

큐를 활용한 배치 시스템을 분석하고 개선해보자 (2)
1. 들어가며
이전 글에서 제품 서버에 대한 분석을 하면서 누수 지점이 있는 것을 확인할 수 있었습니다. 메모리 누수(우상향)는 class-validator 라이브러리를 잘못 사용하고 있던 문제임을 찾아냈습니다. 하지만 우상향이 아닌 메모리 사용량 자체도 점검해볼 필요가 있었고, 또한 CPU / 네트워크 지표의 경우는 다른 상황이였는데요, 원인을 추리던 중 비동기 큐를 활용하여 배치 작업을 진행하는 부분이 가장 유력하다 생각했습니다.
해당 기능을 배포한 시점부터 사용량이 크게 늘기도 했고, 코드와 설계를 돌아보았을때 꽤나 많은 데이터를 한번에 메모리에 적재하고 처리하는 구조인데요, 작업의 목표는 아래와 같습니다.
- 비동기 큐의 잘못된 설계 개선
- 비동기 큐의 잘못된 설계로 인한 운영 안정성 저하 방지하고, 추가적으로 런타임에서의 메모리 적재 구조나 네트워크 요청 및 CPU 하드웨어 자원 비효율 개선합니다.
- 비동기 큐의 에러처리, 운영 가시화
- 비동기 큐가 잘 돌아가고 있지만, 개발자가 직접적으로 확인하기 어려운 상태입니다. 따라서 복구할 수 있는 에러에 대해서는 에러처리를 할 수 있어야 하고, 모든 에러에 대해서 알림을 알리고 올바르게 처리할 수 있어야 합니다. 추가적으로 성공에 대해서도 올바르게 집계하고 모니터링 할 수 있어야 해요.
2. 현재 설계 상태 검토해보기
이전 글에서 글에 작성한 기능인데요, 사용자들이 특정 설문조사나 지원서에 대한 응답값을 버퍼에 쌓아 저장하고, 스케줄러를 통해 배치로 이를 읽어와서 구글 시트에 작성하는 기능입니다.
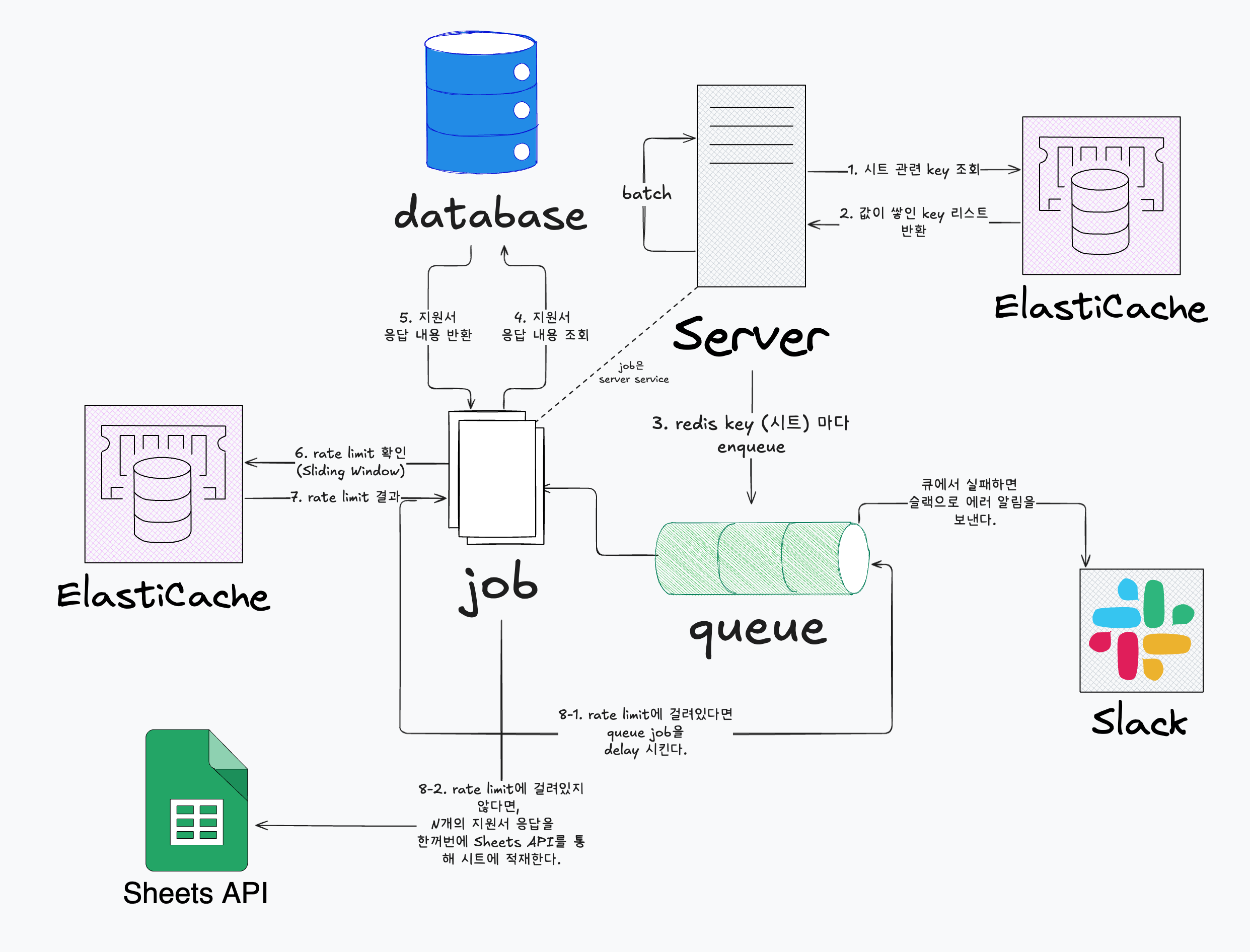
전체적인 데이터 일괄 flush 구상도
전체적으로 rateLimiter를 기반으로 Google Sheet의 rateLimit을 회피하면서 작동하고 있습니다.
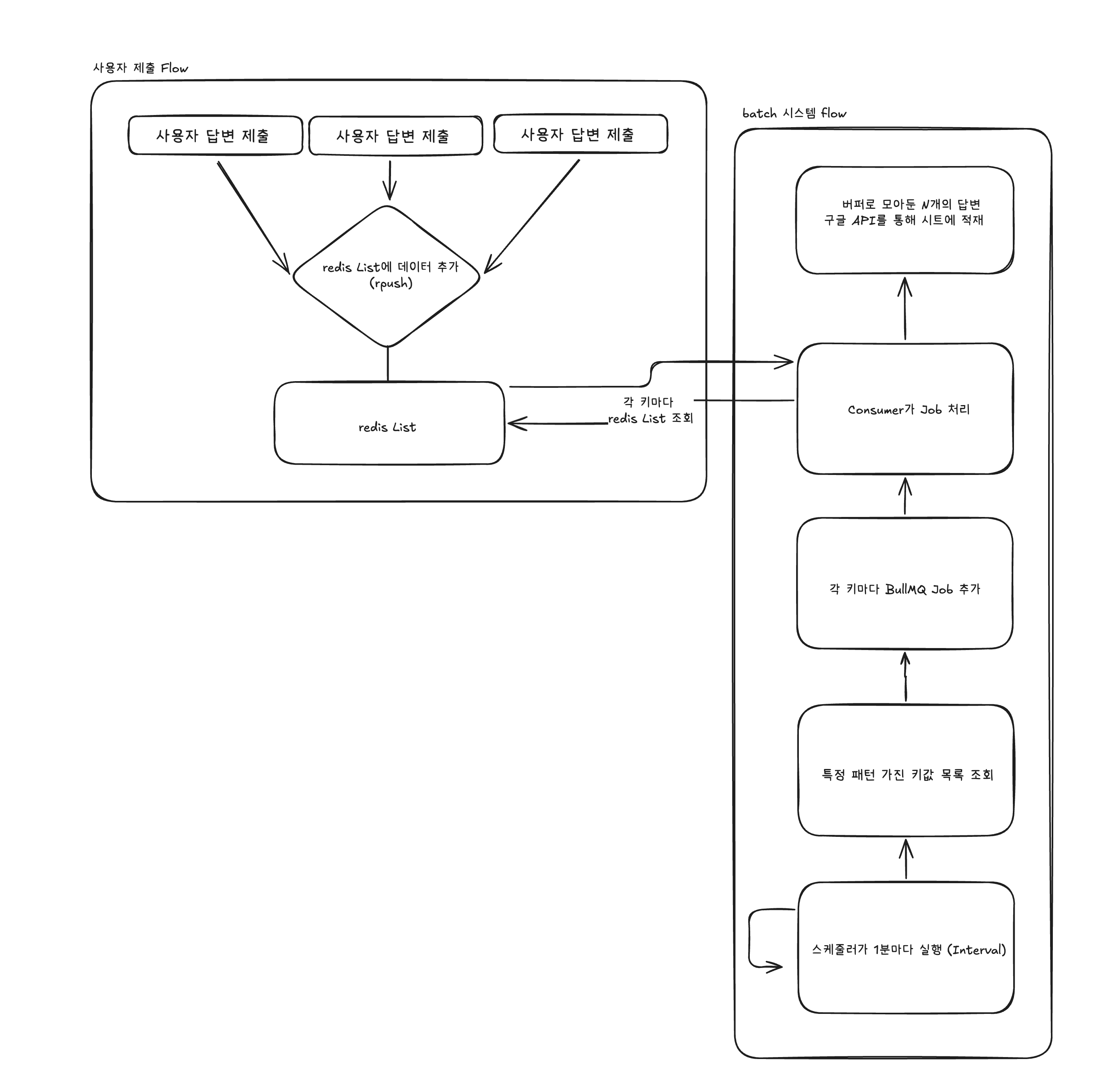
간단한 데이터 일괄 flush 구상도
여기서 핵심적으로 살펴보아야 할 부분은 redis List에 버퍼를 쌓는 부분, 스케줄러가 1분마다 Interval로 도는 부분, batch로 한번에 버퍼를 읽고 Google Sheet API를 호출하는 부분을 보아야 합니다.
해당 부분들이 과연 올바른 설계일지, 런타임에서 메모리를 많이 잡아먹고 있는지에 대해서 살펴보면서 검토해보려고 합니다.
3. 배치 방식 시뮬레이션
현재 설계가 실제로 어떻게 동작하는지, 그리고 런타임에서 메모리를 얼마나 사용하는지 확인하기 위해 시뮬레이션 코드를 작성했습니다. 현재 배치 방식의 동작 흐름은 아래와 같습니다.
실험 구성
실험은 크게 세 단계로 구성했습니다.
1단계: 데이터 생성 및 Redis 저장
async populateRedis() {
// 여러 submission에 분산 저장 (현실적인 시나리오)
const submissionCount = Math.max(10, Math.floor(this.dataSize / 100));
for (let i = 0; i < this.dataSize; i++) {
const answer = generateMockAnswer(i);
const key = REDIS_KEY.batch.buffer(answer.submissionId);
await this.redis.rpush(key, JSON.stringify(answer));
// 메모리 스냅샷 수집 (1000개마다)
if (i % 1000 === 0) {
this.memorySnapshots.push({
phase: 'populate',
index: i,
memory: getMemoryUsage(),
});
}
}
}
현실적인 시나리오를 반영하기 위해 여러 submission에 데이터를 분산해서 저장했습니다. 데이터 생성 중에도 메모리 사용량을 추적하기 위해 1000개마다 메모리 스냅샷을 수집했습니다.
2단계: 배치 처리 시뮬레이션
async processBatches() {
// Redis에서 모든 키 조회
const keys = await this.redis.keys(REDIS_KEY.batch.pattern());
// 각 키마다 처리
for (let i = 0; i < keys.length; i++) {
const key = keys[i];
// 전체 배열을 메모리에 로드
const rawData = await this.redis.lrange(key, 0, -1);
// 전체 배열을 파싱 (메모리 2배 사용)
const parsedData = rawData.map((item) => JSON.parse(item));
const answers = parsedData.map((item) => item.answer);
// Rate limit 체크
const userId = key.split(':').pop();
while (!(await this.rateLimiter.checkLimit(userId))) {
await this.sleep(1000);
}
// 배치로 시트 API 호출 (최대 1000개씩)
for (let j = 0; j < answers.length; j += CONFIG.experiment.maxBatchSize) {
const batch = answers.slice(j, j + CONFIG.experiment.maxBatchSize);
await this.mockAPI.appendRows(batch);
}
// Redis 정리
await this.redis.ltrim(key, 1, 0);
// 메모리 체크 및 스냅샷 저장
const currentMemory = getMemoryUsage();
this.memorySnapshots.push({
phase: 'process',
keyIndex: i,
itemCount: rawData.length,
memory: currentMemory,
});
}
}
스케줄러가 동작하는 것처럼 시뮬레이션하기 위해 모든 키를 조회한 후, 각 키마다 순차적으로 처리했습니다. 각 키를 처리할 때마다 메모리 사용량을 기록했고, Rate limit도 고려해서 실제 동작과 유사하게 구현했습니다.
3단계: 결과 출력
printResults(duration) {
console.log(`총 처리 시간: ${(duration / 1000).toFixed(2)}초`);
console.log(`처리된 데이터: ${this.dataSize}개`);
console.log(`처리 속도: ${Math.round(this.dataSize / (duration / 1000))}개/초`);
this.mockAPI.printStats();
// 메모리 분석
const peakMemory = Math.max(...this.memorySnapshots.map((s) => s.memory.heapUsed));
const avgMemory =
this.memorySnapshots.reduce((sum, s) => sum + s.memory.heapUsed, 0) /
this.memorySnapshots.length;
console.log('\n💾 메모리 분석:');
console.log(` - 피크 메모리: ${Math.round(peakMemory)}MB`);
console.log(` - 평균 메모리: ${Math.round(avgMemory)}MB`);
}
실험 결과로 총 처리 시간, 처리 속도, API 호출 통계, 그리고 메모리 분석 결과를 출력했습니다. 메모리는 피크 메모리와 평균 메모리를 계산해서 보여주도록 했습니다.
배치 방식 결과
실험 결과를 정리하면 아래와 같습니다.
- 총 처리 시간 (초): 3.2s
- Rate Limiter 대기 시간 (초): 0.0s
- API 호출 수 (회): 24회
- 호출당 평균 Google Sheet 입력 행: 40개
- 피크 메모리 (MB): 10MB
우선 API 효율성이 좋아 보입니다. 24개의 submission에 대해 24번의 API 호출만 발생했는데요, Rate limit도 60req/min 중 24회만 사용해서 여유가 있었고, 대기 시간도 전혀 없었습니다. 배치로 묶어서 처리하기 때문에 API 호출 횟수를 최소화할 수 있었습니다.
둘째, 메모리 사용량이 낮은 것으로 보입니다. 피크 메모리가 10MB로 매우 낮게 나왔습니다. submission당 평균 40개 데이터를 처리했는데, 이는 약 20KB 수준입니다. 최대 354개까지 처리해도 문제없을 것으로 보입니다. 현재 데이터 규모에서는 메모리 문제가 전혀 없었습니다.
마지막으로 코드가 단순하고 구현이 매우 단순합니다. lrange로 데이터를 가져오고, 파싱한 다음 API를 호출하고, ltrim으로 정리하는 4줄 정도의 코드로 끝납니다. 유지보수하기도 쉽고, 코드를 이해하기도 어렵지 않습니다.
배치 방식 문제점
메모리 사용량은 문제가 없었지만, 다른 문제들이 있었습니다.
1. 불필요한 서버 부하
@Interval로 1분마다 스케줄러가 실행되는데, 데이터가 없어도 무조건 작동합니다. Redis 키 조회와 API 호출이 계속 발생해서 서버에 불필요한 부하를 주고 있었습니다.
2. 사용자 대기 시간 문제
가장 큰 문제는 사용성입니다. 1분마다 배치 작업이 돌기 때문에 사용자는 최대 1분을 기다려야 합니다. 더 큰 문제는 제출 시점에 따라 대기 시간이 달라진다는 점입니다. 58초에 제출한 사용자는 2초만 기다리면 되지만, 1초에 제출한 사용자는 59초를 기다려야 합니다.
3. 사용자 혼란
사용자 입장에서는 언제 반영되는지 알 수 없어서 혼란스러웠고, 반영되지 않는다고 느끼는 경우도 많았습니다. 제보가 들어올 때마다 "1분 후에 적용됩니다"라고 답변해야 했는데, 이는 좋은 사용자 경험이 아니었습니다.
4. 즉시 적재 방식 시뮬레이션
우선 배치 방식의 사용자 대기 시간 문제를 해결하기 위해 즉시 적재 방식을 고려했습니다. 즉시 적재 방식은 사용자가 제출한 데이터를 바로 처리하는 방식입니다. 각 답변을 개별적으로 큐에 추가하고, Consumer가 하나씩 가져와서 즉시 시트 API를 호출하는 방식으로 동작합니다.
실험 구성
즉시 적재 방식도 세 단계로 구성했습니다.
1단계: 데이터 생성 및 Redis 큐에 저장
async populateQueue() {
const { distribution, totalItems } = generateRealisticData(this.scenario);
const queueKey = REDIS_KEY.oneByOne.queue();
// 모든 답변을 단일 큐에 저장
for (const { submissionId, itemCount } of distribution) {
for (let i = 0; i < itemCount; i++) {
const answer = generateMockAnswer(submissionId, i);
await this.redis.rpush(queueKey, JSON.stringify(answer));
}
}
}
배치 방식과 달리 모든 답변을 단일 큐에 저장합니다. submission별로 분리하지 않고 하나의 큐에 모든 데이터를 쌓습니다.
2단계: 1:1 처리 (항목당 1회 API 호출)
async processOneByOne() {
const queueKey = REDIS_KEY.oneByOne.queue();
while (true) {
// 큐에서 하나씩 lpop
const rawData = await this.redis.lpop(queueKey);
if (!rawData) {
break; // 큐가 비었음
}
// 파싱 (한 개만)
const data = JSON.parse(rawData);
const answer = data.answer;
// 항목마다 개별 API 호출 (Rate limit 자동 대기)
await this.mockAPI.appendRow(answer);
this.processedCount++;
}
}
배치 방식과 달리 각 항목마다 개별적으로 API를 호출합니다. 큐에서 하나씩 가져와서 파싱하고, 즉시 시트 API를 호출하는 방식입니다.
3단계: 결과 반환
getResults(duration, totalItems) {
const apiStats = this.mockAPI.getStats();
const peakMemory = Math.max(...this.memorySnapshots.map((s) => s.memory.heapUsed));
const avgMemory =
this.memorySnapshots.reduce((sum, s) => sum + s.memory.heapUsed, 0) /
this.memorySnapshots.length;
return {
approach: 'one-by-one',
totalItems,
duration,
throughput: Math.round(this.processedCount / (duration / 1000)),
apiCalls: apiStats.totalRequests,
avgRowsPerCall: apiStats.avgRowsPerRequest,
totalWaitTime: apiStats.totalWaitTime,
peakMemoryMB: Math.round(peakMemory),
avgMemoryMB: Math.round(avgMemory),
};
}
처리 시간, 처리량, API 호출 통계, 메모리 사용량 등을 반환합니다.
1:1 방식 결과
실험 결과를 정리하면 아래와 같습니다.
- 총 처리 시간 (초): 904.4초 (15분 4초)
- Rate Limiter 대기 시간 (초): 806.6초 (13.4분)
- API 호출 수 (회): 939회 (데이터 개수만큼)
- 호출당 평균 Google Sheet 입력 행: 1개
- 피크 메모리 (MB): 7MB
- 배치 대비 처리 시간: 282배 느림
939개 데이터를 처리하는데 939번의 API 호출이 발생했습니다.
Rate limit인 60req/min 제한에 걸려서 13분 넘게 대기 시간이 발생했습니다. 실제 운영 데이터(873개)로 환산한다고 가정하면, 아래와 같은 방식으로 운영됩니다.
- 873번 API 호출
- 약 14분 40초 소요 예상

만약에 답변이 몰린다면, 엄청나게 지연되어서 실행이 되겠죠?
즉시 적재 방식 장점
1. 메모리 사용량이 최소
배치 방식처럼 전체 데이터를 메모리에 로드하지 않고, 한 번에 하나씩만 처리하기 때문에 메모리 사용량이 매우 낮습니다. 메모리 사용량이 일정하게 유지되어 메모리 누수 위험이 적습니다.
2. 사용자 대기 시간 제로
사용자가 제출한 데이터를 즉시 처리하기 때문에 대기 시간이 없습니다. 배치 방식의 최대 1분 대기 시간 문제를 완전히 해결할 수 있습니다.
3. 사용자 경험 개선
사용자가 언제 반영되는지 알 수 없어서 발생하던 혼란을 해소할 수 있습니다. 제출 즉시 반영되기 때문에 사용자 경험이 크게 개선됩니다.
즉시 적재 방식 단점
1. API 호출 수가 데이터 개수만큼
가장 큰 문제는 API 호출 횟수입니다.
배치 방식은 24개 submission에 대해 24번의 API 호출만 발생했지만, 즉시 적재 방식은 데이터 개수만큼 API 호출이 발생합니다. 873개의 데이터가 있다면 873번의 API 호출이 발생합니다.
2. Rate limit에 걸림
Google Sheet API의 rate limit은 60req/min입니다.
873개의 데이터를 처리하려면 최소 15분이 소요됩니다. Rate limit에 걸려서 대기 시간이 발생하고, 처리 속도가 매우 느려집니다.
3. 배치 효율 제로
배치 방식은 여러 데이터를 묶어서 한 번에 처리하기 때문에 효율적이지만, 즉시 적재 방식은 배치의 이점을 전혀 활용하지 못합니다. API 호출 오버헤드가 데이터 개수만큼 발생합니다.
5. 현실에 맞는가?
하지만 중요한 점은 현실에 맞지 않는다는 것입니다. 저희 서비스가 873번의 요청이 매번 들어오지 않습니다. 다만 모집이 많을때는 제출 API에 있어서 tps가 1000까지 한번에 몰리기도 합니다. 이 두가지 사항을 모두 현실적으로 고려해보아야 했습니다. 모집 마감일 경우에만 트래픽이 몰리는 저희 서비스 특성에 맞는 방법을 찾아야 했어요.

현실 트래픽에 맞게 생각해보자. 오버엔지니어링이 아닐까?
그래서 배치 방식이 아닐때 걱정할 수 있는 rate limit 무한대기 현상은 사실 평소에는 일어나지 않습니다.
- 하루 800개 = 시간당 ~33개 = 분당 ~0.5개
- 평소라면 Rate limit (60req/min)에 전혀 걸리지 않음
위에서도 언급하였지만, 배치 방식으로 할때 발생하는 단점은 아래와 같습니다.
1. 사용자 경험 저하
- 실시간 처리가 필요한데, 실시간으로 반영되지 않음
- 지연 시간 (다음 배치까지 대기)
2. 개발 경험 저하
- 복잡성 증가 (스케줄러, 에러 처리, 재시도 로직)
- 디버깅 어려움
- 메모리 차이 미미, 3MB 차이는 사실 크게 무의미
평소에는 일어나지도 않을 일인데, 이러한 사용자의 불편함을 감수하면서 가져가는 것은 오버엔지니어링이 아닐까요?
특히나 사용자 경험을 해치는 것은 제품의 퀄리티를 떨어뜨리는 것이기 때문에 굉장히 민감하게 반응해야 하는 문제라고 생각합니다.
6. 타협이 필요하다
그래도 피크 시간대(모집 마감 임박)에는 사용자가 몰리기 때문에 효율적으로 Google API를 사용할 필요도 있습니다.
그렇다면 배치 방식과 1대1 방식을 혼합하면 어떨까요?
우선 첫번째로 이를 혼합하기 위해 고려했을 때, 현재 스케줄러로 배치를 돌게 되는것이 사용성 측면에서 문제가 있다고 판단하였습니다.
6.1 스케줄러를 걷어내자
위에서도 언급하였지만, 현재와 같이 스케줄러로 1분마다 돌면서 배치를 돌게 되면 문제점이 있습니다.
-
사용자가 답변 제출 → Redis 저장
-
[최소 0초 ~ 최대 59초 대기]
-
1분 스케줄러 실행 → 시트에 저장
위와 같이 1분마다 스케줄러를 돌리게 되면 아래와 같은 문제점이 발생합니다.
1. 불규칙한 데이터 처리
- 18:00:01에 제출하면 1초만 대기
- 18:00:59에 제출하면 59초 대기
2. 실시간성 없음
- 사용자는 제출했는데 시트에 언제 반영되는지 모름
3. 비효율적
- 1분 동안 답변 1개만 들어와도 1분 기다림
이벤트 기반의 큐 시스템을 잘 활용하면 더 나은 구조가 될 것이라고 생각합니다.
6.2 버퍼에 쌓는 형태를 변경하자.
사용자가 제출하는 답변은 아래와 같은 JSON 구조를 가지고 있습니다.
이러한 JSON을 stringify해서 redis list에 모두 적재하고 있는데요, 이게 메모리 관점에서 효율적일지 검토해보았습니다.
{
"_id": {
"$oid": "6950137150bc8dcb428cbfd8"
},
"submissionId": {
"$oid": "687615a572fdf6d16013e5b0"
},
"userId": {
"$oid": "687615a572fdf6d16013e5b1"
},
"answers": {
"submission_question_687615a572fdf6d16013e5b4": {
"value": {
"encryptedValue": {
"$binary": "AgV4lDgM4rFghGy3kGjArwZVwmkqnIbj16hRq5QJAdPkqaoAxQADABVhd3MtY3J5cHRvLXB1YmxpYy1rZXkAREEyR3d5VVdsY1R5YnZQQldyL1RJWkZTWk1IWFRtZ2JPdDEyNkh2Vk5HVEM2M1hIOVhQVnk2QksvWXkzWjczeDNiZz09AAVkZWtJZAAkMWFhMjdkZjAtMzIzOS00Y2Y2LWFlYzItMmFkZTRhMzkzMWUwAAtrZXlBbHROYW1lcwAqc3VibWlzc2lvbl9hbnN3ZXJfNjk1MDEzNzE1MGJjOGRjYjQyOGNiZmQ4AAIAB2F3cy1rbXMAUGFybjphd3M6a21zOmFwLW5vcnRoZWFzdC0yOjg3OTY4NDg5MTM1ODprZXkvNzJhMDBjM2QtMGI3ZS00NmI0LWIwNGQtMTFmNTk0NWFlYTM0ALgBAgEAeNt1lT1FAFc36dfitRT4QdYE7wYCMy6QHolSB2UzunkQAQxE4mfLaFKEg3sFaaojiOEAAAB+MHwGCSqGSIb3DQEHBqBvMG0CAQAwaAYJKoZIhvcNAQcBMB4GCWCGSAFlAwQBLjARBAwCVOTe+hArhMof6V0CARCAO7zG8O0L5VydKsLZkvdjPCbFRfBy737vnpU7I9LrtG7CQrJjuYcVa0RCO2x6iF+jYfNRYikq1Gu0QkAUAAdhd3Mta21zAFBhcm46YXdzOmttczphcC1ub3J0aGVhc3QtMjo4Nzk2ODQ4OTEzNTg6a2V5LzcyYTAwYzNkLTBiN2UtNDZiNC1iMDRkLTExZjU5NDVhZWEzNAC4AQICAHjbdZU9RQBXN+nX4rUU+EHWBO8GAjMukB6JUgdlM7p5EAFXXabP4lq0HLqLp2iqLk8lAAAAfjB8BgkqhkiG9w0BBwagbzBtAgEAMGgGCSqGSIb3DQEHATAeBglghkgBZQMEAS4wEQQMRbgU39qX6fJytrjuAgEQgDt4E6GT3WSeodsH1eb+gPjFKATjOZFnfOw5e4wmqjoId6dRczjJ6dQhojKGqsBHTkWuUqd6PsbiUB42ggIAABAAqjgXMVnSbncjLqBOEaqad1Q7dV+9PhOk9+65kxZI/evrXzMZa2X06qzMRnX8jM6D/////wAAAAEAAAAAAAAAAAAAAAEAAAAJ6Z0EbL/Hy6XvNFUCKN95euTGzWk//SxYXABoMGYCMQDQVLqyXa08yZnLxQXdcDkFIG+Ul0A9nMf1lTmseMyHpafduCwQKOoHOuIksfr94gYCMQC7uydUHr74xhXzO1eFuSqo2/gulKbMHJnx1eHdJnBrBQigXYdTdKniiheq0y2DLF4=",
"$type": "06"
},
"maskedValue": "이*택"
}
}
// ... 더 많은 답변 필드들
},
"submissionVersion": 5,
"dataKeyId": "1aa27df0-3239-4cf6-aec2-2ade4a3931e0",
"createdAt": "2025-12-27T17:12:17.666Z",
"updatedAt": "2025-12-27T17:17:39.122Z",
"submittedAt": "2025-12-27T17:17:39.122Z"
}
데이터 크기 측정 스크립트
const sampleData = {
/* 위의 JSON 데이터 */
};
// JSON 직렬화 크기 측정
const jsonString = JSON.stringify(sampleData);
const sizeInBytes = Buffer.byteLength(jsonString, "utf8");
const sizeInKB = (sizeInBytes / 1024).toFixed(2);
const sizeInMB = (sizeInBytes / 1024 / 1024).toFixed(4);
console.log("실제 데이터 크기 측정 결과");
console.log("=".repeat(60));
console.log(`JSON 직렬화 크기: ${sizeInBytes.toLocaleString()} bytes`);
console.log(`JSON 직렬화 크기: ${sizeInKB} KB`);
console.log(`JSON 직렬화 크기: ${sizeInMB} MB`);
console.log("=".repeat(60));
// encryptedValue만의 크기 측정
const encryptedValues = [];
function extractEncryptedValues(obj) {
for (const key in obj) {
if (key === "encryptedValue" && obj[key].$binary) {
encryptedValues.push(obj[key].$binary);
} else if (typeof obj[key] === "object" && obj[key] !== null) {
extractEncryptedValues(obj[key]);
}
}
}
extractEncryptedValues(sampleData);
const totalEncryptedSize = encryptedValues.reduce(
(sum, val) => sum + Buffer.byteLength(val, "base64"),
0,
);
const avgEncryptedSize = totalEncryptedSize / encryptedValues.length;
console.log(`\n암호화된 필드 분석:`);
console.log(`- encryptedValue 개수: ${encryptedValues.length}개`);
console.log(
`- 총 암호화 데이터 크기: ${(totalEncryptedSize / 1024).toFixed(2)} KB`,
);
console.log(
`- 평균 암호화 데이터 크기: ${(avgEncryptedSize / 1024).toFixed(2)} KB`,
);
console.log(
`- 암호화 데이터 비율: ${((totalEncryptedSize / sizeInBytes) * 100).toFixed(1)}%`,
);
// 시나리오별 메모리 계산
console.log("\n📈 시나리오별 Redis 메모리 예상:");
console.log("=".repeat(60));
const scenarios = [
{ name: "평상시 (40개)", count: 40 },
{ name: "피크 (354개)", count: 354 },
{ name: "최악 (5000개)", count: 5000 },
];
scenarios.forEach((scenario) => {
const totalMemory = sizeInBytes * scenario.count;
const totalMemoryKB = (totalMemory / 1024).toFixed(2);
const totalMemoryMB = (totalMemory / 1024 / 1024).toFixed(2);
console.log(`${scenario.name}:`);
console.log(` - 총 메모리: ${totalMemoryKB} KB (${totalMemoryMB} MB)`);
});
// ID만 저장했을 때의 크기 비교
const idOnlySize = Buffer.byteLength(
JSON.stringify({
submissionAnswerId: sampleData._id.$oid || "6950137150bc8dcb428cbfd8",
}),
"utf8",
);
console.log("\n💡 ID만 저장 vs Raw 데이터 비교:");
console.log("=".repeat(60));
console.log(
`ID만 저장: ${idOnlySize} bytes (약 ${(idOnlySize / 1024).toFixed(2)} KB)`,
);
console.log(`Raw 데이터: ${sizeInBytes} bytes (약 ${sizeInKB} KB)`);
console.log(`차이: ${(sizeInBytes / idOnlySize).toFixed(1)}배`);
scenarios.forEach((scenario) => {
const rawMemory = sizeInBytes * scenario.count;
const idMemory = idOnlySize * scenario.count;
const savings = rawMemory - idMemory;
console.log(`\n${scenario.name} (${scenario.count}개):`);
console.log(` - Raw: ${(rawMemory / 1024 / 1024).toFixed(2)} MB`);
console.log(` - ID만: ${(idMemory / 1024 / 1024).toFixed(2)} MB`);
console.log(
` - 절약: ${(savings / 1024 / 1024).toFixed(2)} MB (${((savings / rawMemory) * 100).toFixed(1)}%)`,
);
});
// 결론
console.log("\n결론:");
console.log("=".repeat(60));
if (sizeInBytes < 1024) {
console.log("데이터 크기가 1KB 미만 → Raw 데이터 저장 추천");
} else if (sizeInBytes < 10 * 1024) {
console.log("데이터 크기가 1-10KB → 상황에 따라 결정");
} else {
console.log("데이터 크기가 10KB 이상 → ID만 저장 고려");
}
console.log(`현재 데이터 크기: ${sizeInKB} KB`);
실험 결과
실제 데이터 크기 측정 결과
- JSON 직렬화 크기: 7,108 bytes
- JSON 직렬화 크기: 6.94 KB
- JSON 직렬화 크기: 0.0068 MB
암호화된 필드
- encryptedValue 개수: 3개
- 총 암호화 데이터 크기: 2.93 KB
- 평균 암호화 데이터 크기: 0.98 KB
- 암호화 데이터 비율: 42.2%
시나리오별 Redis 메모리 예상
-
평상시 (40개)
- 총 메모리: 277.66 KB (0.27 MB)
-
피크 (354개)
- 총 메모리: 2457.26 KB (2.40 MB)
-
최악 (5000개)
- 총 메모리: 34707.03 KB (33.89 MB)
ID만 저장 vs Raw 데이터 비교
-
ID만 저장: 49 bytes (약 0.05 KB)
-
Raw 데이터: 7108 bytes (약 6.94 KB)
-
차이: 145.1배
-
평상시 (40개)
- Raw: 0.27 MB
- ID만: 0.00 MB
- 절약: 0.27 MB (99.3%)
-
피크 (354개)
- Raw: 2.40 MB
- ID만: 0.02 MB
- 절약: 2.38 MB (99.3%)
-
최악 (5000개)
- Raw: 33.89 MB
- ID만: 0.23 MB
- 절약: 33.66 MB (99.3%)
확인하였을때 메모리 측면에서도 굉장히 비효율적입니다.
물론 결국에 id만 저장하더라도, 꺼내서 사용할때 DB에서 조회해서 같은 배열(답변 데이터)를 서버에서 사용하게 될 것입니다.
하지만 목적에 대해서 다시 검토해 볼 필요가 있는데요, redis는 버퍼로만 사용하는 것이기 때문에 raw data를 적재할 필요는 없다고 생각해요.
redis의 메모리 상태도 생각해봐야합니다. 어차피 로컬 메모리 상태에는 큐에 적재하기 전이나 꺼내서 소비할때나 적재하는것은 매한가지입니다. 로컬 메모리 상에서는 최적화할 필요없고, redis에는 굳이 저장할 필요가 없습니다.
7. 새로운 아키텍쳐를 그려보자.
AS-IS
@Interval(ONE_MINUTE_MS)
async processSubmissionAnswerSheetFlush() {
const lockKey = submissionAnswerSheetFlushSchedulerRedisKeyFactory
.lock()
.toKey();
const lockAcquired = await this.redisLockService.acquireLock({
key: lockKey,
value: String(true),
ttl: 1000,
});
if (!lockAcquired) {
return;
}
const keyList = await this.redisService.getKeyListByPattern({
pattern: submissionAnswerSheetRedisKeyFactory
.bufferPattern()
.toKey(),
});
const filteredKeyList =
await this.bullMQService.getQueueUnProcessingKeyList({
keyList,
delayKey: submissionAnswerSheetFlushQueueRedisKeyFactory
.delayed()
.toKey(),
activeKey: submissionAnswerSheetFlushQueueRedisKeyFactory
.active()
.toKey(),
waitKey: submissionAnswerSheetFlushQueueRedisKeyFactory
.wait()
.toKey(),
});
filteredKeyList.forEach((key) => {
void this.submissionAnswerSheetFlushQueue.add(
JOB.SUBMISSION_ANSWER_SHEET_FLUSH,
{
key,
},
{
jobId: key,
removeOnComplete: true,
removeOnFail: true,
},
);
});
}
현재는 1분마다 키값을 모두 조회하고, 이 키값을 큐에 등록하여서 모두 처리하고 있었습니다.
TO-BE
private async appendToSpreadSheetBuffer(
submissionAnswerId: string,
submissionId: string,
spreadSheet: Pick<
SpreadSheet,
'spreadSheetId' | 'sheetId' | 'createUserId'
>,
) {
const key = submissionAnswerSheetRedisKeyFactory
.buffer({
sheetCreateUserId: spreadSheet.createUserId,
submissionId,
spreadSheetId: spreadSheet.spreadSheetId,
sheetId: String(spreadSheet.sheetId),
})
.toKey();
const newBufferSize = await this.redis.rpush(key, submissionAnswerId);
const existingJob =
await this.submissionAnswerSheetFlushQueue.getJob(key);
const isJobActive =
existingJob &&
!(await existingJob.isCompleted()) &&
!(await existingJob.isFailed());
if (!isJobActive) {
if (existingJob) {
await existingJob.remove();
}
await this.createFlushJob(key, newBufferSize);
return;
}
if (
newBufferSize >= FLUSH_THRESHOLD &&
(await existingJob.isDelayed())
) {
await existingJob.promote();
}
}
private async createFlushJob(key: string, bufferSize: number) {
const delay = bufferSize >= FLUSH_THRESHOLD ? 0 : FLUSH_DELAY_MS;
await this.submissionAnswerSheetFlushQueue.add(
JOB.SUBMISSION_ANSWER_SHEET_FLUSH,
{ key },
{
jobId: key,
delay,
removeOnComplete: {
age: REMOVE_ON_COMPLETE_AGE,
count: REMOVE_ON_COMPLETE_COUNT,
},
removeOnFail: true,
},
);
}
위와 같은 코드와 같이 큐에 적재하는 방식으로 변경합니다. 구조는 아래와 같아요.
위와 같은 구조라면 아래와 같이 진행됩니다.
1. Redis 버퍼에 ID 추가
사용자가 답변을 제출하면 Redis List에 고유 ID만 저장합니다. 전체 답변 데이터를 저장하지 않고 ID만 저장함으로써 메모리를 최적화합니다.
2. Job 스케줄링
버퍼 크기에 따라 Job 실행 시점을 결정합니다.
- 버퍼 ≥ 500개: 즉시 실행하여 빠르게 처리합니다.
- 버퍼 < 500개: 10초 후 실행하여 여러 데이터를 모아 배치로 처리합니다.
이를 통해 데이터가 적을 때는 대기하여 배치 효율을 높이고, 데이터가 많을 때는 즉시 처리하여 실시간성을 확보합니다.
3. BullMQ Queue 및 Consumer 처리
스케줄된 Job은 BullMQ Queue에 등록되고, Consumer가 순차적으로 처리합니다.
4. Rate Limit 체크 및 배치 처리
Consumer는 Google Sheet API의 Rate Limit(60req/min)을 체크합니다.
- Rate Limit 초과: Job을 60초 지연시켜 Queue로 다시 돌려보냅니다.
- Rate Limit 통과: 배치 처리를 시작합니다.
배치 처리 과정:
- Redis에서 ID 리스트를 조회합니다
- DB에서 SubmissionAnswer를 조회하여 실제 데이터를 가져옵니다
- 답변을 Sheet 형식으로 변환합니다
- Google Sheet에 데이터를 적재합니다
5. 완료
모든 데이터가 Google Sheet에 적재되면 처리가 완료됩니다.
결론
이렇게 개선된 아키텍처는 다음과 같은 장점을 제공합니다.
1. 실시간성 확보
스케줄러 기반의 고정된 1분 간격 대신, 이벤트 기반으로 동작하여 사용자가 제출한 데이터를 최대 10초 내에 처리할 수 있습니다. 또한 버퍼가 500개 이상 쌓이면 즉시 처리하여 피크 시간대에도 빠르게 대응할 수 있습니다.
2. 메모리 효율성
Redis에 ID만 저장함으로써 메모리 사용량을 99.3% 절감했습니다. 피크 시간대(354개)에도 2.38MB를 절약할 수 있어 Redis 메모리 부족 문제를 해결할 수 있습니다.
3. API 효율성
배치 단위로 처리하여 Google Sheet API 호출 횟수를 최소화합니다. Rate Limit을 고려한 지연 처리로 안정적인 운영이 가능합니다.
4. 유연한 처리
트래픽이 없을 때는 불필요한 스케줄러 실행이 없고, 트래픽이 몰릴 때는 즉시 처리하여 사용자 경험을 개선합니다.
이러한 과정에서 consumer가 consume하는 과정에서도 여러 문제점과 고민이 있었는데요, 아래와 같은 고민이 있었고 이를 해결해보았습니다.
7. 마무리하며
이제 설계를 바탕으로 실제 구현을 진행하려고 합니다. 구현을 진행하면서 운영 효율성을 더 높이는 방법을 고민하며 개발하려고 합니다.
해당 과정과 고민들은 다음 글에서 적어보려고 합니다.