

임시저장 기능 고도화 해보기 (5)
마무리하며
앞선 글에서는 설계, CRUD(ORM), 소켓 관리, 백업에 이르기까지 각각의 고민 과정을 정리했습니다.
이번 글에서는 전체 아키텍처를 다시 한번 정리하며 연재를 마무리하려 합니다.
아키텍쳐 정리
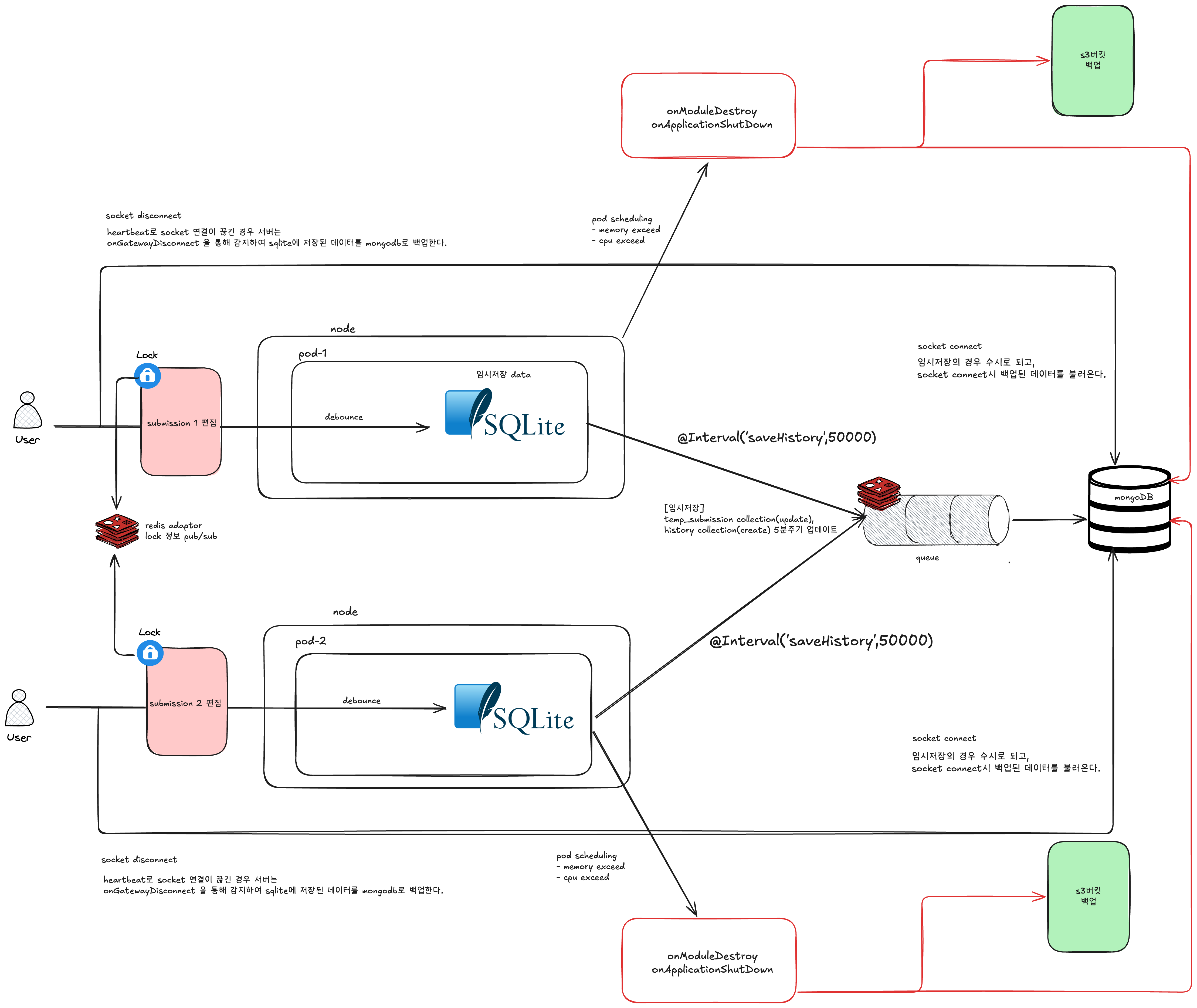
전체적인 아키텍쳐는 이와 같다.
위 아키텍쳐를 점검하고, 아래 플로우차트로 정리해보았습니다.
flowchart TD
subgraph User1[User 1]
direction TB
U1[User]
end
subgraph User2[User 2]
direction TB
U2[User]
end
subgraph Redis["Redis Adapter (Lock 관리, pub/sub)"]
end
subgraph Node["Node Cluster"]
direction TB
subgraph Pod1["Pod-1"]
direction LR
Lock1[Lock<br>submission 1 편집]
Debounce1["Debounce"]
SQLite1["임시 저장 데이터<br>SQLite"]
end
subgraph Pod2["Pod-2"]
direction LR
Lock2[Lock<br>submission 2 편집]
Debounce2["Debounce"]
SQLite2["임시 저장 데이터<br>SQLite"]
end
end
subgraph Queue["Queue"]
end
subgraph MongoDB["MongoDB"]
end
subgraph S3Backup["S3버킷 백업"]
end
U1 -->|편집 요청| Lock1
Lock1 --> Debounce1
Debounce1 --> SQLite1
U2 -->|편집 요청| Lock2
Lock2 --> Debounce2
Debounce2 --> SQLite2
SQLite1 -->|"@Interval('saveHistory', 50000)"| Queue
SQLite2 -->|"@Interval('saveHistory', 50000)"| Queue
Queue -->|임시 저장업데이트 및 생성| MongoDB
subgraph PodEvent["Pod 종료 이벤트 처리"]
direction TB
PodSchedule1[Pod scheduling<br>memory exceed, cpu exceed]
PodSchedule2[Pod scheduling<br>memory exceed, cpu exceed]
onDestroy1[onModuleDestroy, onApplicationShutdown]
onDestroy2[onModuleDestroy, onApplicationShutdown]
end
Node --> PodSchedule1 --> onDestroy1
Node --> PodSchedule2 --> onDestroy2
onDestroy1 --> S3Backup
onDestroy2 --> S3Backup
subgraph SocketEvents["Socket Events"]
heartbeat["heartbeat (socket 연결 확인)"]
onGatewayDisconnect["onGatewayDisconnect<br>MongoDB 백업"]
end
heartbeat -->|연결 확인| MongoDB
onGatewayDisconnect -->|연결 종료시 MongoDB에 임시 데이터 백업| MongoDB
U1 -->|socket connect| SocketEvents
U2 -->|socket connect| SocketEvents
임시 저장 액션
- 사용자가 특정 pod에 연결되어 설문조사를 편집하는 동안, 입력할 때마다 디바운스 처리하여 임시 저장을 수행합니다.
- 임시 데이터는 pod 내의 SQLite에 저장됩니다.
백업 및 소켓 관리
- 백업은 pod 내부의 인메모리 SQLite 데이터를 MongoDB로 이전하는 방식입니다.
- 5분마다 주기적으로 실행되는 Job을 큐에 등록하여 백업을 반복합니다.
- 소켓 연결이 끊어질 때, 사용자가 명시적으로 연결을 종료하거나 하트비트에 실패하는 경우에도 백업이 진행됩니다.
- pod가 종료되면 임시 저장 중인 모든 데이터가 소실되므로, pod에 연결된 모든 설문조사 데이터를 백업합니다. 이 경우에는 추가로 SQLite 데이터를 S3에도 백업합니다.
마치며
사실 임시저장 기능은 단순히 테이블이나 컬렉션을 하나 더 만들어 임시 데이터를 저장하고, 최종 제출 시 원본 데이터에 덮어쓰는 방식으로 구현할 수 있습니다.
하지만 단순한 방법에도 생각할 점이 많습니다. 데이터베이스 관점에서 디바운스 처리로 사용자가 한 글자 입력할 때마다 데이터베이스에 읽기/쓰기 요청이 발생하면, 사용자 수가 많아질 때 심각한 부하와 불필요한 데이터 누적이 발생할 수 있습니다.
사실 현재 저희 프로덕트는 아직 그 정도 트래픽이 아니지만요 ㅎㅎ
팀과 회사의 지원 덕분에 진행할 수 있었고, 더 큰 규모나 고부하 상황을 대비해 견고한 아키텍처를 설계하는 과정이 큰 도움이 되었습니다.
앞으로 운영하면서 예상치 못한 엣지 케이스를 극복하고 기능을 강화해 나가려고 하며, 빠르게 개선 사항을 반영하여 더욱 견고한 시스템을 만들어갈 계획입니다!