

배치 서버를 실시간 작업으로 변경하자 (feat. Kafka)
1. 들어가며
- 이전 포스트에서 언급한 경험과 같이, 저희 회사에서는 매일 데이터를 수집하고 API를 통해 제출하는 업무를 스크립트로 처리하고 있었습니다. 그러나 이 방식에서 문제가 발생하였고, 쿼리 부하를 줄이며 작업을 효과적으로 관리하기 위해 큐 기반의 배치 처리 방식으로 전환하여 시스템을 구축하였습니다.
- 하지만 해당 서버를 운영해본 결과 몇가지 문제점들이 발생하였습니다.
2. 문제 상황
첫번째, 사용자 경험
- 배치를 통한 작업은 하루에 한 번만 이루어지기 때문에 사용자 경험(UX) 측면에서 문제가 있었습니다.
- 구축한 배치 서버는 하루 동안 쌓인 교육 훈련 데이터를(e.g. 강의 수강, 출석, 문제 풀이) 종합하여 사용자의 훈련 누적 시간을 계산합니다.
- 하지만 이 데이터는 하루에 한 번, 새벽 2시에만 갱신되기 때문에 실시간으로 반영되지 않는 문제가 있었습니다.

유저들에게 좋은 사용 경험을 주지 못했다.
사용자 / 관리자 입장에서의 불편함
- 이러한 배치 서버의 구조는 사용자와 관리자 입장에서 불편함을 초래했습니다.
- 사용자 입장
- 실시간으로 데이터가 갱신되지 않아 자신이 올바르게 교육을 진행하고 있는지 확인하기 어려웠습니다.
- 강의를 수강했음에도 불구하고 훈련 누적 시간이 즉시 반영되지 않아 혼란이 발생하였습니다.
- 관리자 입장
- 수강생들의 교육 진행 상황을 실시간으로 확인할 수 없어 운영의 효율성이 저하되었습니다.
일시적으로 증가했던 CS
- 유입되는 CS 도 점점 늘어났습니다. 대표적인 문의 사항은 다음과 같았습니다.
- "저는 N시간의 강의를 수강했는데도 훈련 누적 시간이 늘지 않았어요."
- "출석 체크와 본인 인증을 했는데도 확인되지 않아요."

반복되는 CS가 유입되었다.
UX적 해결 시도와 한계
- 개발팀에서는 이러한 불편함을 해소하기 위해 데이터 갱신 주기에 대한 안내 및 알림 문구를 제공하여 사용자들이 갱신 시점을 인지할 수 있도록 하였습니다. 하지만 이는 근본적인 해결책이 아닌 임시 방편이었고, 사용자 경험이 완전히 개선되지는 않았습니다.
UX적으로 임시방편으로 해결하고자 했다.
- 개발팀 역시 해당 시스템의 문제점을 인지하고 있었으나, 새로운 방식을 도입하기 전까지는 UX적 보완책을 우선 적용할 수 밖에 없었습니다.
- 그러나 이러한 임시 조치에도 불구하고 사용자 CS가 지속적으로 증가하면서 운영 관리자의 부담이 커졌고, 결국 개선 작업을 더 빠르게 추진해야 한다는 결론에 이르게 되었습니다.
두번째, 여전히 존재하는 데이터베이스 부하
- 대량의 데이터 읽기/쓰기 작업이 동시에 이루어지면서 데이터베이스에 과도한 부하가 발생하였었는데요, 이를 개선하기 위해 큐를 활용한 분산 처리 방식을 도입한 결과 CPU 사용률은 800%에서 100~200% 수준(최대 300%)으로 낮아져서 장애가 발생하지는 않았었습니다.
- 하지만 여전히 부하가 완전히 해결된 상태는 아니였습니다.
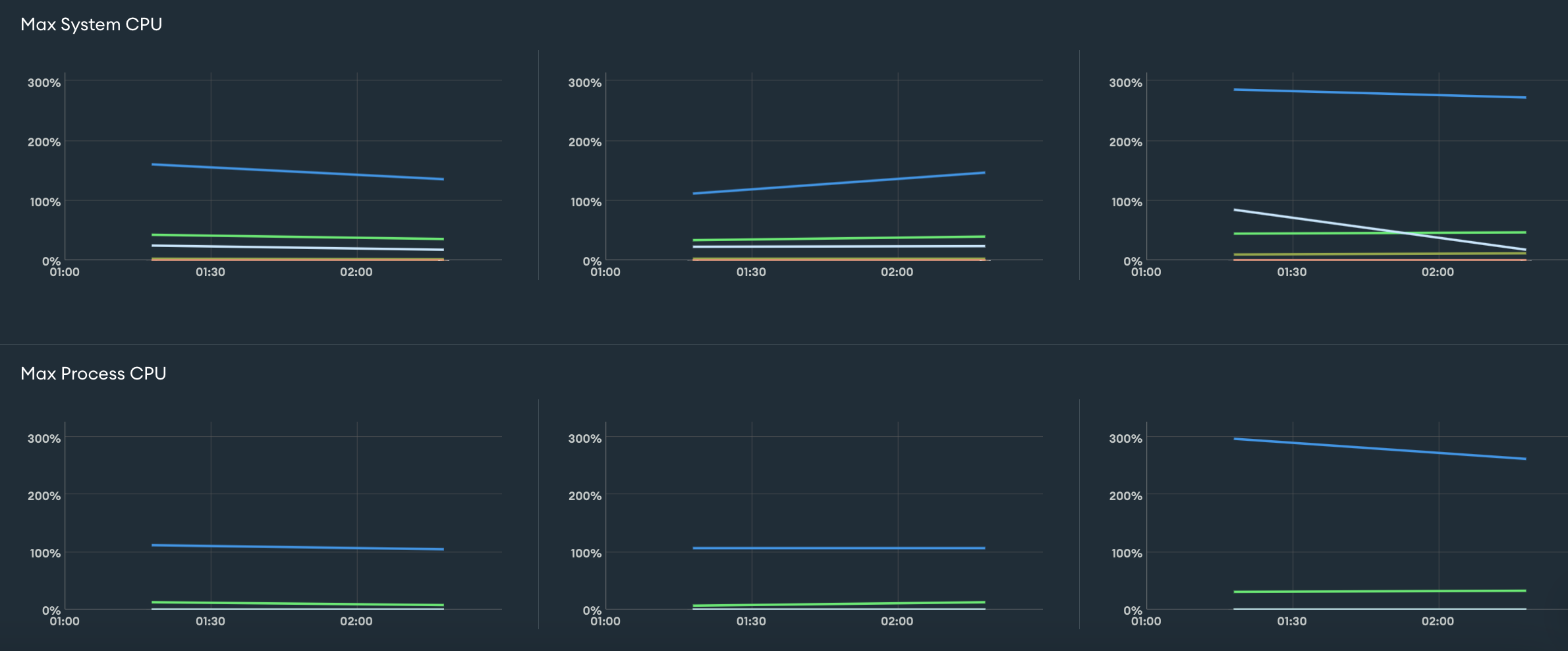
많이 줄긴 했지만, 여전히 부하가 걸리고 있다
3. 어떻게 해결할 것인가?
- 기존 배치 작업을 중단하고, 데이터를 실시간으로 처리할 수 있도록 카프카 기반의 메시지 방식으로 전환하여 시스템을 구축하기로 결정했습니다.
- 목표는 아래와 같이 설정해두었습니다.
- 실시간성을 보장할 것
- 기존 코어 기능(강의 수강, 시험 응시)의 성능에 영향을 미치지 않을 것.
- 대량의 데이터 작업이 데이터베이스에 부하를 주지 않도록 설계할 것.
- 빠르게 개발을 완료해 사용자들의 경험을 개선할 수 있을 것.
3.1 실시간성을 확보하면서 기존 코어 기능의 성능에 미치는 영향 최소화 방안
- 실시간성을 확보하면서 코어 기능 성능에 미치는 영향을 최소화하기 위해 메시지 기반 통신 시스템을 도입하기로 결정했습니다.
- 기존의 코어 로직을 수행하는 서버는 데이터베이스 쿼리 등의 추가 작업 없이 비동기적으로 메시지만 발행하므로 성능에 미치는 영향이 적습니다.
- 또한, 메시지가 실시간으로 발행되기 때문에 데이터를 실시간으로 가공하고 처리할 수 있습니다.
- 메세지 기반 통신 시스템을 설계하는 과정에서 Kafka와 RabbitMQ를 고려하게 되었으며, 결론적으로 Kafka를 선택하게 되었습니다.
Kafka vs RabbitMQ
- 해결해야 할 문제는 여러 서버가 동시에 메시지를 소비하고, 각 서버가 중복된 처리를 하지 않도록 하는 것이었습니다.
- 특히, 메시지 순서가 중요하지 않은 경우였지만, 유저별 순서는 보장해야 했습니다. 이러한 요구 사항에 맞는 시스템을 찾아야 했고, 두 가지 시스템을 비교해 보았습니다.
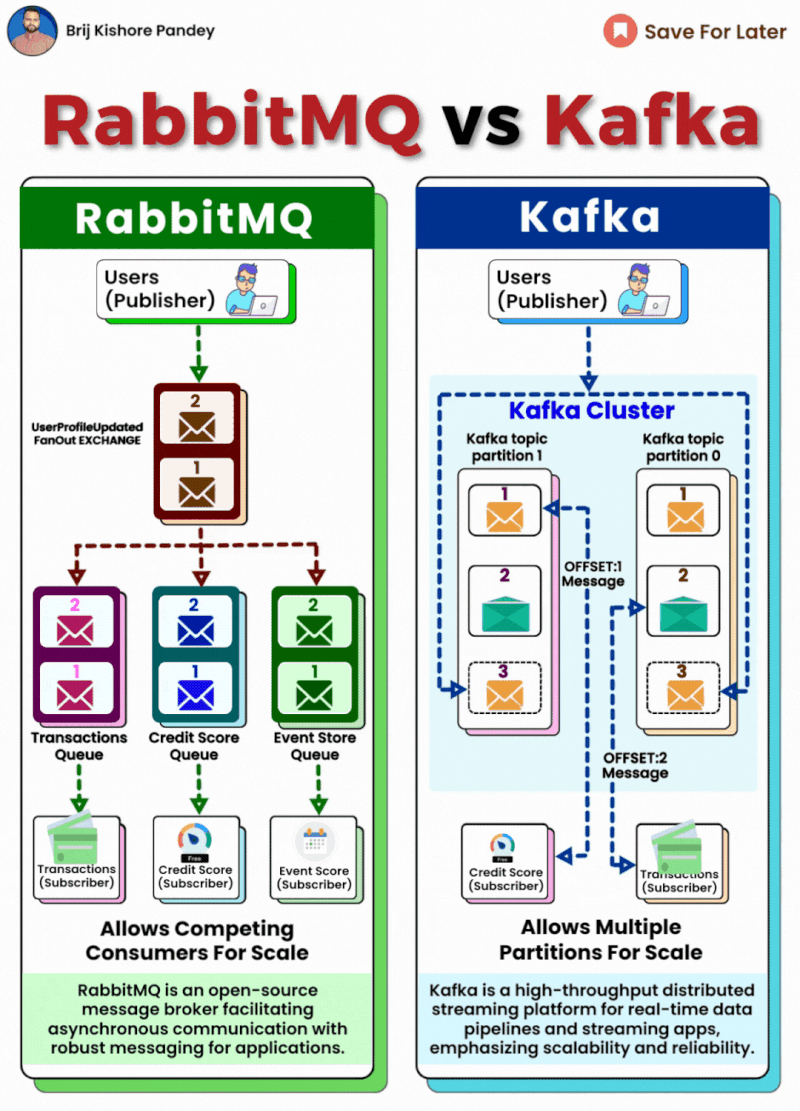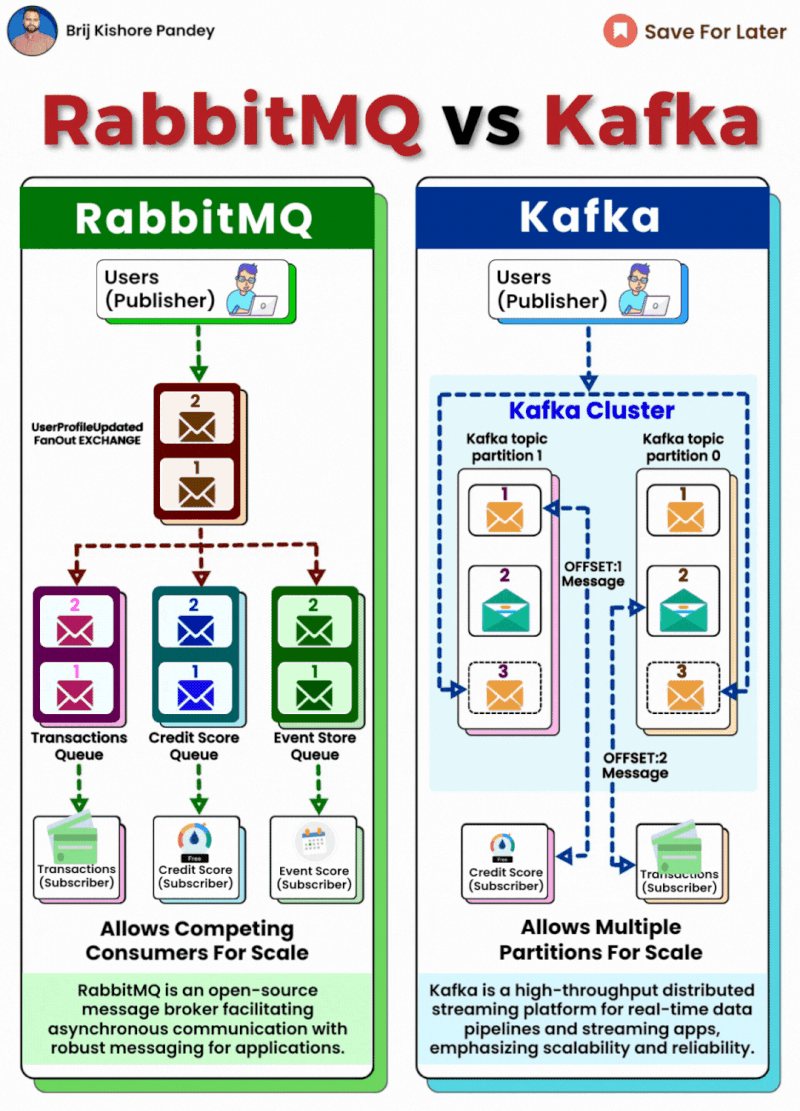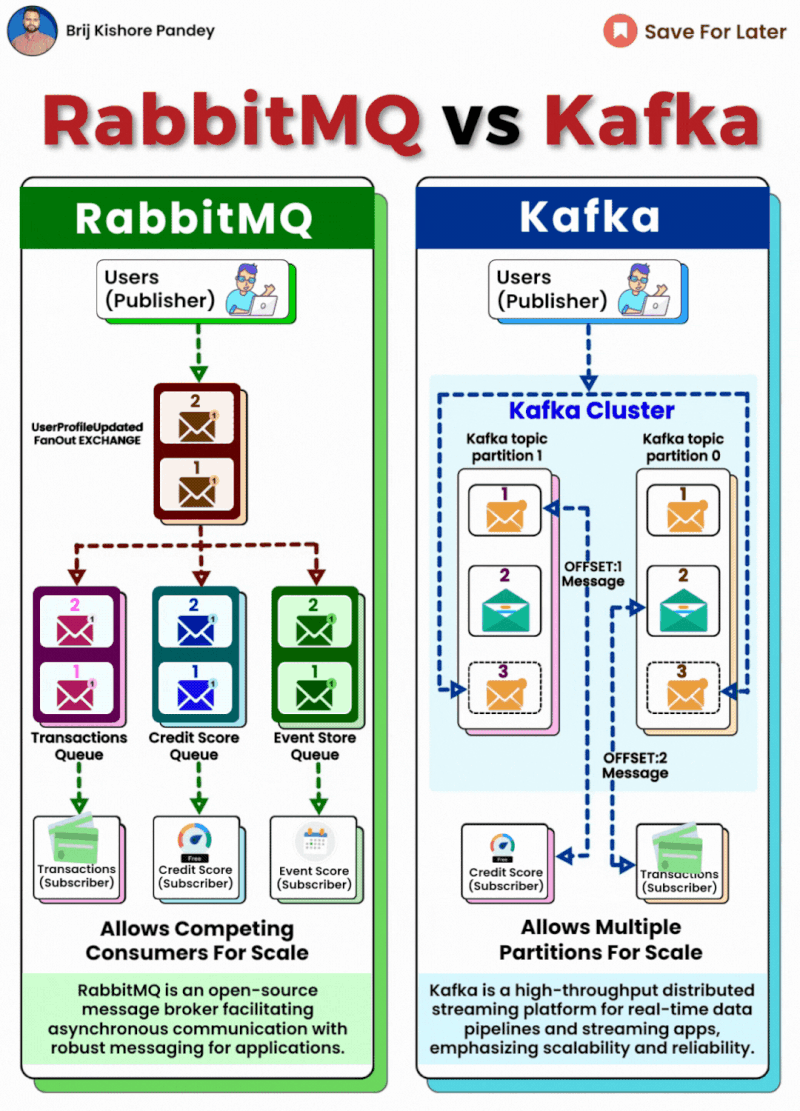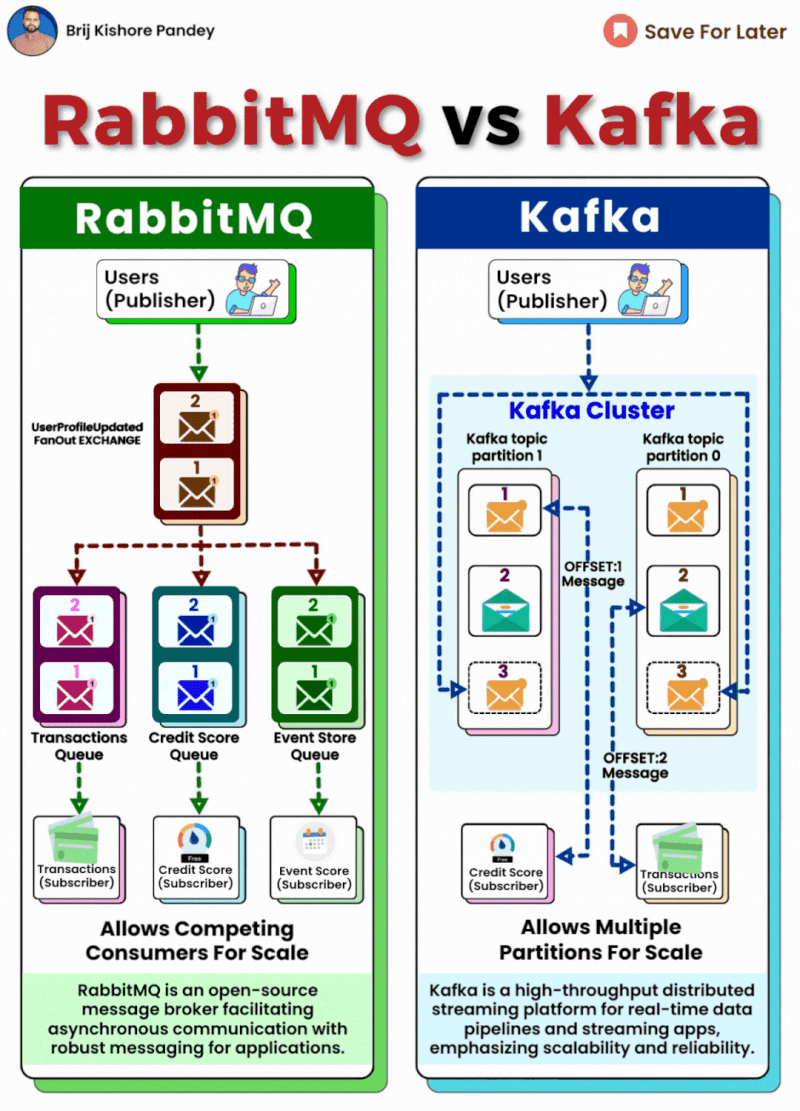
https://shorturl.at/4HACK
RabbitMQ
- RabbitMQ는 기본적으로 큐 기반 메시징 시스템입니다. 큐에 쌓인 메시지는 소비자에게 하나씩 분배되며, 각 메시지는 한번만 소비됩니다.
- RabbitMQ는 메시지 전달 보장과 메시지 순서 보장에서 강점을 가지고 있었습니다.
- 하지만, RabbitMQ는 수평 확장성이 제한적이고, 메시지를 여러 서버가 동시에 소비하는 대규모 시스템에서는 성능과 확장성 측면에서 제한이 있을 수 있다는 단점이 있었습니다.
Kafka
- Kafka는 분산 스트리밍 플랫폼으로 설계되어 고성능과 수평 확장성을 제공하는 시스템입니다. Kafka는 메시지를 토픽 단위로 발행하고, 각 토픽은 파티션으로 나뉘어져 메시지를 분산 처리합니다.
- 여러 소비자가 동일한 메시지를 처리할 수 있어 대규모 시스템에서 유리한 구조를 가지고 있습니다.
- Kafka에서 메시지는 기본적으로 순서를 보장하지 않지만, 순서 보장이 필요한 경우에도 유저별 키값을 기준으로 파티션을 나누는 방식으로 유저별 순서 보장이 가능합니다.
- 이를 통해, 유저마다의 메시지 순서를 보장할 수 있고, 동시에 다수의 서버에서 병렬 처리가 가능하게 됩니다.
선택은 Kafka!
- 여러 가지 고민 끝에 Kafka를 선택한 이유는 현재 사내에 구성된 인프라와 요구사항에 더 적합하다고 판단했기 때문입니다.
- EKS에서 여러 서버를 띄울 수 있는 환경에서, Kafka는 수평 확장성을 제공하여 여러 서버에서 동시에 메시지를 소비하고 처리할 수 있을 것으로 보았습니다.
- Kafka는 대용량 메시지 처리에 최적화되어 있어 높은 처리량을 요구하는 시스템에 적합하다고 생각하였습니다.
- Kafka에서는 병렬처리와 더불어 키값을 기준으로 파티셔닝을 하여 유저별 순서를 보장할 수도 있다는 점에서 유리했습니다.
- 이미 MSK가 구축되어 있었기 때문에, 추가적인 인프라 구축 없이 쉽고 안정적으로 Kafka를 사용할 수 있었습니다.
3.2 다량의 로그성 데이터를 보관하는 방안
- 많은 양의 로그성 데이터를 어떻게 보관할 것인지에 대해 현재 사내 인프라를 기반으로 여러 후보지를 검토하며 고민해보았습니다.
- 설계 과정에서 MongoDB + Elasticsearch와 MongoDB + Redshift(S3) 조합을 고려한 후, 고민 끝에 MongoDB와 Elasticsearch를 함께 활용하는 방식으로 결정했습니다. MongoDB는 원본 데이터 저장소로서 로그 데이터를 저장하고, Elasticsearch는 데이터 보존 및 조회용 백업, 대규모 작업과 배치 처리에 사용될 예정입니다.
- 우선 Kafka를 통해 메시지를 소비하고 로그성 데이터를 정제하여 MongoDB에 적재하는 방식은 이미 앞선 고민에서 결정된 방향이였습니다. Kafka는 실시간 데이터 처리에 적합하고, MongoDB는 사내에서 가장 안정적으로 구축되어 있기 때문입니다.
- 하지만 조회, 대용량 쿼리 및 배치 처리, 백업용 데이터 처리에 대해 Redshift와 Elasticsearch 중 무엇을 사용할지에 대해서는 많은 고민이 있었습니다.

데이터를 어디 잘 보관해야할까
Redshift
- 사내에서는 이미 데이터 분석 용도로 MongoDB에 쌓인 데이터들을 AWS Redshift에 적재하고, S3에는 parquet 형식으로 하루치 데이터를 저장하고 있었습니다.
- parquet 데이터를 불러오는 간단한 스크립트를 통해 테스트를 해보았는데요, 스크립트는 아래와 같습니다.
const AWS = require('aws-sdk');
const parquet = require('parquetjs');
const s3 = new AWS.S3();
const BUCKET_NAME = '버킷 이름';
const PARQUET_FILE_KEY = 'parquet 파일 경로';
async function getS3File(bucket, key) {
const params = {
Bucket: bucket,
Key: key,
};
const data = await s3.getObject(params).promise();
return data.Body;
}
async function readParquetFileAsJSON(parquetBuffer) {
try {
const reader = await parquet.ParquetReader.openBuffer(parquetBuffer);
const cursor = reader.getCursor();
let record = null;
const jsonRecords = [];
while (record = await cursor.next()) {
jsonRecords.push(record);
}
await reader.close();
return jsonRecords;
} catch (err) {
console.error('parquet file 조회 에러 발생', err);
throw err;
}
}
async function processParquetFile() {
try {
const parquetBuffer = await getS3File(BUCKET_NAME, PARQUET_FILE_KEY);
const jsonData = await readParquetFileAsJSON(parquetBuffer);
console.log(JSON.stringify(jsonData, null, 2));
} catch (err) {
console.error('parquet file 프로세싱 에러 발생', err);
}
}
processParquetFile();
- 하지만 테스트 결과, S3에 저장된 parquet 형식의 파일에 포함된 데이터 양이 많을수록 JSON으로 역직렬화하는 과정에서 발생하는 속도 측면의 비용이 너무 커서 해당 방식을 포기하게 되었습니다.
- 또한, 인프라 구성이 데이터 분석을 위한 설계 위주로 되어 있어 비즈니스 서버에서 이를 사용하는 것은 무리라는 데이터 팀과 저희 팀의 판단이 있었습니다.
Elasticsearch
- Redshift 사용의 한계점 파악 후, Elasticsearch 활용법에 대해서 고민해보았습니다.
- 그 와중에 데이터팀과 함께 Debezuim CDC 기능에 대해서 리서치 해보았고, 이를 도입해보기로 했습니다.
- debezium은 수많은 connector들을 지원하고 있었고, mongoDB에 대한 커넥터도 있었습니다. (공식문서)
- 그 중 Database connect와 kafka, elasticsearch connect 활용해서 ES에 적재한 사례가 있었습니다.

connect를 잘 활용해보자
- 위 그림과 같이 데이터베이스에 변화가 생기면, Debezium Connector가 변경 사항을 감지하여 해당 내용을 Kafka 메시지로 전달합니다. 이후 Kafka Connect Elasticsearch Connector를 통해 변경된 데이터가 Elasticsearch에 그대로 적재됩니다.

Streaming Data Changes from Your Database to Elasticsearch
Debezium is an open source distributed platform for change data capture. Start it up, point it at your databases, and your apps can start responding to all of the inserts, updates, and deletes that other apps commit to your databases. Debezium is durable and fast, so your apps can respond quickly and never miss an event, even when things go wrong.
최종 결정, 설계
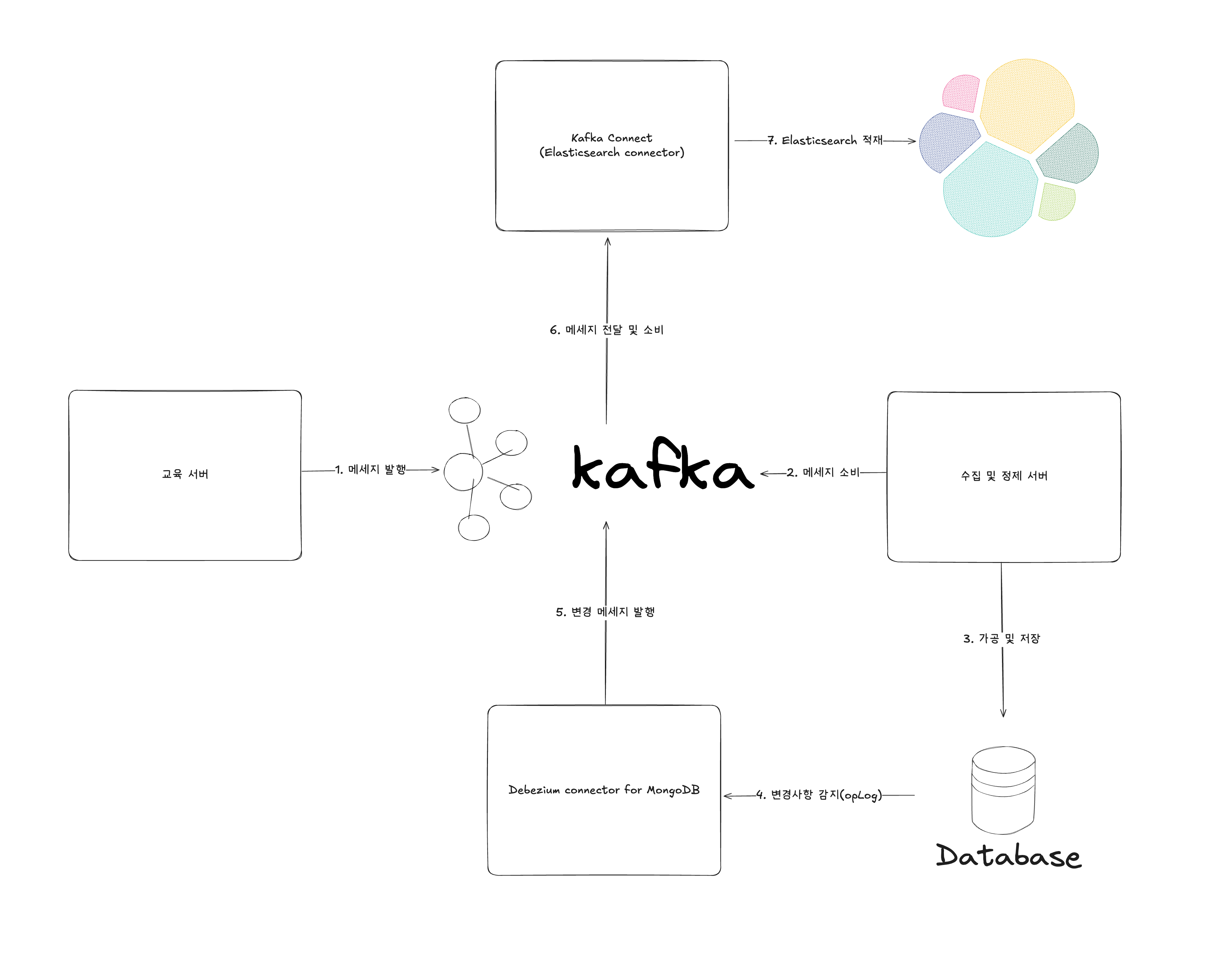
간단하게 구조를 설계를 해보았습니다.
- 최종적으로 아래 순서와 같이 데이터가 처리되는 프로세스를 설계하였습니다.
- 수강생이 교육 서버에서 교육을 시작하면 메세지를 발행합니다.
- 수집 및 정제 서버에서 메세지를 소비합니다.
- 수집 및 정제 서버에서 데이터를 가공하고 mongoDB 데이터베이스에 저장합니다.
- Debezium connector(mongoDB)가 변경사항(insert)을 감지합니다.
- Debezium connector(mongoDB)가 변경사항에 대한 메세지를 발행합니다.
- Kafka Connect(Elasticsearch connector)가 메세지를 전달받고 소비합니다.
- Kafka Connect(Elasticsearch connector)를 통해 Elasticsearch에 적재됩니다.
구현
- 기본적으로 kafka를 사용할때 kafkajs 라이브러리를 사용하였습니다.

KafkaJS · KafkaJS, a modern Apache Kafka client for Node.js
KafkaJS, a modern Apache Kafka client for Node.js
producer
- producer의 역할을 하는 교육 서버는 이미 Kafka를 사용하고 있어, producer 역할을 수행하는 데 있어 쉽게 통합할 수 있었습니다.
const { Kafka, logLevel } = require('kafkajs');
const kafka = new Kafka({
clientId: 'clinet id',
brokers: [Kafka broker list],
logLevel: logLevel.ERROR,
});
const schemaRegistry = new SchemaRegistry({
host: 'schema registry host',
securityProtocol: 'SASL_SSL',
saslMechanisms: 'SCRAM-SHA-256',
saslUsername: 'schema registry sasl username',
saslPassword: 'schema registry sasl password'
});
exports.sendMessage = async ({ topic, messages }) => {
kafka = new Kafka({
clientId: '클라이언트 id',
brokers: [Kafka 브로커 목록],
logLevel: logLevel.ERROR,
});
const schemaId = await this.registry.getLatestSchemaId(
`${topic}-value`,
);
const encodedMessage = await this.registry.encode(schemaId, messages);
const producer = kafka.producer();
await producer.connect();
await producer.send({
topic,
messages,
});
await producer.disconnect();
};
- 위 코드와 같이 Schema Registry를 통해 스키마 검증을 받은 후 메시지를 produce합니다.
consumer
@Controller()
export class Controller {
constructor(private readonly service: Service) {}
@Consume({
topic: 'Kafka 토픽명'
groupId: 'Kafka 그룹 아이디,
})
async consumeLogMessage(message: Message) {
await this.logService.processlog({ message });
}
}
- consumer의 역할을 하는 수집 및 정제 서버에서는 producer에서 보낸 메세지를 읽는 컨슈머들을 등록하여 메세지를 읽고 데이터를 가공해서 저장하는 역할을 합니다.
- 이때, 컨슈머들을 등록하기 용이하기 위해 @Consume이라는 커스텀 데코레이터를 만들었습니다.
- 해당 데코레이터를 적용하면, 스캔 과정에서 이를 감지하여 자동으로 consumer를 초기화하는 작업이 수행됩니다.
커스텀 데코레이터
import { SetMetadata } from '@nestjs/common';
import type { ConsumeDecoratorOptions } from '#/interfaces/consume-decorator.interface';
import 'reflect-metadata';
export const CONSUME_METADATA_KEY = Symbol('KAFKA_CONSUME_METADATA');
export function Consume(options: ConsumeDecoratorOptions): MethodDecorator {
return SetMetadata(CONSUME_METADATA_KEY, options);
}
- 먼저 @Consume 데코레이터를 통해 CONSUME_METADATA_KEY 키값과 옵션값들을 SetMetadata 메서드를 통해 등록합니다.
- 이렇게 되면 nest 컨테이너가 초기화될 때 모든 메타데이터가 설정됩니다.
import { Injectable, OnModuleInit } from '@nestjs/common';
import { DiscoveryService, MetadataScanner, Reflector } from '@nestjs/core';
import { CONSUME_METADATA_KEY } from '#/decorators';
import { KafkaService } from '#/services/kafka.service';
@Injectable()
export class ConsumerInitializer implements OnModuleInit {
constructor(
private readonly kafkaService: KafkaService,
private readonly reflector: Reflector,
private readonly metadataScanner: MetadataScanner,
private readonly discoveryService: DiscoveryService,
) {}
async onModuleInit() {
const methodList: {
instance: object;
methodRef: (...args: unknown[]) => Promise<void>;
metadata: { topic: string; groupId: string };
}[] = [];
this.discoveryService.getControllers().forEach((wrapper) => {
if (!wrapper.isDependencyTreeStatic() || !wrapper.instance) {
return;
}
this.metadataScanner
.getAllMethodNames(
Object.getPrototypeOf(wrapper.instance) as object,
)
.forEach((methodName) => {
const methodRef = (
wrapper.instance as Record<
string,
(...args: unknown[]) => Promise<void>
>
)[methodName];
const metadata = methodRef
? this.reflector.get<{
topic: string;
groupId: string;
}>(CONSUME_METADATA_KEY, methodRef)
: null;
if (metadata) {
methodList.push({
instance: wrapper.instance as Record<
string,
unknown
>,
methodRef: methodRef as (
...args: unknown[]
) => Promise<void>,
metadata,
});
}
});
});
await Promise.all(
methodList.map(({ instance, methodRef, metadata }) =>
this.kafkaService.initConsumer({
groupId: metadata.groupId,
topic: metadata.topic,
autoCommit: true,
eachMessage: methodRef.bind(instance),
}),
),
);
}
}
- 이제 ConsumerInitializer를 통해 모듈이 초기화될 때 메타데이터들을 읽고, 옵션값에 맞게 컨슈머들을 초기화하는 kafkaService.initConsumer 메서드를 실행합니다.
- 대략적인 흐름은 아래와 같습니다.
flowchart TD
A[Start] --> B[discoveryService.getControllers] --> C{모든 controller}
C --> D[metadataScanner.getAllMethodNames]
D --> E{모든 Method}
E -- 전체 순회 완료 --> D
E --> F[CONSUME_METADATA_KEY 확인]
F --> |Yes| G[MethodList에 추가]
F --> |No| C_back[다음 Method]
G --> H[다음 Method]
C_back --> E
H --> E
D -- 전체 순회 완료 --> I[Promise.all로 MethodList 초기화]
I --> J[Consumer 초기화]
J --> K[EachMessage에 Method 연결]
K --> L[Consume 가능한 상태]
L --> M[End]
- discoveryService를 통해 모든 controller를 순회합니다.
- metadataScanner.getAllMethodNames를 통해 컨트롤러들 안에 있는 메서드들을 모두 가져옵니다.
- 메서드들을 순회하면서 각 메서드에 대해서 CONSUME_METADATA_KEY 메타데이터 키가 있는지 확인합니다.
- CONSUME_METADATA_KEY 메타데이터 키가 있으면 consume이 필요한 것으로 간주하고 대상 methodList에 추가합니다.
- Promise.all로 대상 methodList에 있는 정보들을 바탕으로 consumer를 초기화하여 consume 할 수 있는 상태가 되게 합니다. eachMessage에 들어가는 instance는 토픽에 발행된 메세지 컨슘 시 실행할 메서드입니다.
커스텀 데코레이터 효과?
- 예시로 아래와 같은 코드 변화가 있었습니다.
AS-IS
async onModuleInit() {
await this.kafka
.initConsumer({
groupId: 'Kafka 그룹 아이디',
topic: 'Kafka 토픽명 1',
autoCommit: true,
eachMessage: (
message: Message,
) => {
this.method1({
message,
topic: message.topic,
});
},
})
await this.kafka
.initConsumer({
groupId: 'Kafka 그룹 아이디',
topic: 'Kafka 토픽명 2',
autoCommit: true,
eachMessage: (
message: Message,
) => {
this.method2({
message,
topic: message.topic,
});
},
})
}
TO-BE
@Controller()
export class Controller {
constructor(private readonly service: Service) {}
@Consume({
topic: 'Kafka 토픽명'
groupId: 'Kafka 그룹 아이디,
})
async consumeLogMessage(message: Message) {
await this.logService.processlog({ message });
}
}
-
예시에서 볼 수 있듯, 해당 커스텀 데코레이터 덕분에 코드 중복을 방지하고 가독성을 향상시킬 수 있었는데요, 프로젝트 전반에서 일관된 패턴을 유지할 수 있어 팀 협업이 쉬워지고 관리가 용이해졌습니다.
-
기존처럼 토픽이 생길때마다 길고 중복된 initConsumer를 작성하는 것이 아니고, 메세지 컨슘시 실행할 메서드만 작성하고, 메타데이터만 달아두면 됩니다.
-
참고) 해당 커스텀 데코레이터는 아래 아티클을 읽으며 만들었습니다.

NestJS 환경에 맞는 Custom Decorator 만들기
NestJS에서 데코레이터를 만들기 위해서는 NestJS의 DI와 메타 프로그래밍 환경 등을 고려해야 합니다. 어떻게 하면 이러한 NestJS 환경에 맞는 데코레이터를 만들 수 있을지 고민해보았습니다.
initConsumer 메서드
// kafka.service
public async initConsumer({
groupId,
topic,
sessionTimeout = 30000,
heartbeatInterval = 10000,
autoCommit = true,
eachMessage,
}: InitConsumerInterface) {
const consumer = this.kafkaClient.consumer({
groupId,
sessionTimeout,
heartbeatInterval,
maxWaitTimeInMs: 1000,
});
await consumer.connect();
await consumer.subscribe({ topic, fromBeginning: false });
await consumer.run({
autoCommit,
eachMessage: async ({ message, partition, topic }) => {
const decodedMessage = await this.getDecodedMessage(message);
const decodedMessageWithTopic = {
...decodedMessage,
topic,
};
await eachMessage(decodedMessageWithTopic);
});
}
- initConsumer 메서드 구현체는 간단합니다.
- consumer를 초기화 / 연결 / 토픽 구독 / 메세지 컨슘 시 SchemaRegistry 검증 후 서버 로직을 수행하는 방식입니다.
5. 확인 및 결과
- 이렇게 구현을 마무리하고 Kafka 메세지의 produce와 consume이 잘 이루어지게 서버를 구성해두었습니다.
- 이제 해당 시스템을 통해 교육 수강 데이터가 실시간으로 축적해되며, 수강생들도 이를 즉시 확인할 수 있게 되었습니다.

실시간으로 쌓이는 데이터들 (Kafka)
5.1 사용자 경험 개선
- 사용자 입장에서는 실시간으로 데이터를 확인할 수 있어, 하루 뒤에 반영되는 배치 시스템과 달리 실시간으로 자신의 상태를 파악할 수 있었습니다. 이에 대해 긍정적인 피드백을 받았습니다. 그 결과, 자신의 교육 현황에 대한 문의가 CS로 들어오는 일이 사라졌습니다.
- 관리자 입장에서는 교육 현황을 수동으로 확인하고 개발자에게 문의해야 하는 부담이 줄어들어 운영 효율성이 향상되었습니다.
- 더불어, 수강생들의 교육 진행 상황을 실시간으로 파악할 수 있어 즉각적인 피드백 제공이 가능해졌으며, 필요한 추가 학습이나 조치를 빠르게 안내할 수 있었습니다.
유저들에게 개선된 사용 경험을 제공해보았다.
5.2 데이터베이스 부하 개선
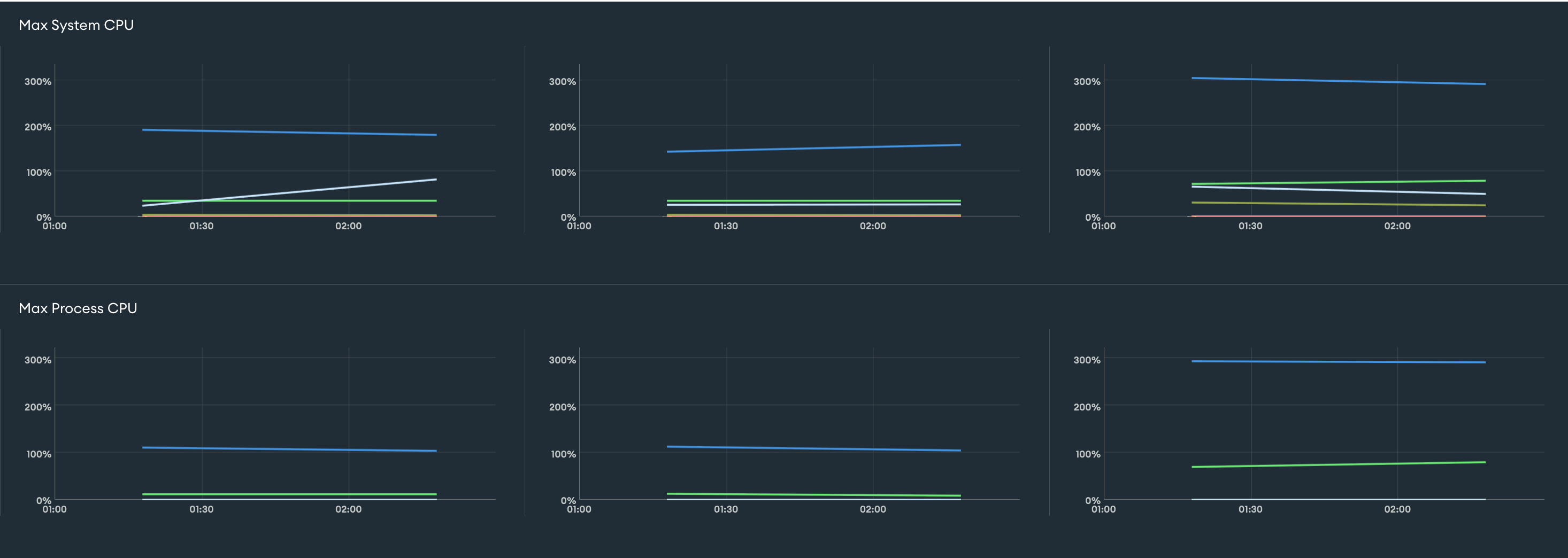
부하가 줄지는 않았다.
- 사실 위에서 볼 수 있듯이 부하가 눈에 띄게 감소하지는 않았습니다.
- 이는 사내 주요 서비스들이 동일한 데이터베이스 클러스터를 공유하고 있어 정확한 지표로 보기 어렵기 때문이며, 기존에 사용하던 배치 서버가 아직 종료되지 않았기 때문이기도 합니다.
- 현재까지는 데이터를 이중으로 관리하며 누락된 데이터를 보완할 수 있도록 유지하는 방향이 팀과 조직의 결정이었으며, 사실 다른 팀의 필요로 인해 배치 서버는 계속해서 추가되고 있습니다.
- 데이터베이스 부하를 완전히 해결하지는 못했지만, 장애 발생 수준이었던 초기 800%에서 크게 개선된 것은 의미 있는 변화라고 생각합니다.
- 상용 서비스에서는 일정 수준의 부하는 필연적이지만, 가능하면 더 나은 해결 방안을 지속적으로 고민할 계획입니다.
6. 결론 및 후기
- 문제 상황을 해결하기 위해 새로운 방안을 고민하고 직접 설계 및 구현하는 경험을 할 수 있었습니다.
- 특히 Kafka를 비롯한 여러 인프라 요소에 대한 기술 연구와 리서치를 진행하며, 설계부터 구현까지의 과정을 경험하면서 더욱 성장할 수 있었습니다.
- 구현도 중요하지만, 요구사항을 충족하는 전체적인 아키텍처를 구상하고 설계하는 능력이 앞으로 개발자로 성장하는 데 핵심적인 역량인 것 같습니다.
- 이번 경험을 통해 직접 설계하고 구현해 보면서 이러한 역량의 중요성을 더욱 실감할 수 있었고, 앞으로도 이를 지속적으로 발전시키고 싶습니다.