셋
- 구 Pod가 오래 돌면서 데이터 캐시 쌓였음
메모리 누수 개선 작업이 없었고 서버가 교체되면서 임시적으로 해결된 것입니다. 그래서 향후 3일~5일간 배포하지 않고 메모리 상태를 추가적으로 확인 해보았습니다. 지켜보았을 때 계속 메모리가 늘어난다면, 메모리 누수가 난다고 판단할 수 있어 보여요.
이대로 갔을 때 OOM이 발생할 가능성?
우선 파드 스펙을 고려해보겠습니다.
- Request: 2GB
- Limit (최대 허용): 4GB
- -실제 사용: 최대 ~0.5GB
- Request 대비 사용률: 약 25%
- Limit 대비 사용률: 약 12.5%
사실 OOM이 발생할 정도로 메모리는 전혀 문제 없고, 남아도는 스펙이라서, 문제는 없습니다. 하지만 메모리를 효율적으로 사용하지 못하고 있는 것은 맞습니다.
CPU
CPU 사용량 (Pod)
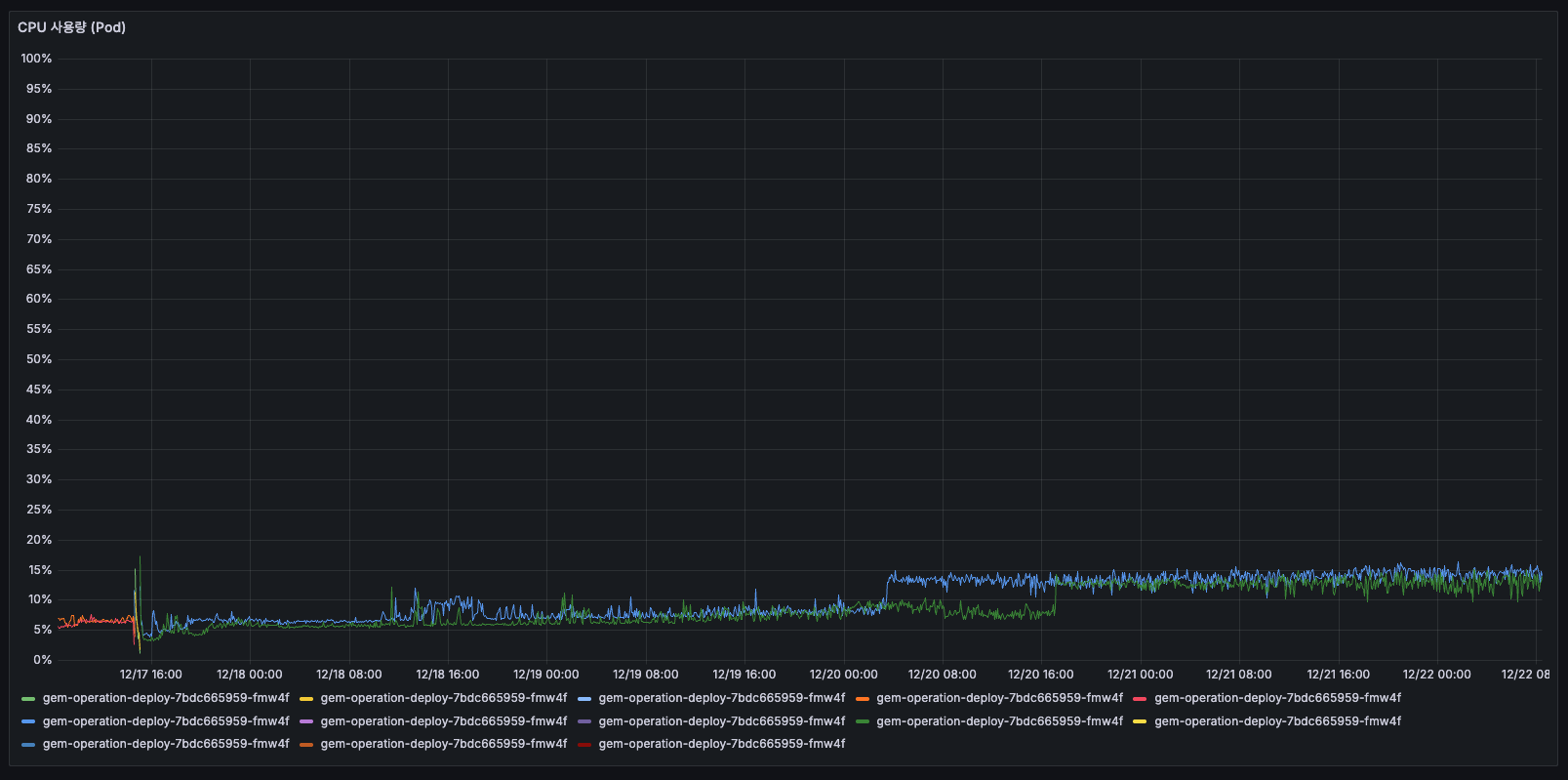
5일간 Pod CPU 추세
- 기존 모든 Pod가 15% 이하

Pod CPU 사용률이 5일간 30%~40%까지 2배 정도 변화했습니다. 모든 Pod에서 동시에 상승하는 패턴이긴 하지만, 절대값 자체는 서버가 에러가 날 수준은 아닙니다.
정리하면, CPU 사용량의 우상향에는 여러 원인이 복합적으로 작용할 수 있습니다. 메모리 누수로 인한 GC 빈도 증가, 배치 작업의 누적, 그리고 배포 시점에 따른 변화 등이 함께 영향을 줄 수 있어요. 물론 현재 서버 자원으로 충분히 감당 가능한 수준이지만, 이왕이면 리소스를 효율적으로 활용하는 것이 바람직하기 때문에 메모리 누수 해결과 함께 배치 설계도 함께 점검해보려고 합니다.
패킷
패킷 전송률
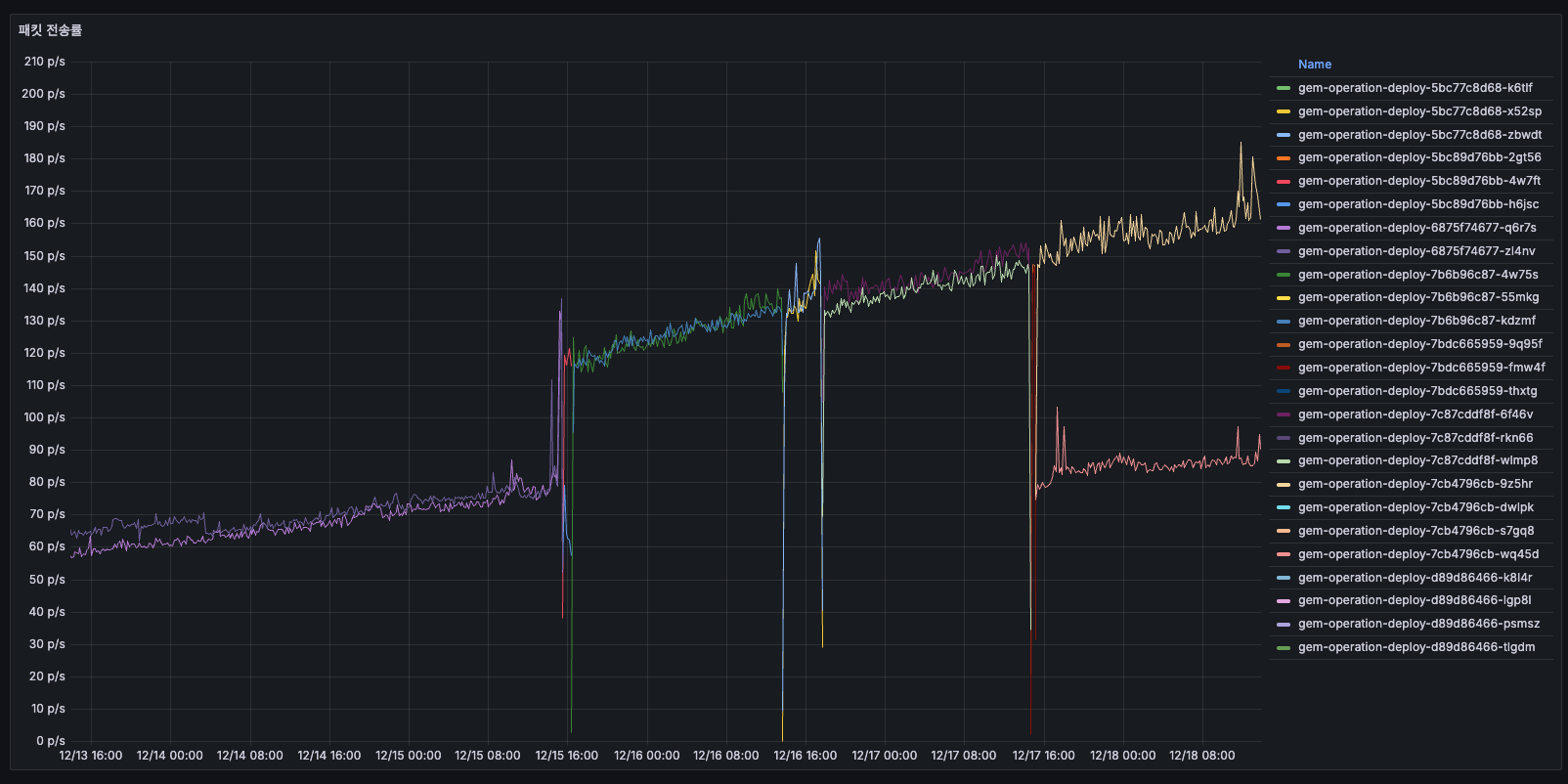
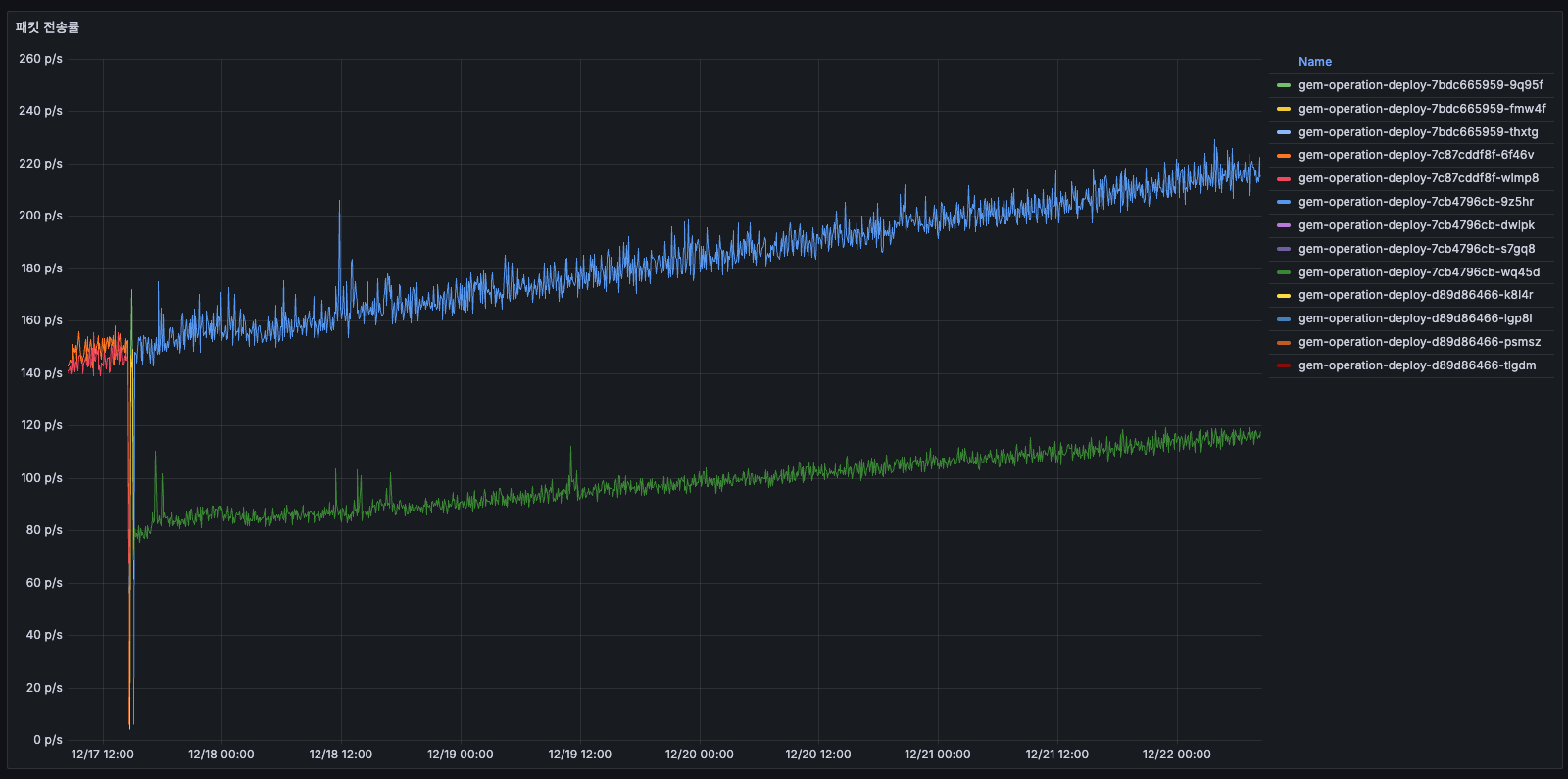
- 12/14 초반: 약 50~60 p/s
- 12/15: 점진적 증가 → 100~150 p/s
- 12/16 배포 이후: 75~100 p/s로 안정화
패킷 전송률의 증감은 배치 작업의 주기적 패턴이나 자연스러운 트래픽 변동에 의한 것으로 보이며, 이 수치 자체가 독립적인 문제는 아닙니다.
패킷 수신률
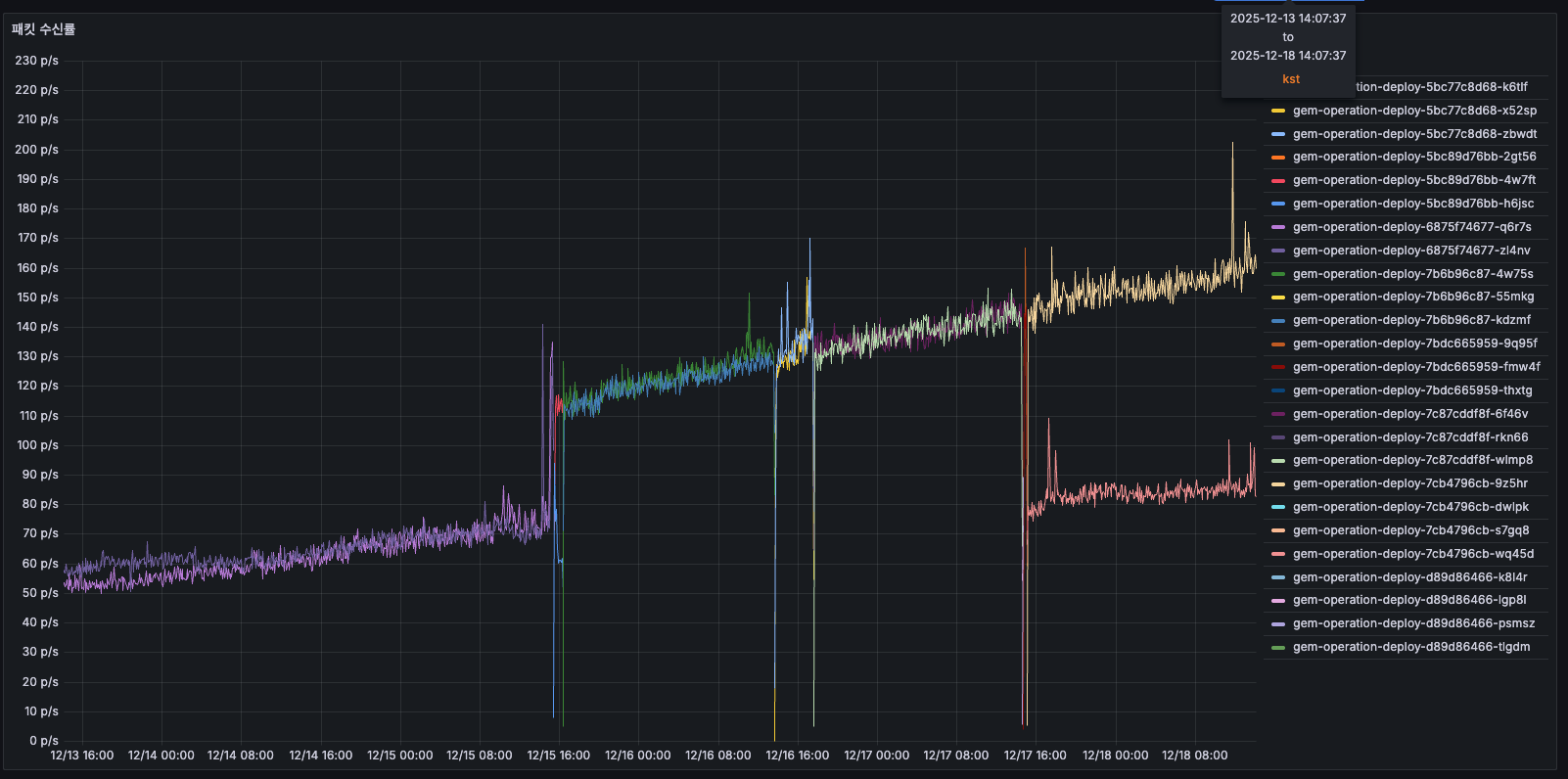
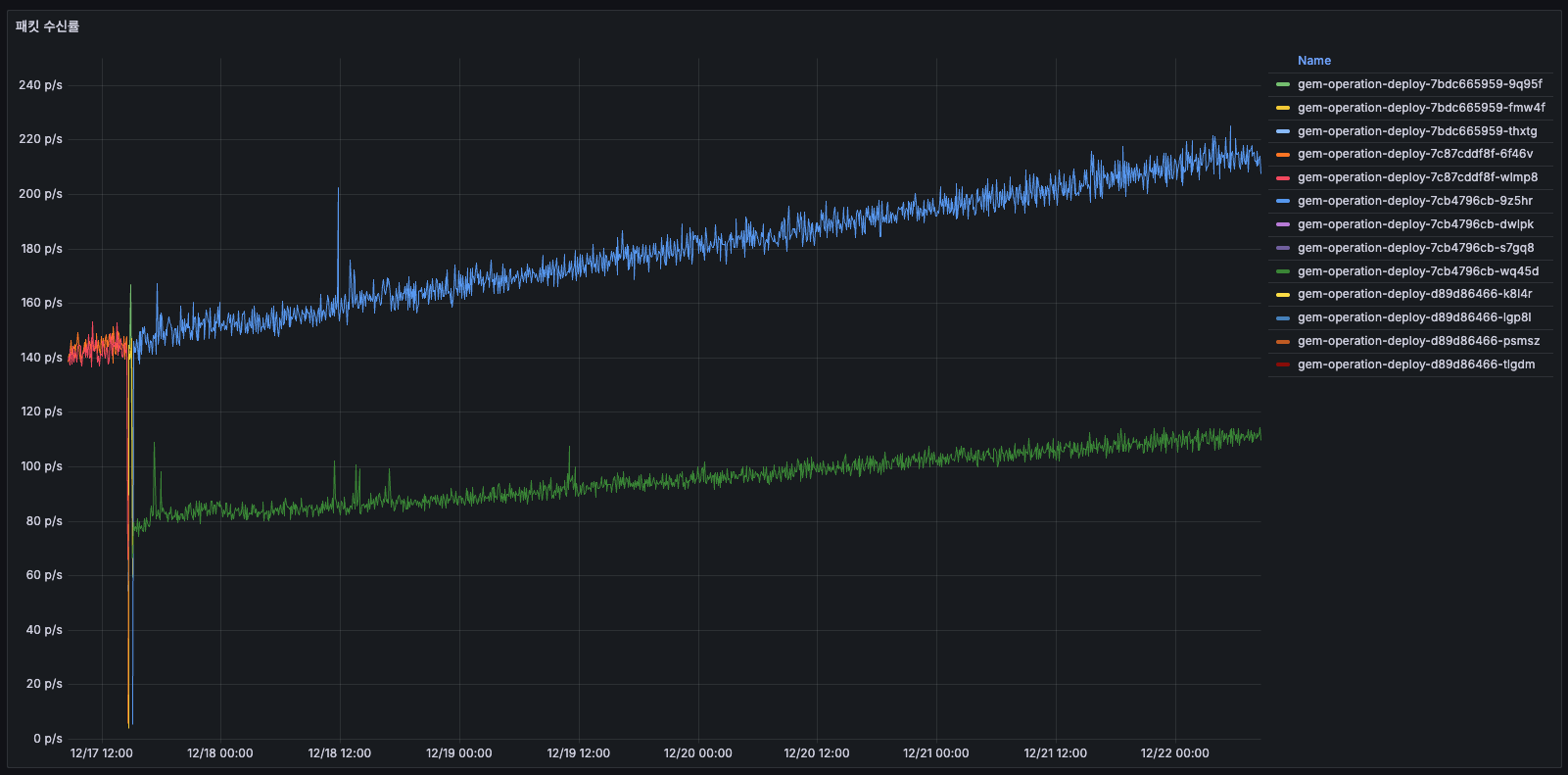
- 12/14: 약 50 p/s
- 12/15~12/16: 증가 → 150~175 p/s (3배 증가!)
- 12/16 배포 후: 감소
- 간헐적인 큰 스파이크 존재
- 수신 패킷도 시간에 따라 3배 증가 같은 패턴 반복
전송 패킷 드롭률
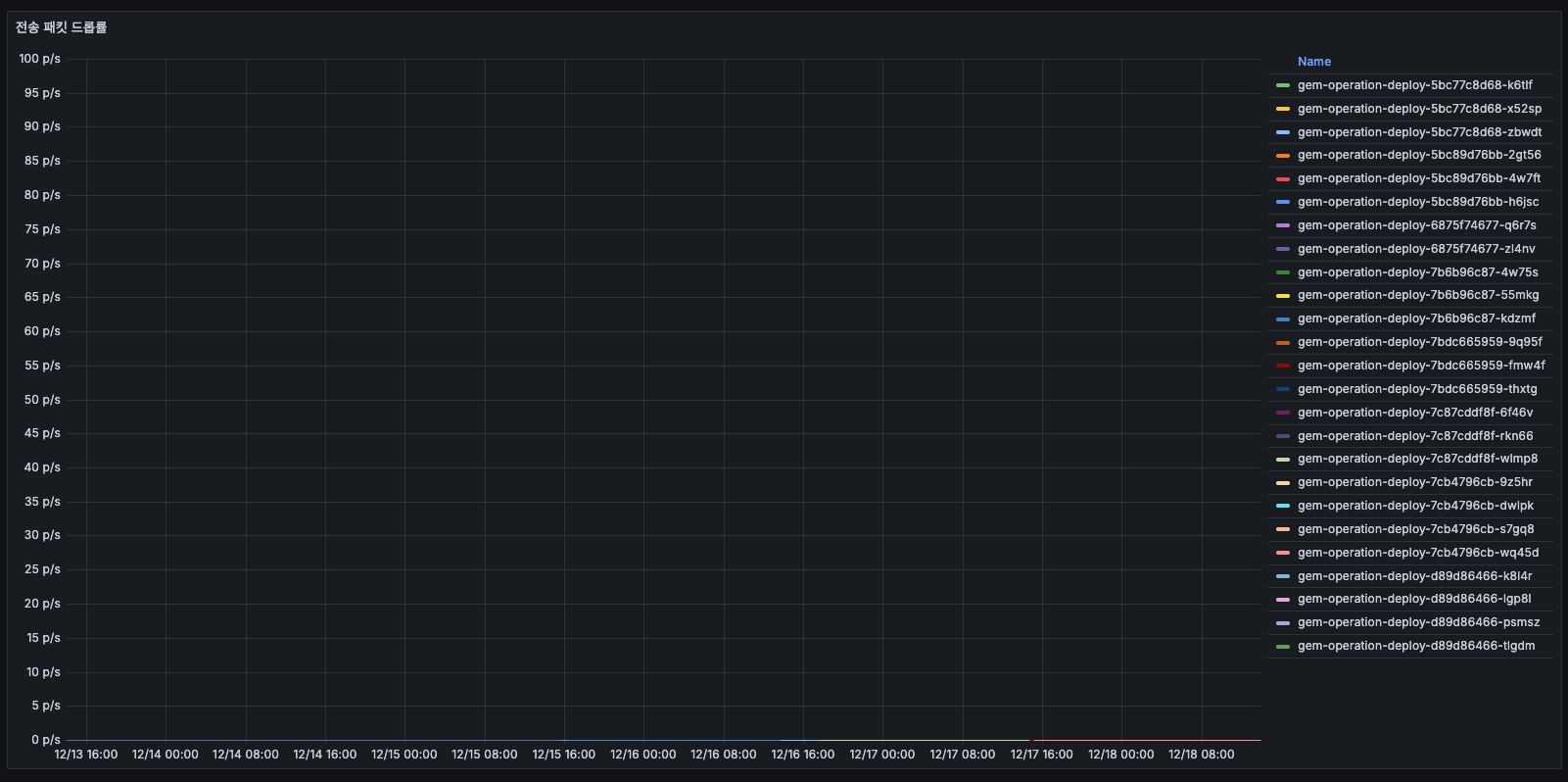
전송 패킷 드롭률
- 거의 0 p/s으로, 드롭된 패킷이 거의 없습니다.
- 네트워크 레벨에서는 문제 없으며, 패킷 손실 없이 정상 전송 중이라고 보면 될 것 같습니다.
수신 패킷 드롭률
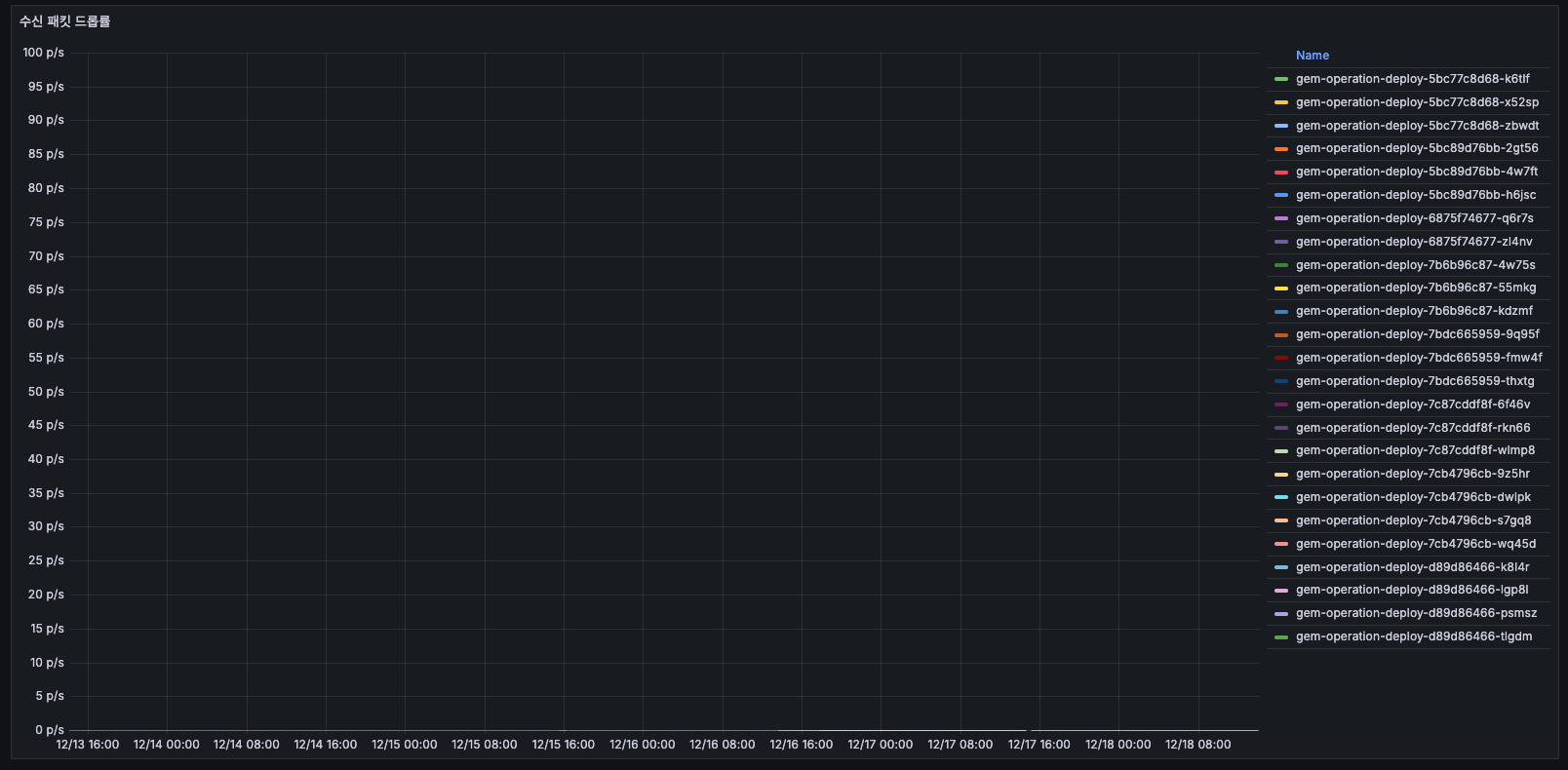
수신 패킷 드롭률
- 전송 패킷 드롭률 그래프와 유사. 드롭된 패킷이 거의 없습니다.
대역폭
수신 대역폭
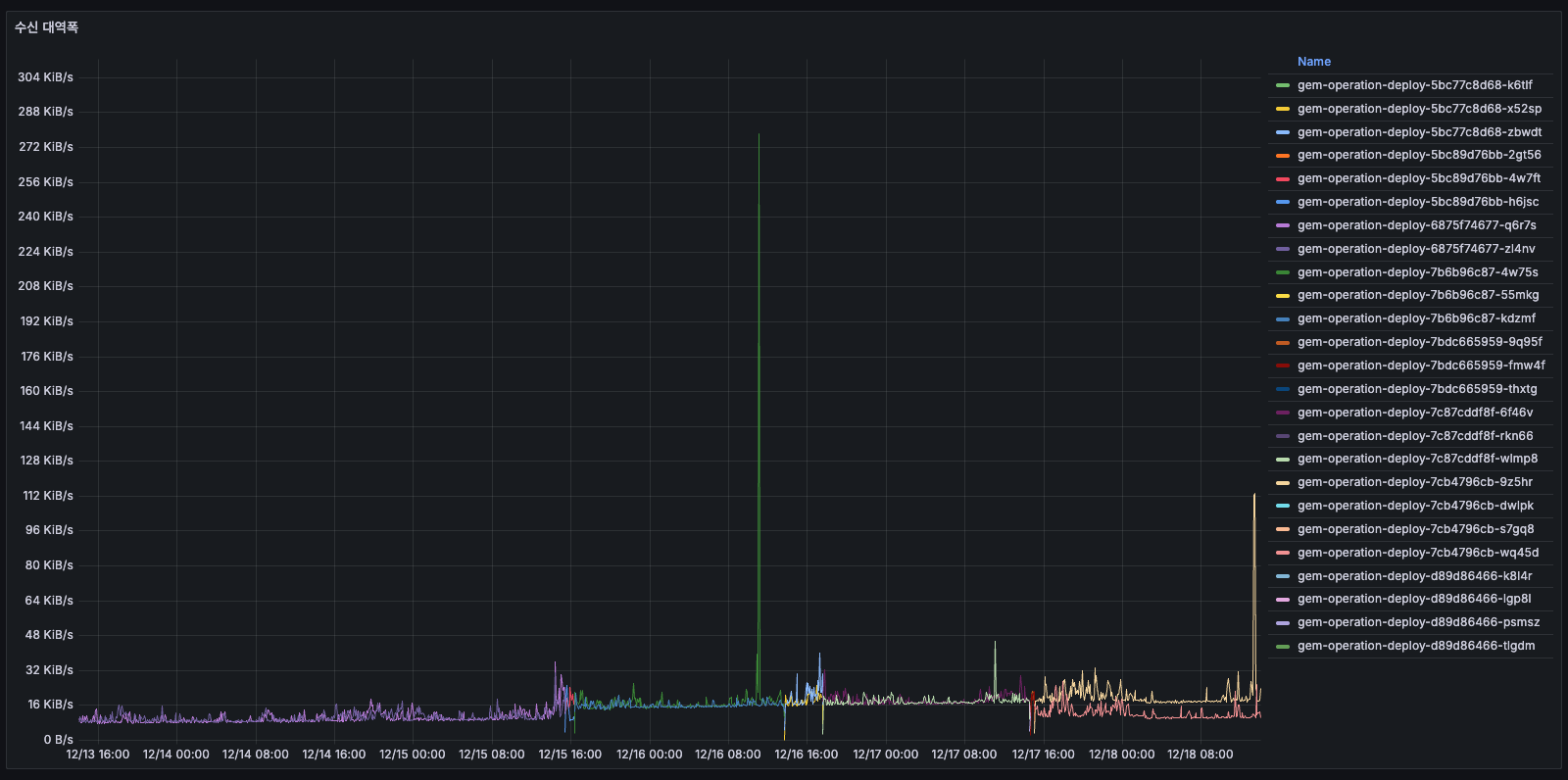
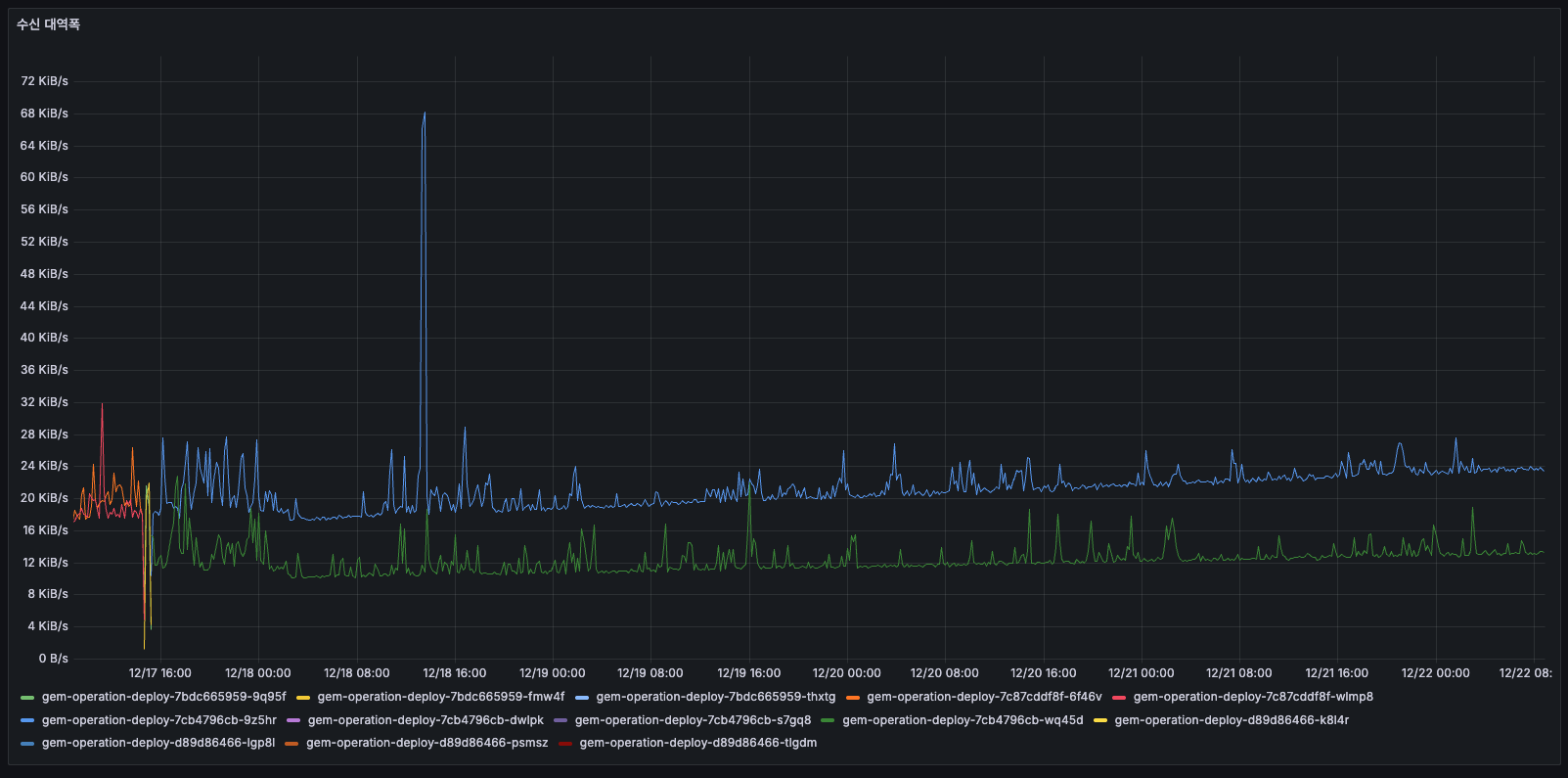
- 거의 0에 가까움
- 수치가 상대적으로 높았을 당시에는 모집 마감등의 이벤트가 있어서 어느정도 데이터를 수신 했던 것 같습니다. (그래도 작은 수치이다)
전송 대역폭
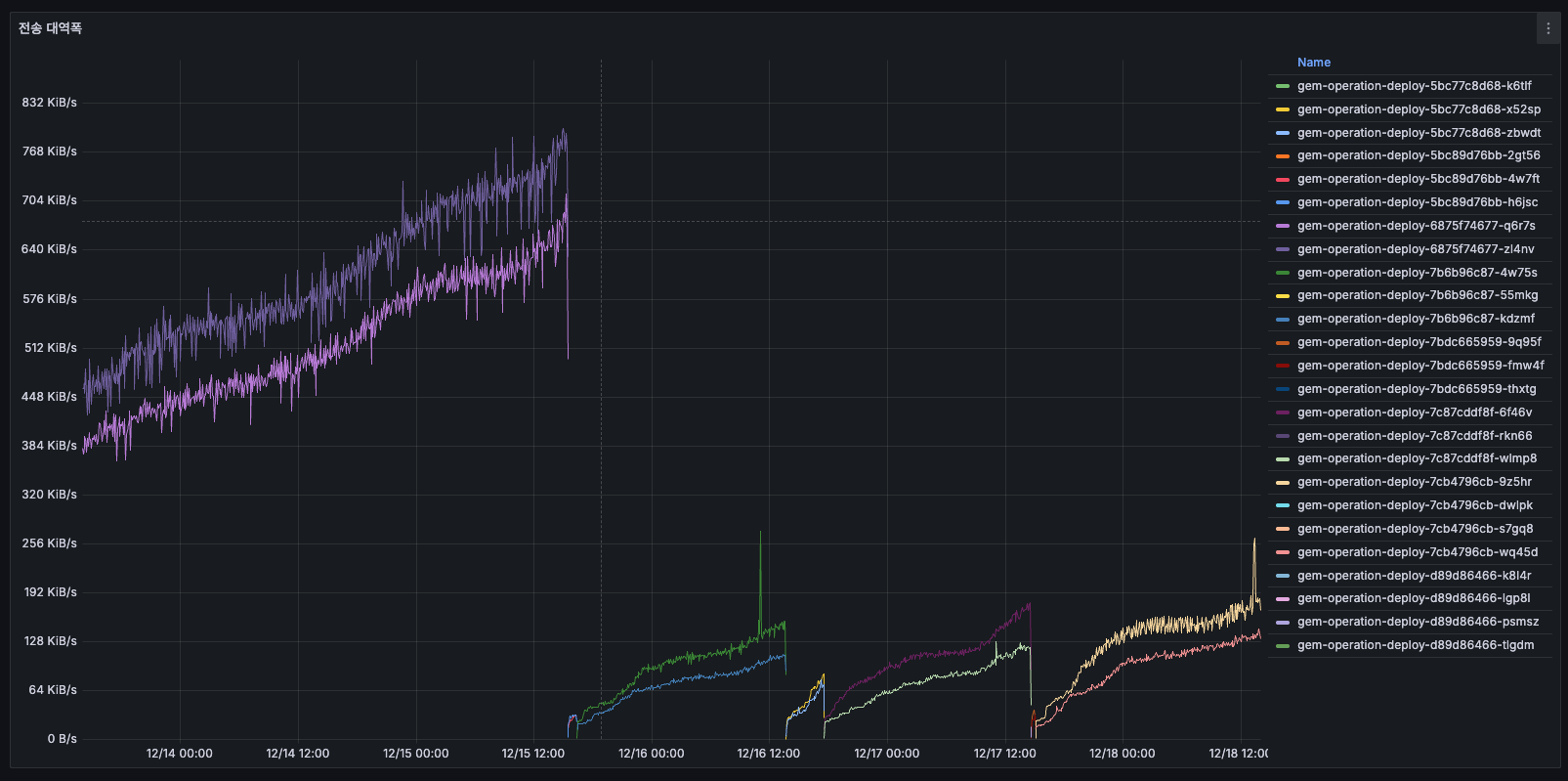
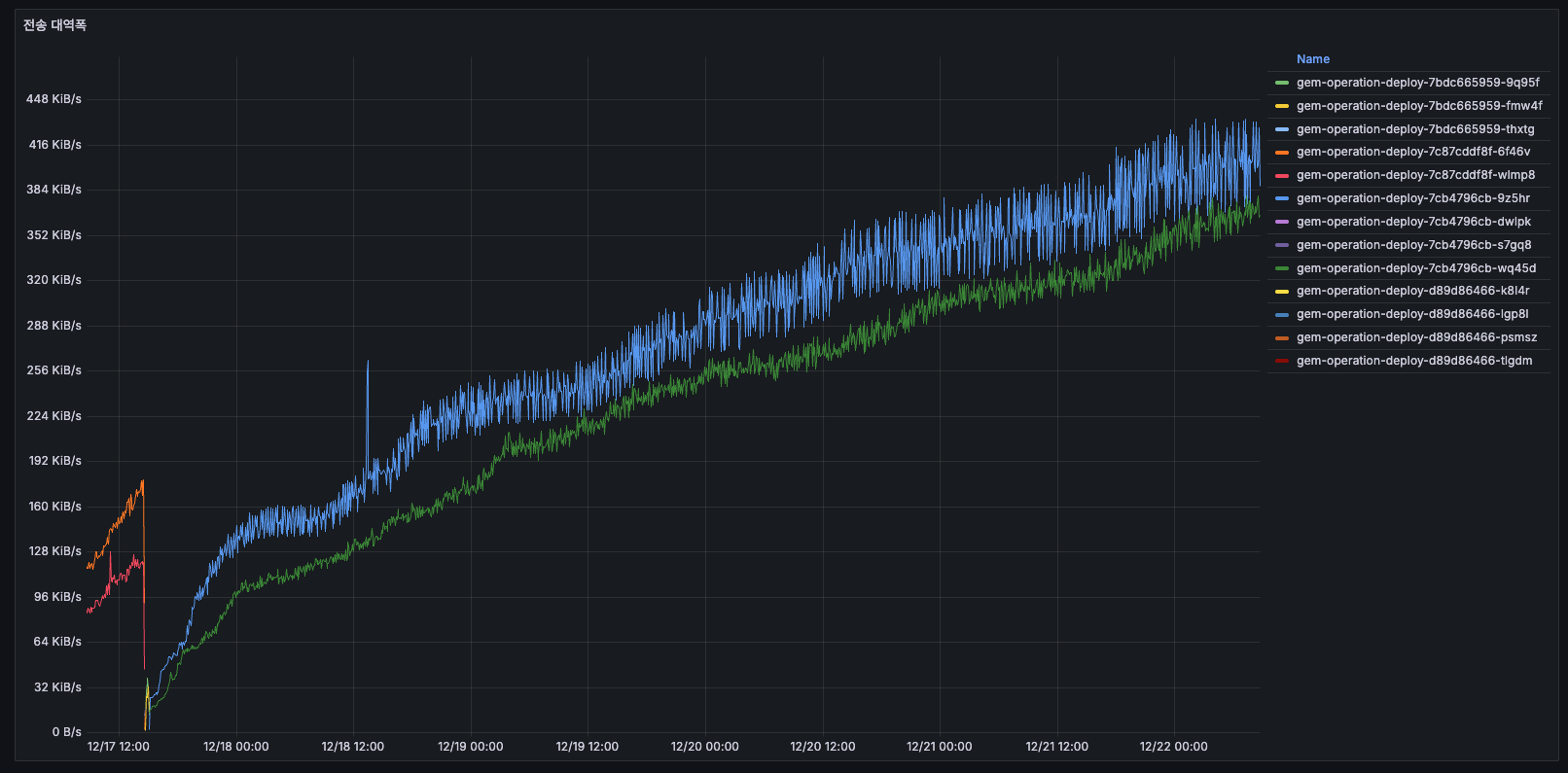
- 12/14 초반: 약 384 KiB/s
- 12/15: 계속 증가 → 768 KiB/s 이상 (2배)
- 12/16 배포 후: 약 384 KiB/s로 리셋
384 KiB/s라는 절대값 자체는 병목이 될 수준이 아닙니다. 하지만 주목할 점은, 트래픽(초당 1.1건)은 변하지 않았는데 대역폭이 2배로 증가했다는 것입니다. 이는 유저 트래픽이 아닌, 서버 내부에서 발생하는 불필요한 네트워크 I/O(배치 작업의 외부 API 호출, Redis 통신 등)가 시간이 지남에 따라 누적되고 있다는 신호로 볼 수 있습니다. 배치 설계를 점검할 때 함께 확인해볼 지표입니다.
그리고 우리 애플리케이션에서 수신 대역폭 대비 전송 대역폭이 이렇게 높은 이유도 함께 생각해봐야 합니다. 비동기 큐를 통해 주기적으로 Google Sheet API나 SES 같은 외부 API를 호출하고 있어서, 이 부분이 주요 원인일 가능성이 높다고 의심하고 있습니다.
Grafana 분석을 통해 알 수 있는 가능한 원인들
지표를 종합하면, 핵심 문제는 메모리의 지속적인 우상향입니다. CPU, 패킷, 대역폭도 함께 올라가는 패턴이 보이지만, 초당 1.1건의 트래픽에서 절대값 자체가 매우 낮아 독립적인 문제로 보기 어렵고, 메모리 누수에 따른 부수적인 증상(GC 빈도 증가, 누적된 데이터의 네트워크 전송 등)으로 판단됩니다.
근본 원인은 지표만으로는 알 수 없고 누수를 발생시키는 코드를 탐색해야 합니다. 저희 시스템 구조를 고려하여 유추하면 아래와 같은 후보들이 있습니다.
- 로그
- 외부 로깅 시스템(ELK, Datadog 등)으로 전송
- 로그 직렬화로 인한 CPU 증가
- 배치 작업 추가/증가, 잘못된 설계
- 주기적인 외부 API 호출
- 데이터 큐 작업
- 메일 / 알림 발송
- 메트릭 수집
- Prometheus exporter 추가
- 메트릭 전송 빈도 증가
4. Elastic APM 확인
Transactions
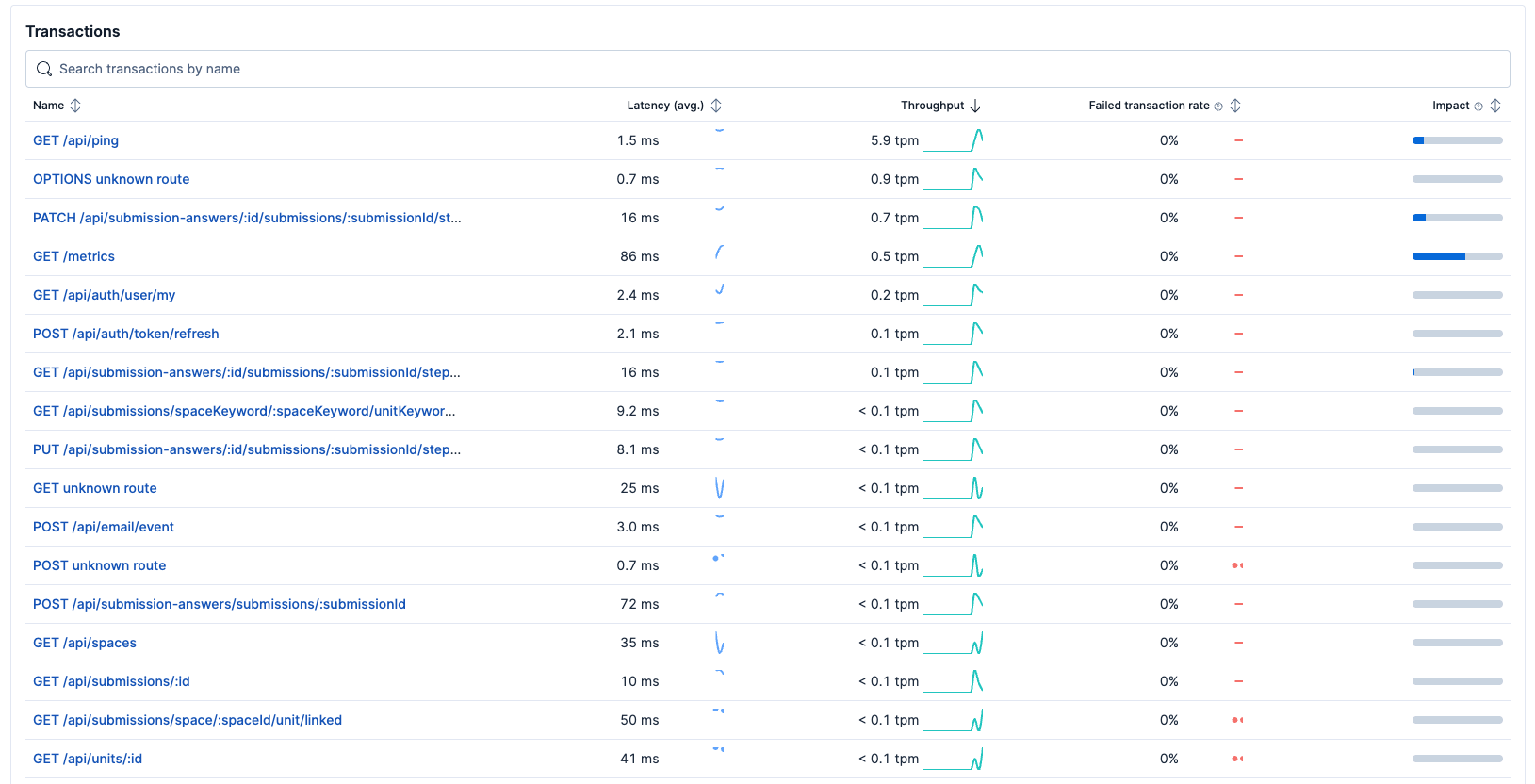
APM Transactions
주요 API 호출
- GET /api/ping (5.9 tpm)
해당 API는 Kubernetes 등의 Ingress의 헬스체크 프로브로 10초마다 1회 호출되는 정상 패턴입니다. 실제 유저 수준의 트랜잭션이 아니며, 시간에 따른 변화가 없어 리소스 사용 모니터링 대상에서 제외했습니다.
- OPTIONS unknown route (0 tpm)
해당 API는 브라우저에서 CORS preflight 요청으로 발생하는데, NestJS 라우터에서 매치되지 않는 경로이므로 빈번히 호출되지 않습니다. 1분당 0회로 매우 미미한 호출 수준입니다.
- PATCH /api/submission-answers/:id/submissions/:submissionId/steps/:step/question/:questionId (0.7 tpm)
해당 API는 위에서 언급한 두 개의 API를 제외한 가장 tpm이 높은 API입니다.
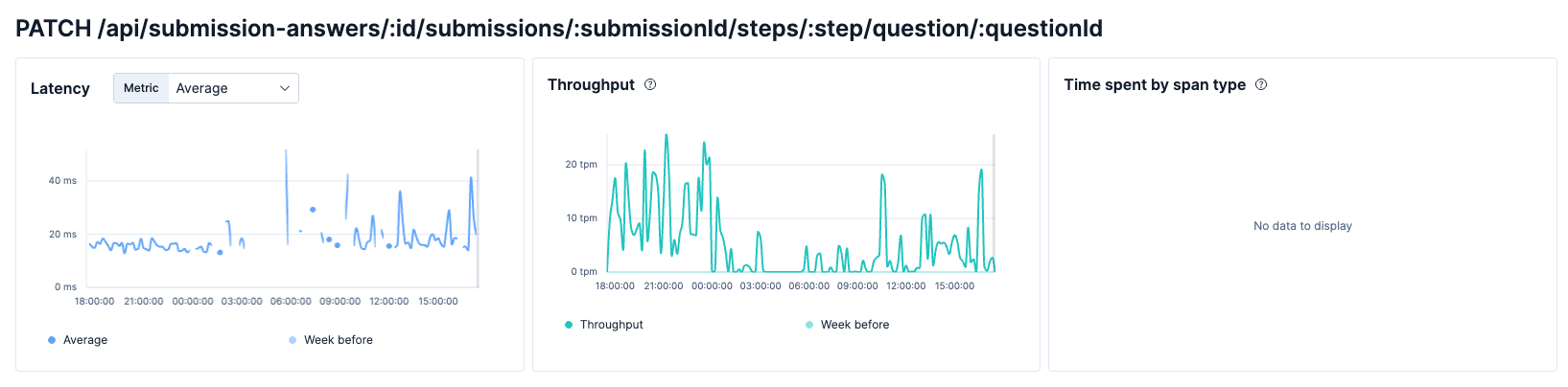
특정 API 상세
많을 때는 최대 26 tpm까지 올라가기도 했는데, 이 수치들은 "유효하지 않은 문항입니다"라는 에러가 예상치 못하게 발생하고 호출되는 경우들이 포함되어 있습니다.
사실 이 에러는 어떤 설문조사나 지원서의 특정 단계 + 특정 문항에 세팅되어 있는데, 없는 고유 id 조합으로 요청이 가서 에러가 발생하는 것입니다. 특정 호출이 계속 반복되고 있어서, 이러한 호출을 하는 FE 코드 수정이 필요해 보입니다.
- GET /api/submission-answers/:id/submissions/:submissionId/steps/:step
해당 API는 위에서 언급한 세 개의 API를 제외한 가장 tpm이 높은 API입니다.
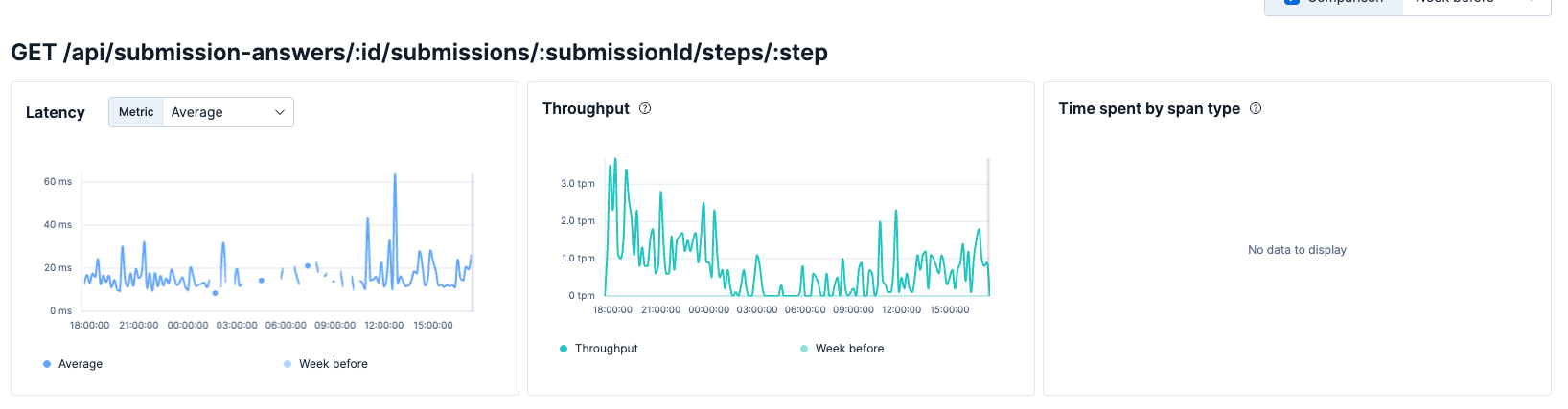
특정 API 상세
하지만 tpm이 그렇게 많지도 않고 latency도 느리지 않고 빠르기 때문에 크게 문제되는 API로 보이지 않습니다.
결국 API는 문제가 아닌것으로 보인다. 진짜 문제는 무엇일까?
API 트랜잭션은 매우 적고 (대부분 < 0.1 tpm) 에러율도 0%입니다. 그라파나에서 메모리가 지속적으로 증가하고 있지만, APM 상 API 호출 수 자체가 거의 없어서 유저 트래픽이 원인은 아닙니다.
그 원인에 대해서는 서버가 받는 API가 아니니 서버에서 외부를 호출하는 것이라고 판단이 됩니다만, APM 데이터로는 외부 호출 여부를 판단할 수 없었습니다.
그래서 현재로서는 판단하기 어려워, 이 이외의 다른 지표를 조금 더 살펴보기로 했습니다.
5. Grafana에 NodeJS 지표 추가
우선 그라파나를 잘 활용하기로 하였고, NodeJS 기본 지표들을 더 분석하여 메모리 관련 문제를 더 확인해보려고 합니다.
NodeJS Event Loop 지연
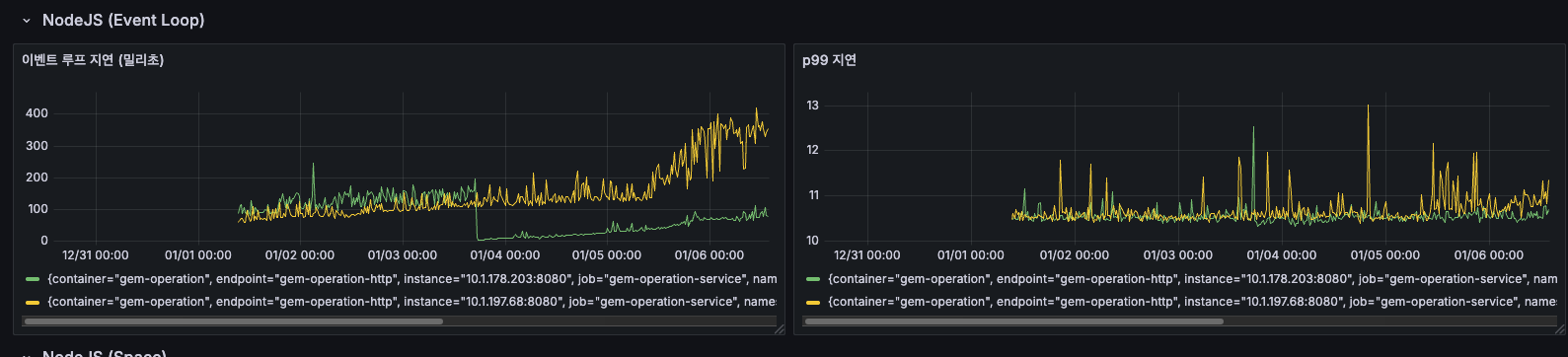
NodeJS Event Loop 지연 분석
이벤트 루프 지연 (밀리초)
- 12/31 ~ 01/04: 약 100~150ms로 안정적 유지
- 01/05 00:00 이후: 급격히 증가하여 150~250ms로 상승
- 01/06: 최대 400ms까지 스파이크 발생
- 노란색 인스턴스가 특히 높은 지연을 보임
이벤트 루프 지연이 급증하면 요청 처리가 지연되고, API 응답 시간이 느려지는데요, 01/05 이후 급격한 증가는 특정 배치 작업이나 외부 API 호출 증가가 원인일 가능성이 있습니다.
p99 지연
- 전체 기간 동안 10~13ms로 매우 안정적
- 간헐적인 스파이크만 존재 (최대 13ms)
- 대부분의 요청은 11ms 이내에 처리됨
- p99 지연은 안정적이지만, 평균 이벤트 루프 지연이 높다는 것은 일부 무거운 작업이 이벤트 루프를 블로킹하고 있다는 신호로 보입니다.
NodeJS Heap 메모리
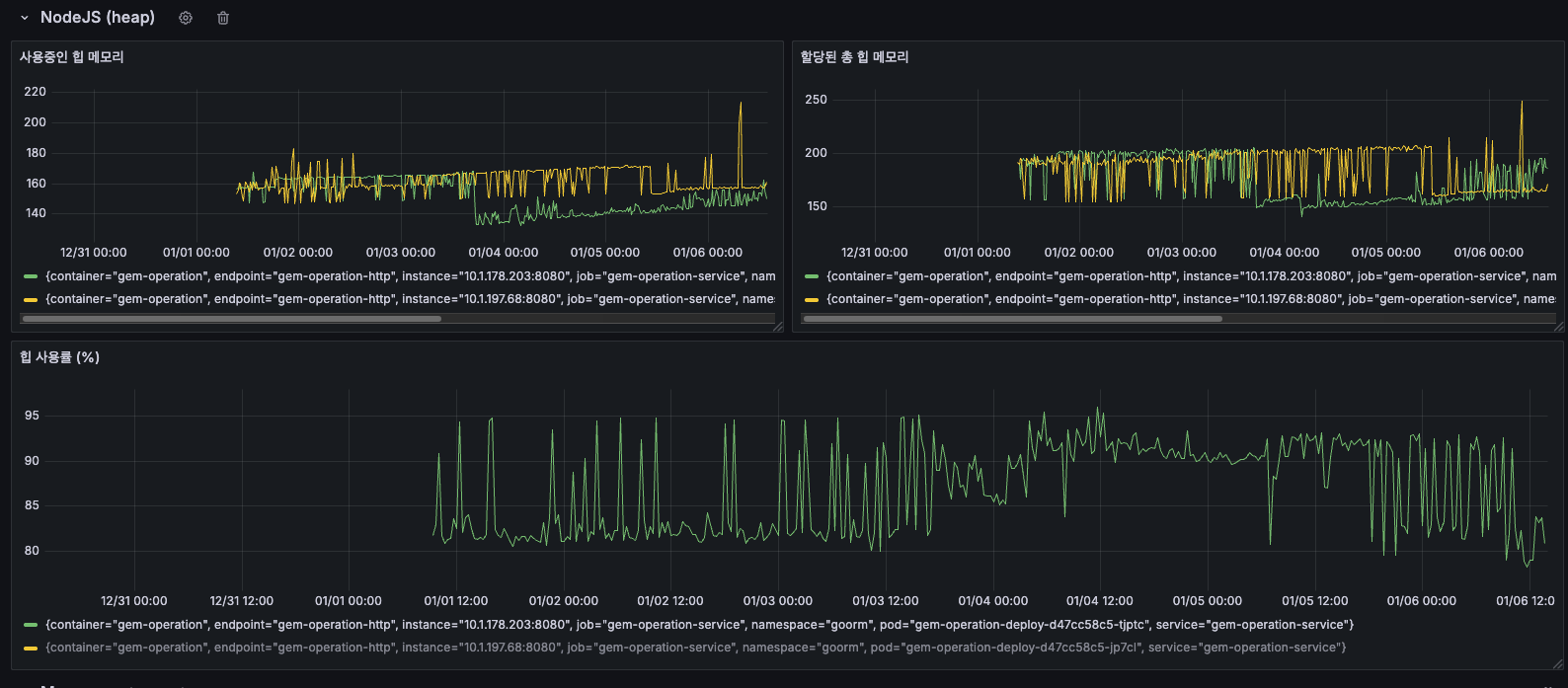
NodeJS Heap 메모리 사용 패턴
사용중인 힙 메모리
- 12/31 ~ 01/02: 약 150~165MB로 안정적
- 01/03 이후: 점진적으로 상승하여 160~180MB 유지
- 01/06: 최대 220MB까지 스파이크 발생
- 지속적인 상승 추세가 관찰됨
할당된 총 힙 메모리
- 12/31 ~ 01/04: 약 150~200MB
- 01/05 이후: 200~250MB로 증가
- 01/06: 최대 250MB까지 도달
- 사용중인 힙과 유사한 패턴으로 증가
할당된 총 힙이 증가한다는 것은 V8 엔진이 더 많은 메모리를 필요로 한다고 판단했다는 의미로, 이는 실제로 메모리 사용량이 증가하고 있음을 나타내고 있습니다.
힙 사용률 (%)
- 대부분의 시간: 85~95% 유지
- 주기적인 하락 패턴: GC(Garbage Collection) 실행 시점
- 01/01 이후: 80~95% 사이에서 톱니 패턴 반복
85%가 많아보일 수 있지만, 전체 최대 힙 크기는 4096MB 이상이기 때문에 장애가 나는 수준이 절대 아니고, 오히려 넉넉한 편입니다.
처음 혼동한 것이 있었는데, 지표에서 볼 수 있는 할당된 총 힙 메모리는 NodeJS 앱의 할당된 총 힙 메모리가 아닌, 그 시점에 OS로부터 할당받은 메모리입니다. 그래서 전체 사용량을 절대 넘어서지는 않습니다.
NodeJS Space
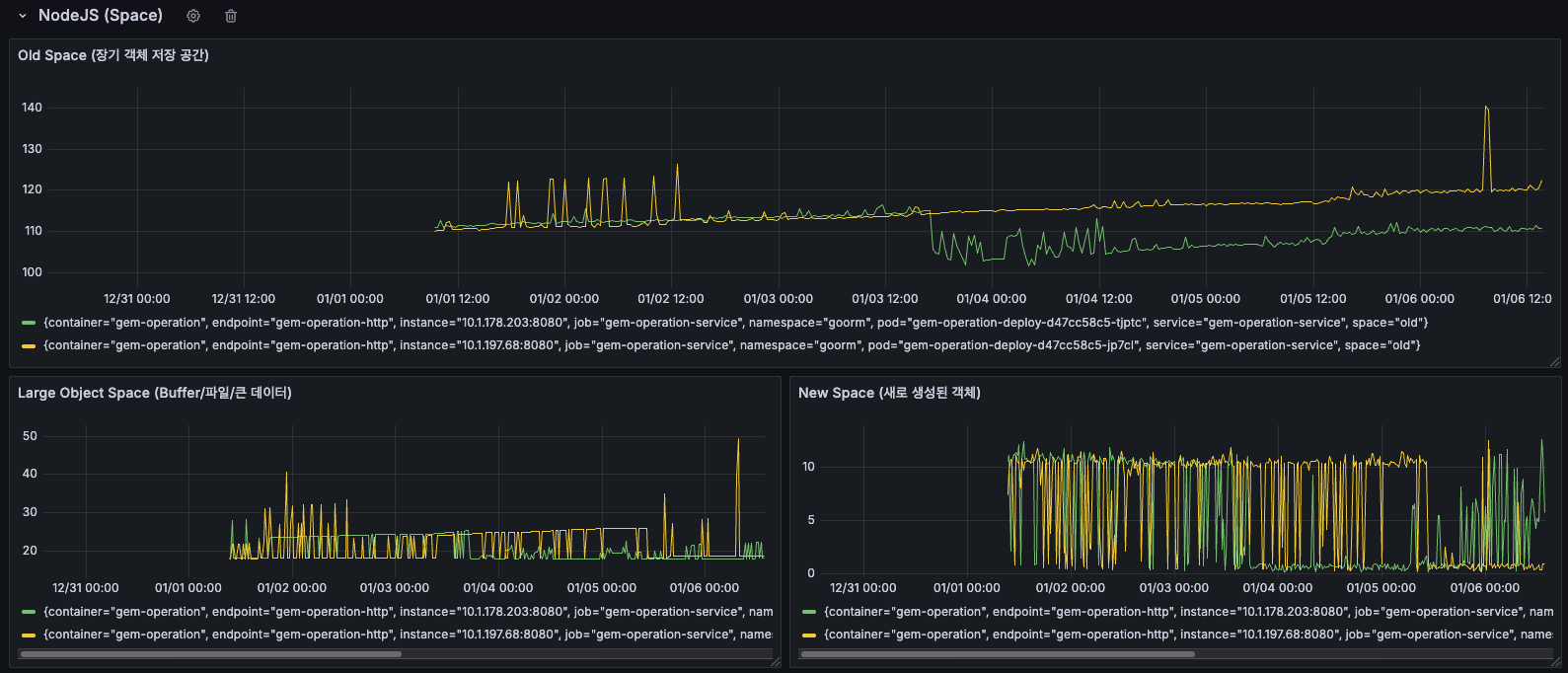
NodeJS Space 메모리 영역별 사용 현황
New Space Size (Young Generation)
- 좌측 하단 그래프를 보면, 노란색과 녹색으로 표시된 두 인스턴스의 New Space 크기를 확인할 수 있습니다.
- 전체 기간 동안 주기적인 톱니 패턴이 반복됨
- 01/05 이후: 스파이크가 더 자주 발생하고, 피크 값이 증가
- 우측 상단의 작은 그래프에서도 01/06 시점에 급격한 스파이크 확인
- New Space는 새로 생성된 객체들이 할당되는 영역입니다. 주기적인 톱니 패턴은 Minor GC(Scavenge)가 정상적으로 작동하고 있다는 의미이지만, 스파이크가 증가한다는 것은 새로운 객체 생성이 급증했다는 신호로 보입니다!
Old Space Size (Old Generation)
- 좌측 하단 그래프의 더 높은 선들이 Old Space를 나타냅니다.
- 12/31 ~ 01/04: 비교적 안정적
- 01/05 이후: 점진적 증가 추세
- 우측 하단 그래프에서도 여러 메트릭들이 시간에 따라 증가하는 패턴 확인이 됩니다.
Old Space는 Minor GC에서 살아남은 장수 객체들이 이동하는 영역인데요, Old Space가 지속적으로 증가한다는 것은 메모리에서 해제되지 않는 객체들이 계속 누적되고 있다는 의미로, 메모리 누수의 증거로 보입니다.
결론
-
이벤트 루프 지연 급증: 01/05 이후 2~4배 증가
- 무거운 동기 작업이나 블로킹 작업 증가 의심되고 있습니다.
-
힙 메모리 증가: 150MB → 220MB (최대 스파이크 기준, 약 46% 증가)
- 70MB 전체가 누수는 아니며, 누수로 인해 V8이 힙을 더 크게 할당하고 GC 전 임시 객체가 쌓이면서 피크가 높아진 것으로 보입니다. 다만 지속적인 우상향 추세 자체가 메모리가 정상적으로 회수되지 않는 부분이 있다는 신호입니다.
-
공간 관리 비효율: New Space 스파이크 증가, Old Space 증가 가속화
- New Space에서 생성된 객체들이 정상적으로 정리되지 않고 Old Space로 계속 승급되고 있으며, Old Space에서도 제대로 해제되지 않고 있습니다. 특정 객체에 대한 참조가 의도치 않게 계속 유지되고 있을 가능성이 있어보여요.
6. heap 지표를 확인하기 위한 설정과 추가를 해보자.
import { Controller, Get, Res } from "@nestjs/common";
import type { Response } from "express";
import { writeHeapSnapshot } from "v8";
import { createReadStream } from "fs";
import { unlink } from "fs/promises";
@Controller()
export class AppController {
constructor() {}
@Get("/debug/heap-snapshot")
async downloadHeapSnapshot(@Res() res: Response) {
const filename = writeHeapSnapshot();
res.setHeader("Content-Type", "application/octet-stream");
res.setHeader(
"Content-Disposition",
`attachment; filename="heap-${Date.now()}.heapsnapshot"`,
);
const stream = createReadStream(filename);
stream.pipe(res);
stream.on("end", async () => {
try {
await unlink(filename);
} catch (error) {
console.error(`[Heap Snapshot] Failed to delete file: ${error}`);
}
});
stream.on("error", (error) => {
res.status(500).send("Failed to download heap snapshot");
});
}
}
v8에서 제공하는 writeHeapSnapshot 메서드 덕분에 heapSnapshot 파일을 얻을 수 있었습니다. 해당 API를 임시로 베타 환경에 붙여서 다운로드 받고 확인해보겠습니다.
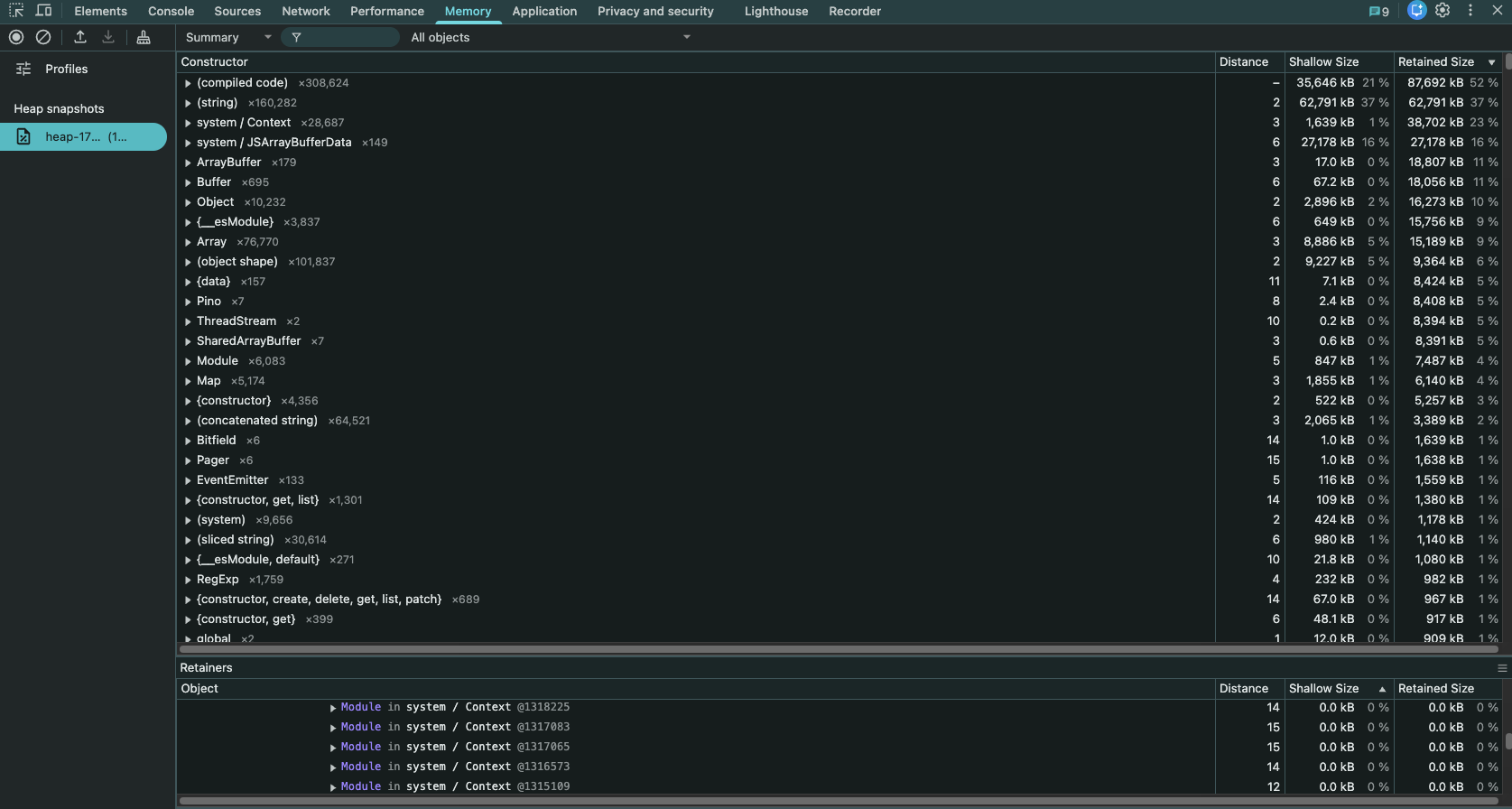
개발자 도구에서 Heap Snapshot 분석
개발자 도구의 Memory 탭을 활용해볼건데요, 해당 탭에 다운받은 heapSnapshot 파일을 업로드하면 됩니다.
과연?
string, system / context, JSArrayBufferData, ArrayBuffer 등 다양한 항목을 살펴보았는데, 그 중 하나 이상한 점을 발견했습니다.

개발자 도구에서 Heap Snapshot 분석
classValidatorMetadataStorage의 validationMetadatas 배열이 17,080개의 항목을 보유하고 있었습니다.
확인해보니.. class-validator 라이브러리가 내부적으로 관리하는 전역 메타데이터 저장소인데, DTO 클래스에 붙인 데코레이터(@IsString, @IsNotEmpty 등)의 메타데이터가 이 배열에 누적되더라고요.
왜 이렇게 많이 쌓이는가?
확인해보니 class-validator의 메타데이터는 전역 싱글톤(MetadataStorage)에 저장됩니다. 구조를 단순화하면 아래와 같습니다.
// class-validator 내부 구조 (단순화)
class MetadataStorage {
validationMetadatas: ValidationMetadata[] = [];
addValidationMetadata(metadata: ValidationMetadata) {
this.validationMetadatas.push(metadata); // 계속 push만 하고 정리하지 않음
}
}
DTO 클래스에 데코레이터를 하나 붙일 때마다 이 배열에 메타데이터가 추가됩니다. 여기서 핵심은, 저희 배치 스케줄러 코드에서 런타임에 PickType을 반복 호출하고 있었다는 점입니다.
// 문제가 되었던 패턴 (단순화)
@Interval('1min')
async processSheetBatch() {
const targetkeyList = await this.redisService.searchWithPatterns('sheet');
for (const targetKey of targetkeyList) {
queue.add(targetKey);
}
}
// 큐에서 가져와서 실행
@Processor()
async process() {
...
for (const parsedTarget of parsedTargetList) {
// 매 반복마다 PickType이 새로운 클래스를 생성하고
// MetadataStorage에 메타데이터를 복제 등록
const ValidateDto = PickType(SomeDto, ['name', 'id']);
await validate(new ValidateDto(), parsedTarget);
// 비즈니스 로직, google Sheet API 호출
}
}
NestJS의 PickType은 내부적으로 새로운 클래스를 런타임에 생성하고, 원본 DTO의 validation 데코레이터 메타데이터를 새 클래스에 복제 등록합니다. 이 스케줄러가 1분마다 실행되고, Redis에서 가져온 target 목록을 순회하면서 매 iteration마다 PickType을 호출하니, 실행될 때마다 MetadataStorage에 메타데이터가 끝없이 쌓이게 됩니다.
로컬에서 재현해보기
실제로 로컬에서 확인해보니, 앱 부팅 직후에는 10개가 쌓여 있었고, API를 호출할수록 이 숫자가 계속 증가하는 것을 확인할 수 있었습니다.
import { getMetadataStorage } from "class-validator";
const storage = getMetadataStorage();
console.log("부팅 직후:", storage.validationMetadatas.length);
// → 부팅 직후: 10
// API 호출 후
console.log("호출 후:", storage.validationMetadatas.length);
// → 호출 후: 17090 (계속 증가)
부팅 시점의 10개는 정적 DTO들의 메타데이터이고, 그 위에 런타임 동적 생성분이 계속 누적되고 있던 것이었습니다. 이것이 Grafana에서 관찰한 메모리 우상향의 원인 중 하나였습니다.
그렇다면 이것이 핵심 누수인가?
classValidatorMetadataStorage의 동적 생성은 확실히 시간에 따라 증가하는 메모리 누수의 원인 중 하나입니다. 다만 이것만이 유일한 원인이라고 단정짓기는 어렵습니다. Grafana 지표에서 확인한 메모리 우상향의 증가폭과, 이 메타데이터 누적의 증가폭이 정확히 일치하는지는 추가 검증이 필요하기 때문에 개선 후에 더 지켜보겠습니다.
7. 다시 한번, 현실적인 트래픽과 핵심 문제를 짚어보자
앞서 언급한 것처럼 저희 트래픽은 매우 낮습니다. 구체적으로, 하루에 약 93,288건이 호출되고 있습니다.
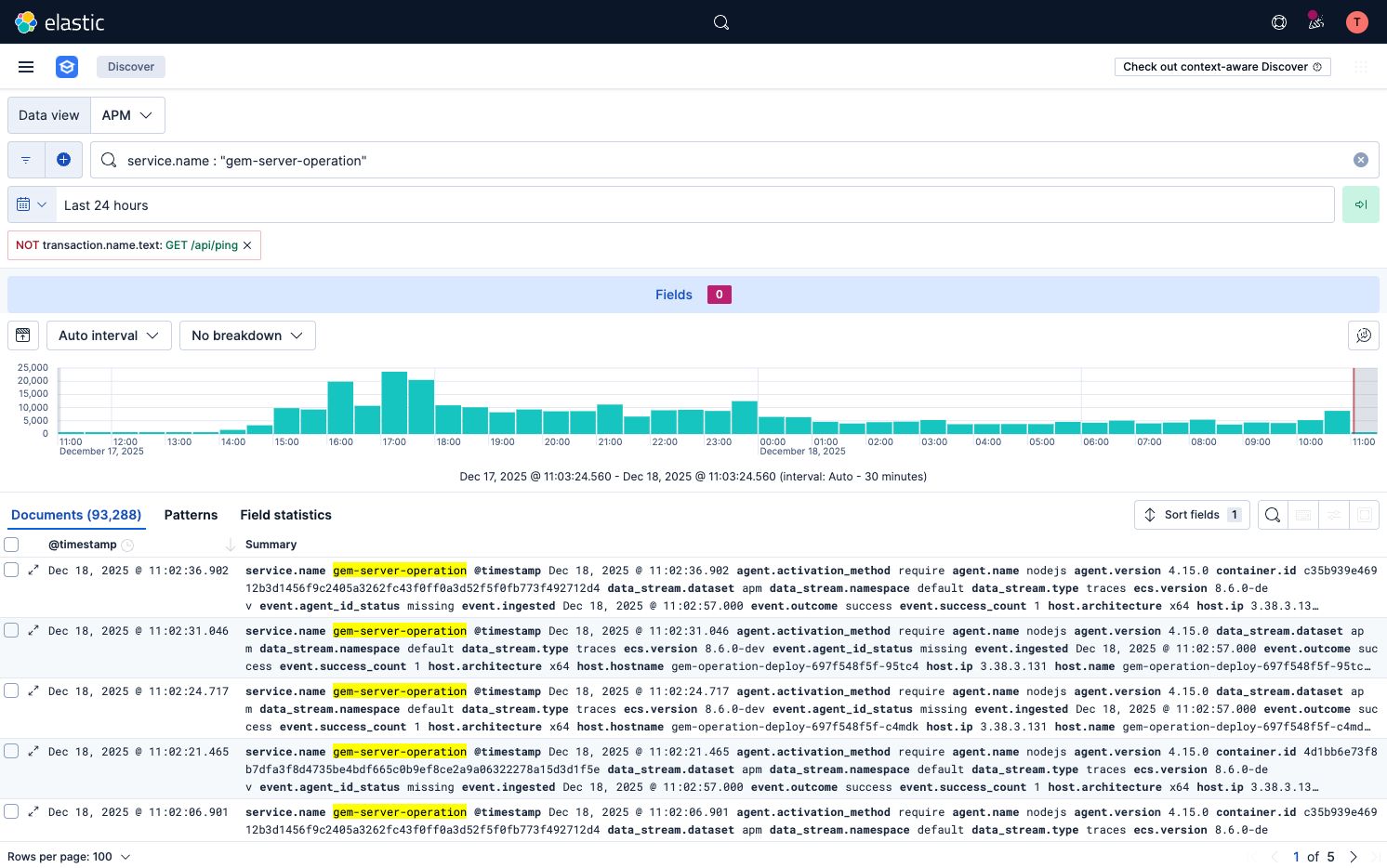
정말 현실적인 트래픽은 낮다.
이 수치는 아래와 같이 정리할 수 있습니다.
- 93,288건 / 일
- 시간당: 약 3,887건
- 분당: 약 64.8건
- 초당: 약 1.1건
- 서버 스펙
- CPU: 1-2코어 (requests-limits)
- 메모리: 2-4GB
초당 1.1건이라는 숫자를 다시 강조하고 싶습니다. 이 정도 트래픽에서 CPU나 네트워크가 병목이 될 수는 없습니다. Elastic APM 히스토그램을 봐도 트래픽이 고르게 분산되어 있고, 특별한 피크 타임도 없습니다.
다만 저희 서비스는 모집 플랫폼 특성상, 평소에는 트래픽이 거의 없다가 모집 마감 직전에 1,000~2,000명이 몰리는 구조입니다. 지금처럼 트래픽이 낮은 상황에서도 대역폭이 우상향하고 CPU가 누적 증가하고 있다면, 트래픽이 늘어났을 때는 더 큰 문제가 될 수 있습니다.
따라서 이 글에서 발견한 확실한 문제는 메모리 누수입니다. 이것은 트래픽과 무관하게 시간이 지나면 반드시 터지는 문제이므로 무조건 잡아야 합니다.
CPU, 패킷, 대역폭의 변화는 현재 트래픽 수준에서 그 자체로 장애를 일으킬 수준은 아닙니다. 하지만 이 지표들이 의미 없는 것은 아닙니다. 현재 폴링 기반의 배치 시스템을 이벤트 기반으로 전환하면 자연스럽게 줄어드는 리소스 사용량이기 때문입니다. 설계를 개선했을 때 이 지표들이 얼마나 변하는지가, 곧 개선의 효과를 보여주는 근거가 됩니다.
또한 트래픽이 매우 낮은 상태에서 과분한 리소스를 할당받고 있다는 점도 짚어야 합니다. 리소스를 실제 사용량에 맞게 줄이고 운영하는 것이 비용적으로 합리적입니다.
8. 회사, 제품에 이득을 가져와야 한다.
지금 상황에서 CPU/메모리 최적화를 한다고 하면, 아래와 같은 결과를 낼 것입니다.
- 서버 비용이 거의 나가지도 않는 상황에서, 회사가 비용을 크게 절감하지도 않음
- 사용자 경험이 개선되지도 않음 (이미 충분히 빠름)
- 팀이나 회사가 원하는 [안정성]이 체감할 수준으로 올라가지도 않음
대신 조금 더 확장해서 이러한 분석을 바탕으로 [안정성을 위한 측정과 개선]을 한다로 방향을 잡아보려고 합니다.
- 느린 API (latency가 높은 트랜잭션) 찾아서 개선
- 메모리 leak 모니터링 (장기간 추세)
- 비동기 큐의 잘못된 설계 개선
- 비동기 큐의 에러 처리, 운영 가시화
이러한 것들이 실질적인 안정성 개선이고, 회사와 팀의 발전을 위해 작업하고 보고할 가치가 있어보입니다. (또한 제가 분석한 데이터를 바탕으로 보았을 때 비동기 큐가 문제일 가능성이 크기도 하고요!)
저는 우선 이 중에서 아래 비동기 큐를 중점적으로 점검해보려고 합니다.
- 비동기 큐의 잘못된 설계 개선
- 비동기 큐의 잘못된 설계로 인한 운영 안정성 저하 방지
- 추가적으로 메모리 및 CPU 하드웨어 자원 비효율 개선
- 비동기 큐의 에러처리, 운영 가시화
- 비동기 큐가 잘 돌아가고 있지만, 개발자가 직접적으로 확인하기 어려움
- 복구할 수 있는 에러에 대해서는 에러처리를 할 수 있어야 함
- 에러에 대해서 올바르게 처리할 수 있어야 함
- 성공에 대해서도 올바르게 모니터링 할 수 있어야 함
9. 마치며
- 이번 경험을 통해 측정하지 않으면 개선할 수 없다는 것을 다시 한번 배웠습니다.
- 측정도 잘못된 데이터나 쿼리로 측정하면 잘못된 결론을 낸다는 것을 깨닫기도 했습니다.
- 하지만 모든 것을 측정해야 한다는 것은 아니라고 생각합니다.
- 제한된 리소스 안에서 무엇을 측정할지 선택하는 것이 중요하고 개선하는 것이 중요하다고 생각해요.
- 그래서 측정한 지표를 바탕으로 지속적으로 개선해나가고 싶습니다. 이제 다음 스텝은 누수를 일으킬만한 코드와 설계들을 확인해보고, 차근 차근 개선해보는 절차를 밟아보려고 합니다.