

배치 서버를 간단하고 빠르게 구축해보자 (feat. Bull Queue)
1. 들어가며
- 저희 회사에는 매일매일 데이터를 수집하고 API를 통해 해당 데이터를 제출해야 하는 업무가 있었습니다.
- 하지만 이 작업은 완전히 수동으로 이루어졌기 때문에, 반복되는 과정 속에서 개발 경험이 매우 좋지 않았습니다.
- 이러한 불편함을 개선하기 위해 자동화된 배치 서버를 구축하게 되었고, 이 글에서는 그 과정에서 겪은 고민과 결과를 공유하려고 합니다.
2. 문제 상황
- 처음에는 개발자가 직접 스크립트를 실행하여 데이터 수집, 검증, 제출을 처리했지만, 이 방식에는 문제가 있었습니다.
DX 저하
- 스크립트 자체는 잘 작성되어 있어 실행에는 문제가 없었지만, 매번 수동으로 작업을 실행하는 것은 개발 경험에 부정적인 영향을 미쳤습니다.
- 단순 반복 작업은 개발자의 생산성을 저하시키는 것은 물론, 실수의 가능성을 높이는 요인이 됩니다. 실제로 이 과정에서 여러 차례 실수가 발생한 적도 있었습니다.
- 새로운 데이터 유형이 추가되거나 요구 사항이 변경될 때마다 스크립트를 수정해야 했습니다. 이러한 방식은 관리가 어려웠고, 작성자가 아닌 다른 사람이 코드를 쉽게 이해하기 어려운 문제도 있었습니다.

스크립트는 문제를 잠시만 해결해줄 뿐이야
데이터베이스 부하
-
대량의 데이터 읽기/쓰기가 동시에 이루어져 데이터베이스에 과도한 부하가 발생 했습니다.
- 특히 서비스 트래픽이 집중될 때, 추가적인 데이터 작업으로 인해 서비스 속도가 느려지거나 장애가 발생하는 경우도 있었습니다.
-
참고로, 저희가 사용하는 mongoDB Atlas의 Cluster Tier은 M50으로, Version은 6.0.20, Region은 ap-northeast-2입니다.
- M50의 상세 스펙으로는 Storage Range은 10 GB ~ 4 TB, Default Storage은 160GB, Default RAM은 32GB입니다.
- 아래는 기존 스크립트를 돌렸을 때 발생 했던 문제들입니다.
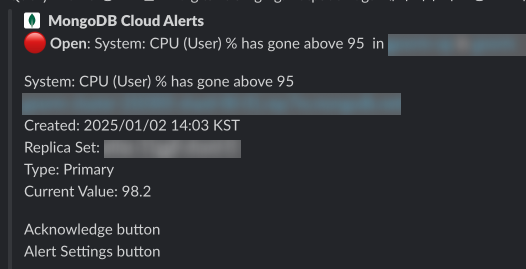
데이터베이스가 많이 아파요
- 스크립트를 실행하던 중 CPU 사용률이 비정상적으로 상승했고, 긴장된 마음으로 지표를 확인했습니다.
장애에 대한 보고서를 쓰러 갑시다..
-
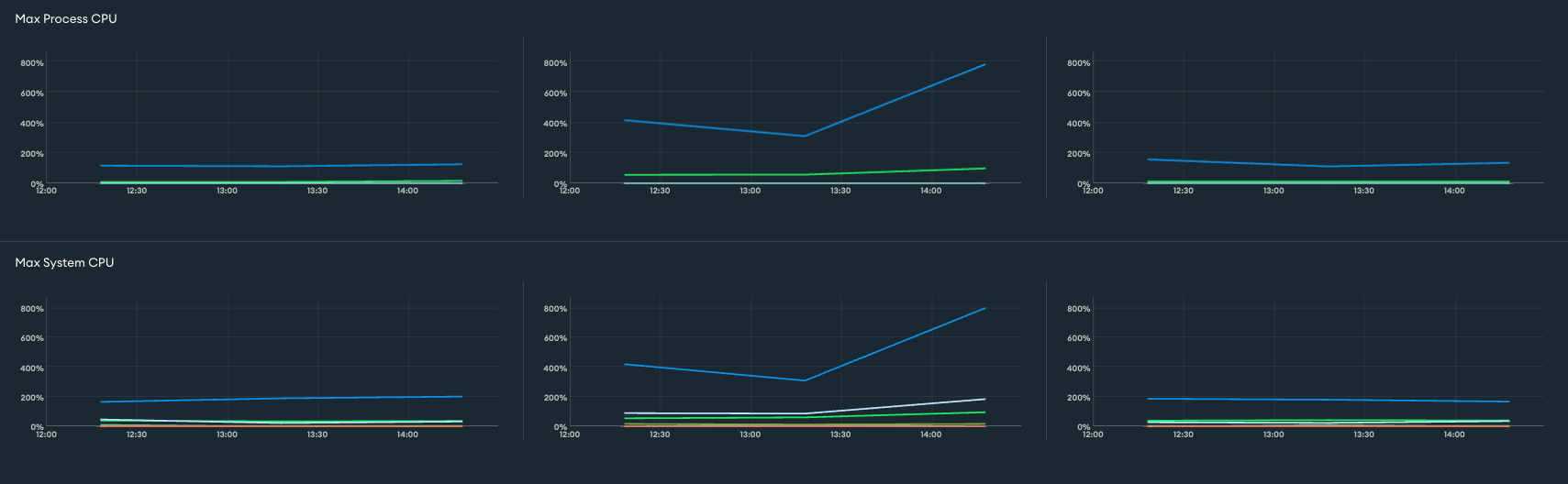
CPU 사용률이 800%까지 치솟아 서비스에 일시적인 장애가 발생하였었는데요, 원인을 분석한 결과 인덱스 설정의 부족과 대량의 읽기/쓰기 작업이 데이터베이스에 한꺼번에 몰린 점에서 비롯되었습니다.
-
우선 작업을 중단하고 슬로우 쿼리가 발생하는 지점을 확인하였습니다. 인덱스가 부족한 것을 확인하고 추가하여 장애를 일시적으로 해결했지만, 장기적인 관점에서 스크립트의 동작 방식을 개선할 필요가 있었습니다.
-
CPU에 이어서 추가적으로 장애가 발생했던 상황에서 지표들을 확인해보았는데요, Disk IOPS / Disk Latency / Connections / Query Execution Times / System Memory에 대해서 살펴보았습니다.
디스크 I/O 관련 지표
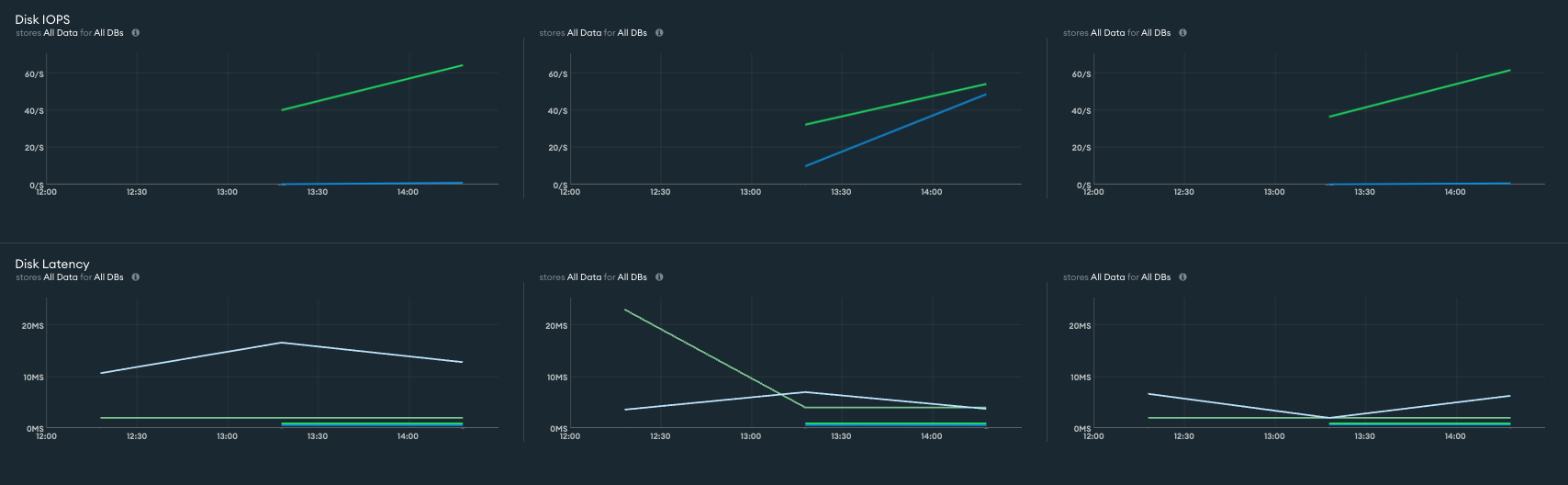
- Disk IOPS
- 초당 디스크 작업 수로, IOPS가 높으면 디스크 작업이 과도하게 수행되고 있음을 나타냅니다.
- write가 초당 60개 정도로 나쁘지 않은 지표로 보입니다.
- Disk Latency
- 디스크 작업의 대기 시간으로, 이 값이 높으면 디스크 병목이 발생했을 가능성을 나타냅니다.
- Write Max latency가 18ms정도로 평소보다 쓰기 지연으로 인해 쓰기 성능이 저하되었음을 확인할 수 있습니다.
MongoDB 성능 관련 지표
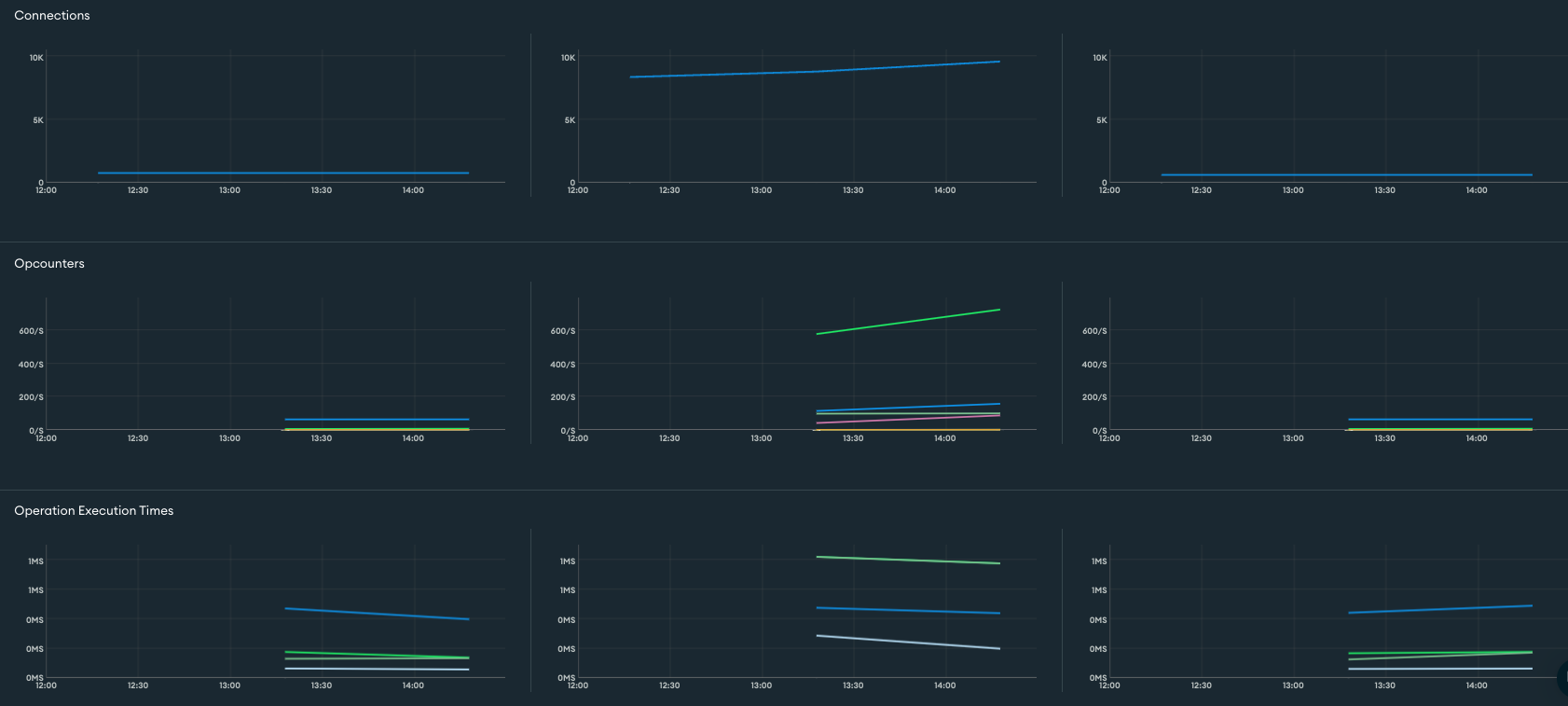
- Connections
- 현재 활성 연결 수로, 너무 많으면 MongoDB가 연결을 처리하는 데 과부하가 걸릴 수 있습니다.
- 평소 2000~3000개의 커넥션을 맺고 있어 문제되지 않는 지표로 보입니다.
- OpCounters
- 초당 읽기/쓰기/삭제 작업의 수입니다.
- 트래픽이 몰리는 시간대가 아닌만큼, 초당 쿼리가 약 3000~4000개가 나가는 평소보다 적은 수치인 600개로 나타나고 있습니다.
- Query Execution Times
- 초당 쿼리 실행 시간입니다.
- Write 쿼리에 있어 1ms로 나쁘지 않은 지표로 보입니다.
메모리 관련 메트릭

- System Memory
- 시스템 전체의 메모리 상태를 보여줍니다. 지표에서는 물리적 메모리 중 몇 바이트를 사용하고 있는지 보여줍니다.
- 사용량은 25.49GB로 평소에는 8~9GB의 메모리를 사용하는 것을 감안하면 많은 물리적 메모리를 사용하는 것을 확인할 수 있습니다.
결론
- 지표 분석 결과, CPU와 메모리 사용량의 급증이 주요 문제가 되었습니다.
- MongoDB와 디스크 I/O는 이로 인한 간접적인 부하를 받은 것으로 보이며, 쿼리 성능 자체에는 큰 문제가 없는 것으로 파악되었습니다.
- CPU와 메모리 사용량 급증의 주된 원인은 비동기적으로 과도한 작업을 동시에 실행한 점입니다.
- 스크립트는 대상 유저의 데이터를 수집하는 역할을 했었는데요, 예상보다 많은 유저가 대상에 포함되면서 대량의 쿼리가 발생하게 되었습니다.
3. 어떻게 해결할 것인가?
- 위에서 살펴본 지표를 바탕으로, Batch Insert/Update 방식 최대 활용하고, 작업 스케줄링을 추가하여 서버 부하를 완화하고 문제를 해결할 수 있을 것으로 판단했습니다.
- 기존 스크립트를 폐기하고, 쿼리 부하를 줄이고 작업을 효과적으로 관리하기 위해 큐를 활용한 배치 처리 방식으로 전환하여 구축하기로 결정했습니다.
- 목표는 아래와 같이 설정해두었습니다.
- 기존 스크립트가 제공하던 기능을 그대로 유지할 것.
- 작업을 개발자가 수동으로 실행하지 않고, 특정 시간에 스케줄링되어 자동으로 실행될 수 있도록 할 것.
- 대량의 데이터 작업이 데이터베이스에 부하를 주지 않도록 설계할 것.
- 가능한 빠르게 개발을 완료해 실무에 적용할 수 있을 것.
3.1 nestJS
- 위에서 언급한 목표를 달성하기 위해 NestJS를 선택했습니다.
- 프레임워크를 선택하는 과정에서 Express, Koa 등도 고려했지만, 가능한 빠르게 개발을 완료하는 것이 목표였기 때문에, 보일러플레이트가 잘 갖춰져 있고 다양한 기능을 기본적으로 제공하는 프레임워크가 필요했습니다.
- 저희가 필요한 기능은 스케줄러와 큐잉 시스템이었는데요, 물론 Express나 Koa에서도 이러한 기능을 구현하는 것은 가능하지만, NestJS는 이미 이 기능들을 모듈 형태로 래핑해 제공하고 있어 개발 속도를 더 빠르게 끌어올릴 수 있었습니다.
- 덕분에 불필요한 구현 과정을 줄이고, 핵심 로직 개발에만 집중할 수 있었으며, 결과적으로 개발을 더 신속하게 마무리할 수 있었습니다. NestJS를 선택한 것은 적절한 판단이었다고 생각합니다.

3.2 Bull Queue
- 대량의 데이터 작업이 데이터베이스에 부하를 주지 않도록 하기 위해 큐 시스템 도입을 고려했습니다.
- 여러 옵션 중 Bull Queue를 선택했으며, Kafka나 AWS SQS와 같은 대안도 검토했지만, 최종적으로 Bull Queue를 선택한 이유는 아래와 같습니다.
- Kafka는 고가용성을 제공하며, 실시간 데이터 처리에 강점이 있지만, 우리가 해결하려는 문제는 배치성 작업이었고, 작업이 순서대로 실행되어야 한다는 점에서 Bull Queue가 더 적합하다고 판단했습니다.
- AWS SQS는 관리형 서비스로 편리하지만, 비용 문제와 함께 Bull Queue가 필요로 하는 redis가 이미 우리 환경에 구축되어 있다는 점에서 우선순위에서 밀렸습니다.
- NestJS에서는 이미 NestJS의 Bull 모듈을 통해 Bull Queue를 쉽게 사용할 수 있도록 이미 래핑된 형태로 제공하고 있었고, 해당 모듈 덕분에 간단하고 빠르게 개발할 수 있었습니다.
- 이러한 이유로 Bull Queue를 선택하여 작업의 효율성과 개발 속도를 모두 충족시킬 수 있었습니다.
3.3 Bull Queue의 기본 구성요소
- 기본적인 구성요소로는 아래와 같습니다.
- Queue: 작업(Job)을 저장하고 관리하는 공간 (Redis 리스트 활용)
- Job: 큐에 추가된 개별 작업 (JSON 형태로 저장)
- Worker: 큐에서 Job을 가져와 실행하는 프로세스
- Events: Job 상태 변화를 감지 (completed, failed, delayed 등)
- Scheduler: 예약된 작업을 관리하는 역할
3.4 Bull Queue의 동작 방식
- 이러한 구성요소들을 가지고 Bull Queue는 어떻게 동작할까요?
- Job 추가 (Producer)
- queue.add(data) 메서드 호출 시, Redis의 LIST 자료구조(LPUSH 또는 RPUSH)에 데이터가 저장됩니다.
- Job에는 id, data, attempts 등의 메타데이터 포함됩니다.
- Job 처리 (Worker)
- Worker는 Redis의 BRPOPLPUSH를 사용해 대기 중인 Job을 가져옵니다.
- Job 실행 후 성공하면 completed 상태로 변경, 실패하면 failed로 변경합니다.
- 실패한 Job은 재시도가 가능합니다.
- Job 상태 관리
- 실행 중인 Job은 active 상태로 전환됩니다.
- 성공 시 completed 리스트로 이동합니다.
- 실패하면 failed 리스트로 이동하고, 최대 재시도 횟수를 초과하면 stalled 상태 처리 가능합니다.
- 이벤트 발생
- on('completed', callback) → Job이 완료되면 이벤트 발생합니다.
- on('failed', callback) → Job이 실패했을 때 이벤트 발생합니다.
- on('stalled', callback) → 워커가 멈춘 경우 감지합니다.
- Job 추가 (Producer)
3.5 Bull Queue가 사용하는 Redis 자료구조
-
그렇다면 Redis에는 정확히 어떠한 자료구조로 저장될까요?
- Bull은 Redis의 다양한 자료구조를 활용합니다.
- 대기 중인 Job 목록 → LIST (bull:queue_name:wait)
- 실행 중인 Job 목록 → LIST (bull:queue_name:active)
- 완료된 Job 목록 → ZSET (bull:queue_name:completed)
- 실패한 Job 목록 → ZSET (bull:queue_name:failed)
- 지연된 Job 목록 → ZSET (bull:queue_name:delayed)
- Bull은 Redis의 다양한 자료구조를 활용합니다.
-
(참고) bulljs의 소스코드를 보면 알 수 있습니다.
/**
Gets or creates a new Queue with the given name.
The Queue keeps 6 data structures:
- wait (list)
- active (list)
- delayed (zset)
- priority (zset)
- completed (zset)
- failed (zset)
--> priorities -- > completed
/ | /
job -> wait -> active
\ ^ \
v | -- > failed
delayed
*/
3.6 Bull Queue가 순차적으로 처리하는 순서
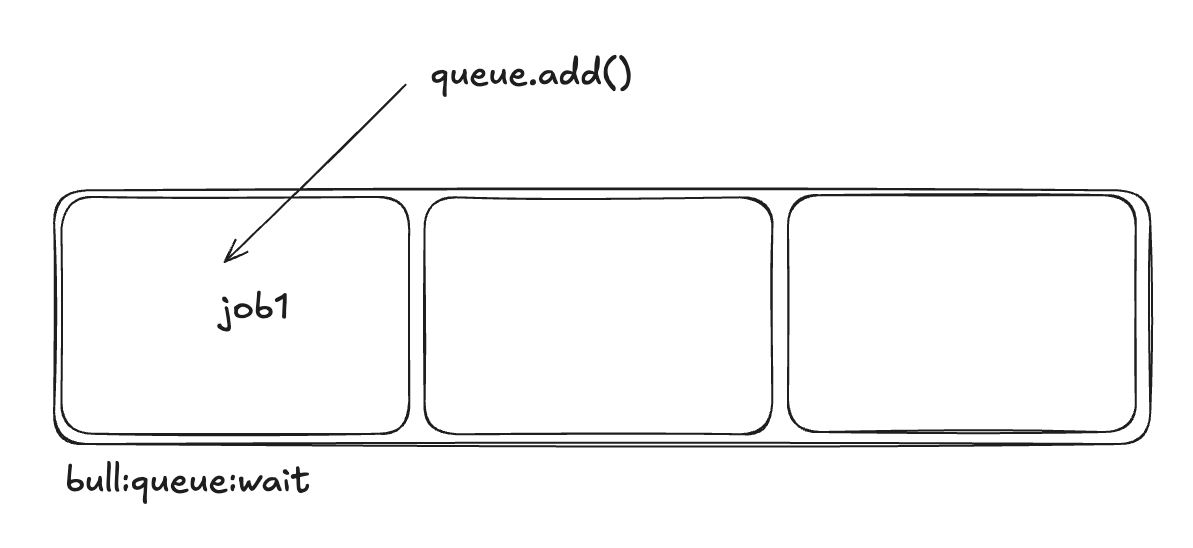
1. queue.add(data) 호출
- queue.add()를 실행하면 Redis의 LIST(bull:queue_name:wait)에 Job이 저장됩니다.
- Job이 처음 들어가는 상태는 대기 상태입니다.
- 참고로 디폴트로 FIFO로 실행되고, lifo: true 옵션을 주면 LIFO로 실행됩니다. 여기서는 큐의 목적으로 사용되는 것 만큼 FIFO로 설명하겠습니다.
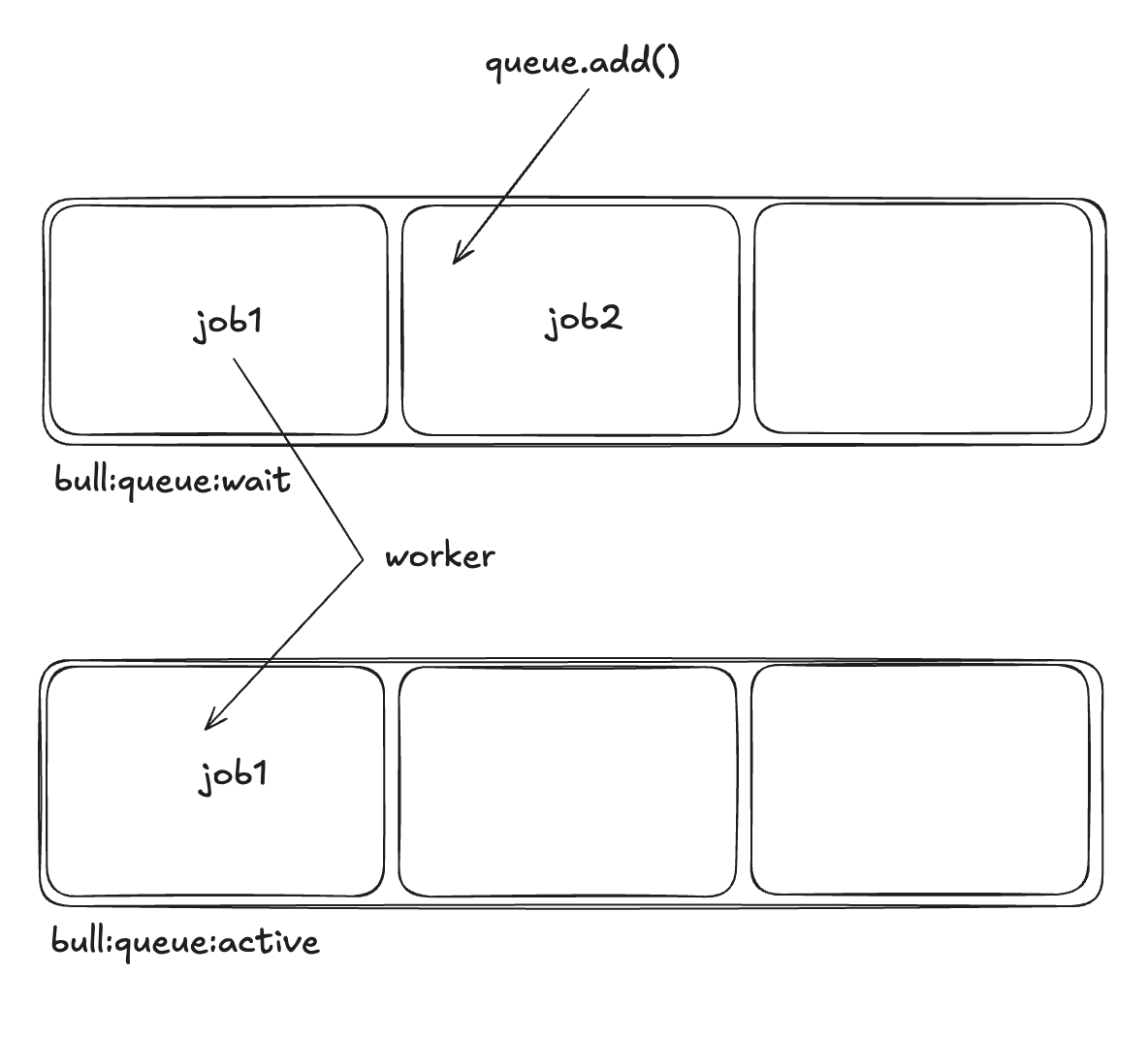
2. Worker가 Job을 실행
- Worker가 실행되면 wait 리스트에서 하나의 Job을 가져옵니다.
- 가져온 Job은 active 상태로 이동합니다. (bull:queue_name:active 리스트에 저장됨).
- 결과적으로 wait에서 active 로 상태 변경됩니다.
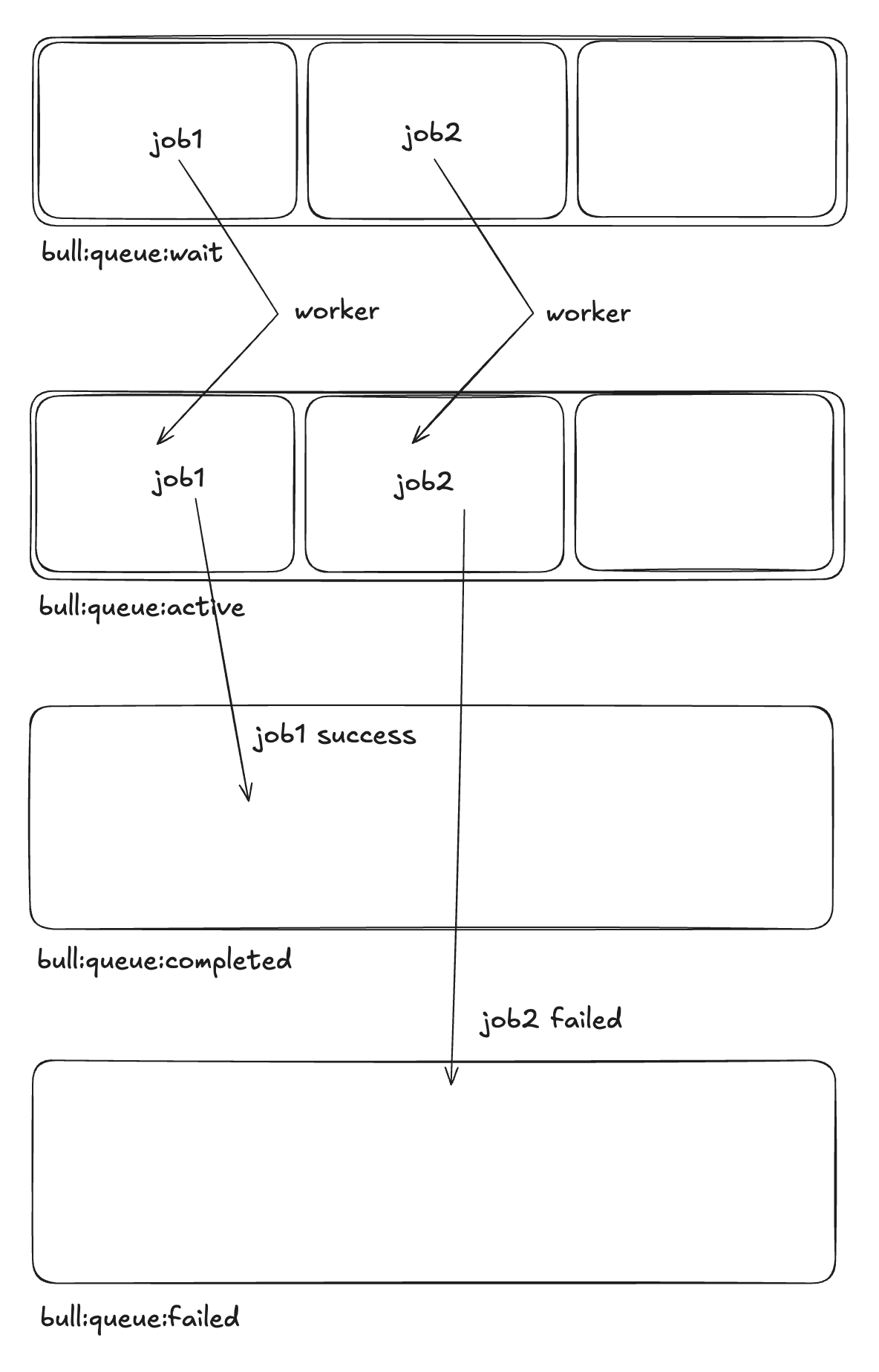
3. 성공 혹은 실패 상태로 이동
- active 상태에서 처리한 Job이 성공하면 completed / 실패하면 failed로 들어갑니다.
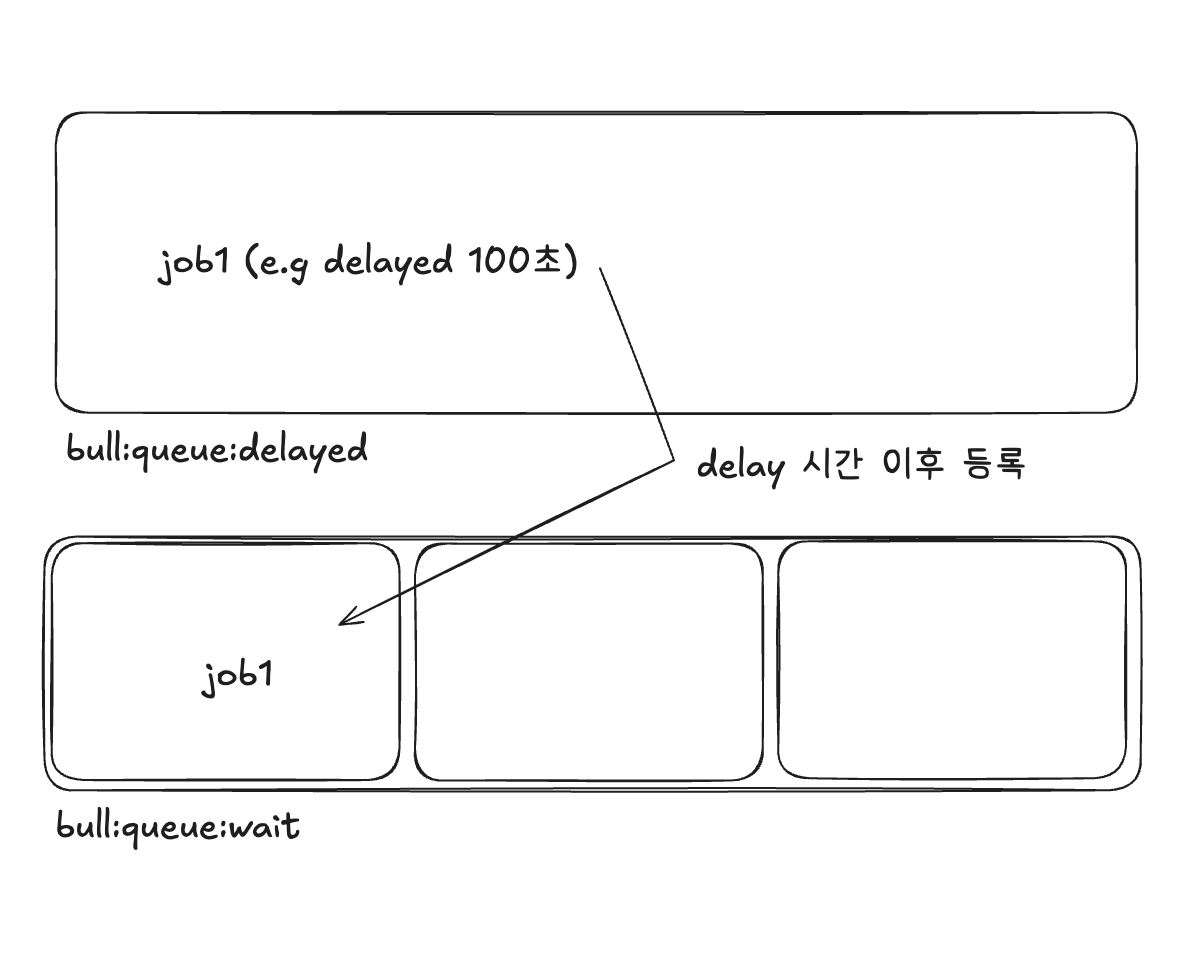
4. 지연된 목록
- queue.add()를 실행할때,delay: 시간 옵션을 줄 수 있는데요, 해당 옵션을 통해 Job을 등록하면 우선 bull:queue_name:delayed로 들어갑니다.
- 이후 지정한 시간이 지나면 wait 큐에 들어가게 됩니다.
4. 구현
- 이제 실제 구현을 해보겠습니다!
4.1 module
import { BullModule } from '@nestjs/bull';
import { Module } from '@nestjs/common';
import { ScheduleModule } from '@nestjs/schedule';
import { ExpressAdapter } from '@bull-board/express';
import { BullBoardModule } from '@bull-board/nestjs';
import { LoggerModule } from './logger.module';
@Module({
imports: [
...
ScheduleModule.forRoot(),
BullModule.forRoot({
redis: {
host: process.env.REDIS_HOST,
port: Number(process.env.REDIS_PORT || 6379),
},
defaultJobOptions: {
removeOnComplete: 50000,
},
}),
BullBoardModule.forRoot({
route: '/queues',
adapter: ExpressAdapter,
}),
...
LoggerModule,
],
controllers: [],
providers: [],
})
export class AppModule {}
- 우선 루트모듈에 필요한 모듈들을 등록합니다.
import { BullModule } from '@nestjs/bull';
import { BullBoardModule } from 'nestjs-bull-board';
import { CollectModule } from './collect/collect.module';
@Module({
imports: [
BullModule.forRoot({
redis: {
host: process.env.REDIS_HOST,
port: Number(process.env.REDIS_PORT || 6379),
},
}),
BullBoardModule.forRoot(),
CollectModule,
],
})
export class AppModule {}
- BullModule와 BullBoardModule 등록합니다.
- defaultJobOptions.removeOnComplete는 50000으로 두었는데요, 해당 옵션은 완료된 작업 중 최근 N개만 유지하고 그 외 작업 기록은 Redis에서 자동 삭제하도록 설정하는 값입니다.
- 하루에 약 5만개 정도의 데이터가 쌓이기 때문에 검증용 및 재시도용으로 하루치를 남겨두고 redis의 메모리 확보를 위해서 불필요한 데이터는 삭제하도록 하였습니다.
- 실제 운영 환경에서 redis 메모리를 효율적으로 관리하기 위해서 정책적으로 필요한 만큼만 가져가기로 했습니다.
- BullBoardModule은 Bull Queue 상태를 실시간으로 모니터링 및 관리할 수 있는 UI를 제공하는 툴입니다.
import { ScheduleModule } from '@nestjs/schedule';
@Module({
imports: [
ScheduleModule.forRoot(),
// Other modules...
],
})
export class AppModule {}
- 크론잡을 손쉽게 등록할 수 있게 해주는 ScheduleModule도 등록합니다.
- ScheduleModule로 작업 예약하고 Bull Queue를 통해 작업 처리를 진행합니다.
- ScheduleModule이 Bull Queue의 Producer 역할을 한다고 보고, Queue에서 작업 실행을 제어하는 방향으로 구현할 예정입니다.
@Module({
imports: [
BullModule.registerQueue({
name: 'scoreCollect',
limiter: {
max: 5,
duration: 1000,
},
}),
BullBoardModule.forFeature({
name: 'scoreCollect',
adapter: BullAdapter,
}),
...
],
controllers: [],
providers: [
// Consumers
ScoreCollectConsumer,
// Services
ScoreCollectService,
...
],
exports: []
})
export class CollectModule {}
- 이제 BullModule에 registerQueue를 통해 histScoreCollect라는 특정 큐를 만들어줍니다.
- Redis에 과도한 부하를 방지하며, DB 읽기 / 쓰기가 많은 작업이기 때문에 시스템 안정성을 보장하기 위해 limiter.max: 5 limiter.duration: 1000 옵션을 통해 1초에 5개의 작업만 처리하도록 제한해두었습니다.
- 추가적으로 등록한 큐를 BullBoard에서 확인할 수 있도록 등록해두었습니다.
4.2 service
import type { Queue } from 'bull';
...
@Injectable()
export class ScoreCollectService {
constructor(
@InjectQueue('scoreCollect')
private readonly scoreCollectQueue: Queue<ScoreCollectJob>,
) {}
@Cron(CronExpression.EVERY_DAY_AT_1AM, {
name: 'collectHistScore',
timeZone: 'Asia/Seoul',
})
collectScoreDaily() {
const collectDateUTC = dayjs.tz(collectDate).add(-9, 'hour');
const userIds = await this.findCollectScoreTargetUsers(collectDateUTC);
userIds.map((userId: string) => {
this.scoreCollectQueue.add(
{
userId,
collectDate: dayjs(collectDate).format('YYYY-MM-DD'),
},
{ removeOnComplete: true, removeOnFail: true },
);
});
}
}
- schedule 모듈의 @Cron을 활용해서 매일 오전 1시에 특정 메서드가 실행 되도록 크론 작업을 걸어둡니다.
- 조회된 유저 ID 목록을 기반으로, 각 유저별로 개별 작업인 Job을 생성하여 Bull Queue인 scoreCollectQueue에 적재합니다.
- removeOnComplete: true 옵션의 경우 작업이 성공적으로 완료되었을 때, 해당 작업 데이터를 큐에서 자동으로 삭제합니다. 해당 설정은 큐가 불필요한 데이터로 인해 메모리 및 저장 공간을 낭비하지 않도록 해줍니다.
- removeOnFail: true 옵션의 경우 작업이 실패한 경우에도 큐에서 해당 작업 데이터를 자동으로 삭제합니다. 이 또한 실패한 작업 로그를 별도로 저장하지 않아도 되는 간단한 처리 로직에서 유용합니다.
4.3 consumer
@Processor('scoreCollect')
export class ScoreCollectConsumer {
constructor(
private readonly scoreCollectService: ScoreCollectService,
@Inject(Logger) private readonly logger: LoggerService,
) {}
@Process()
async onProcess(job: Job<ScoreCollectJob>) {
const { userId, collectDate } = job.data;
const currentCollectDate = dayjs(collectDate).tz();
await this.scoreCollectService.collectScoreByUser(
userId,
currentCollectDate,
);
}
@OnQueueActive()
onActive(job: Job<ScoreCollectJob>) {
const { userId, collectDate } = job.data;
this.logger.log(
{
message: 'ACTIVE',
state: 'score-collect-active',
jobId: job.id,
userId,
collectDate,
},
'ScoreCollectConsumer',
);
}
@OnQueueCompleted()
async onCompleted(
job: Job<ScoreCollectJob>,
result: ScoreCollectResult,
) {
const { userId, collectDate } = job.data;
this.logger.log(
{
message: 'SUCCESS',
state: 'score-collect-success',
jobId: job.id,
userId,
collectDate,
result,
},
'ScoreCollectConsumer',
);
}
@OnQueueFailed()
async onFailed(job: Job, error: Error) {
const { userId, collectDate } = job.data;
this.logger.error(
{
message: 'FAIL',
state: 'score-collect-failed',
jobId: job.id,
userId,
collectDate,
error,
},
error.stack,
'ScoreCollectConsumer',
);
}
}
- ScoreCollectConsumer는 ScoreCollect 큐의 작업을 처리하는 Consumer입니다.
- onProcess에서는 유저별 작업을 꺼내와 ScoreCollectService로 실제 작업을 위임합니다.
- 큐에서 꺼내올때 Consumer에서는 날짜 포맷팅과 같은 작은 작업을 처리하고, 데이터베이스 읽기 / 쓰기와 복잡한 서비스 로직 처리와 같은 무거운 작업의 경우 service 객체에서 처리합니다.
- 또한, 작업의 상태(활성, 완료, 실패)를 감지하여 로그로 기록해주는 이벤트 핸들러(@OnQueueActive, @OnQueueCompleted, @OnQueueFailed)도 함께 구현하여 로깅 및 디버깅에 활용하였습니다.
5. 확인 및 결과
- 이제 특정 시간이 되면 스케줄러에 등록된 메서드가 실행되어 해당 메서드에서는 큐에 작업을 등록하고, 큐에서 작업이 하나씩 컨슈머를 통해 소비되어 작업을 진행하게 됩니다.
- 해당 작업은 다음과 같이 bull dashboard에서 이루어지는 것을 확인할 수 있습니다.
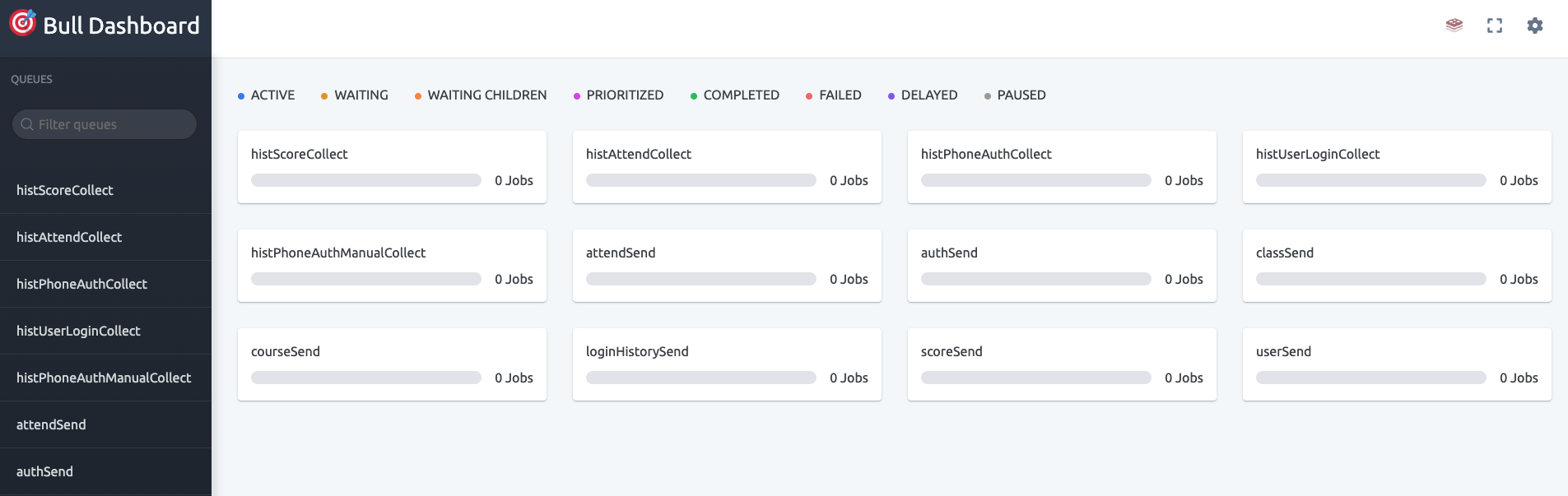
실시간으로 큐가 처리되는 것을 확인할 수 있다.
5.1 DX 개선
- DX 개선에 대해서는 수치로 표현할 수 없지만, 구성원들이 모두 입을 모아 개선된 상황에 대해서 공감하고 편리함을 느꼈습니다.
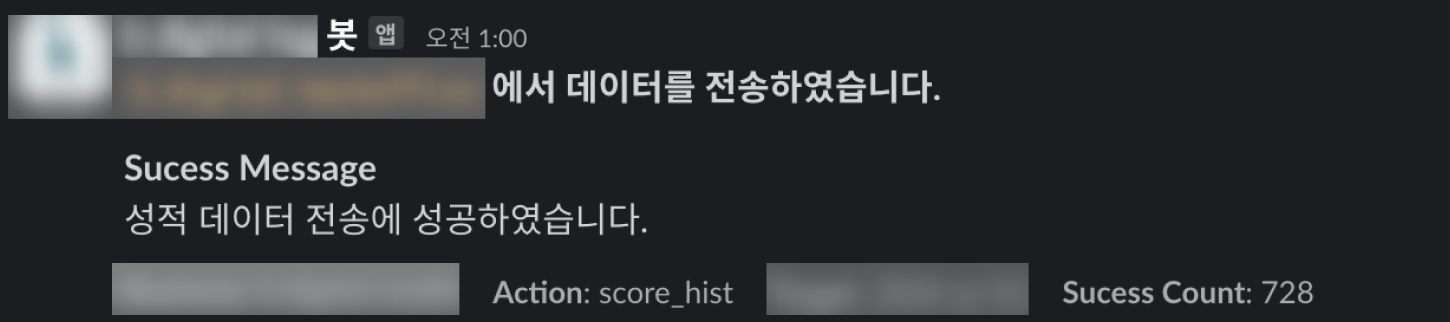
batch에 대한 결과를 슬랙 메세지를 통해서 확인하고 데이터만 확인하면 되기 때문에 훨씬 편해졌습니다!
- 개발자가 수동으로 처리하던 작업을 매일 자동으로 실행하도록 설정하여, 이제 개발자는 결과만 확인하면 되는 환경이 되었습니다.
- 이를 통해 개발 경험이 크게 개선되었으며, 운영 피로도 또한 감소하였습니다.
- 팀원들 역시 반복적인 업무 부담이 줄어들어, 다른 중요한 업무에 더 집중할 수 있는 환경이 조성되었습니다.

쉬워..졌나?
5.2 부하 발생 해결
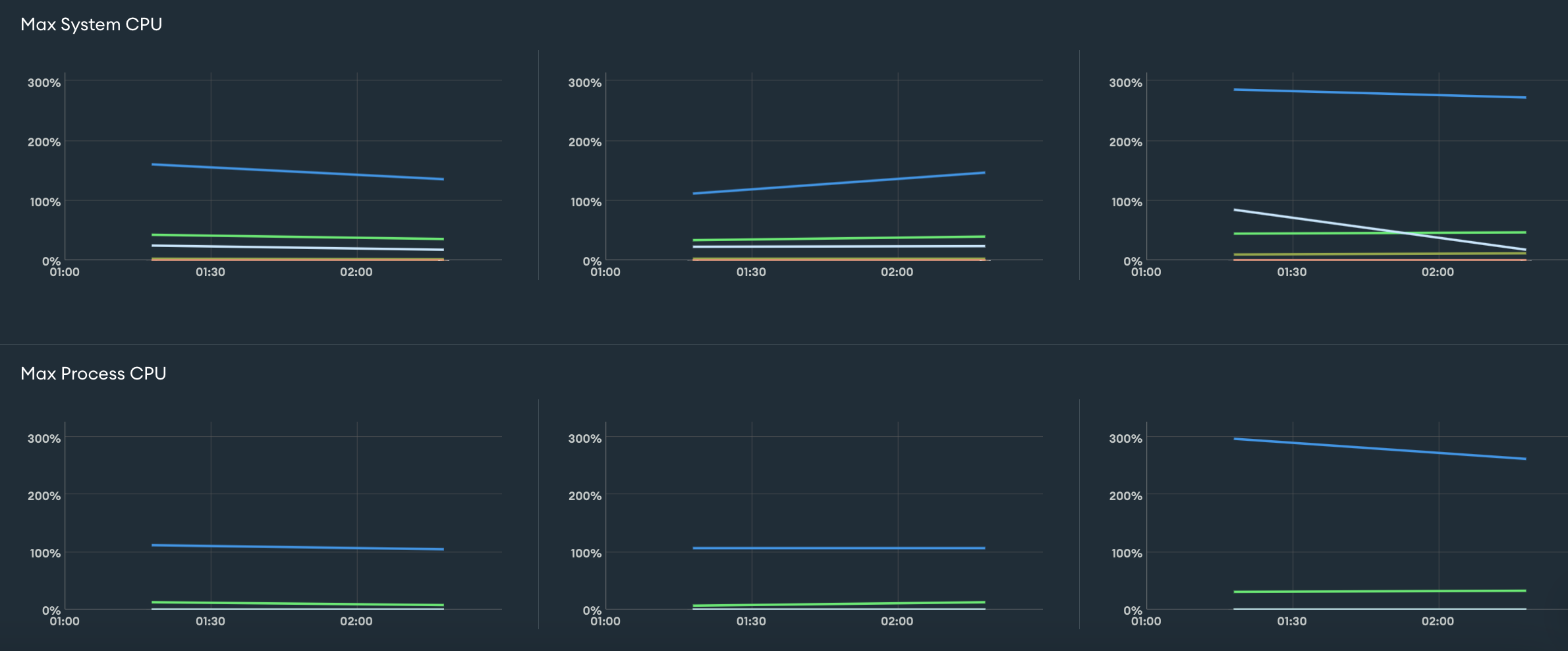
더이상 데이터베이스가 많이 아프지 않아요
- 대량의 데이터 읽기/쓰기 작업이 동시에 이루어지면서 데이터베이스에 과도한 부하가 발생했었는데요, 이를 개선하기 위해 큐를 활용한 분산 처리 방식을 도입한 결과, 10분 걸리던 스크립트를 3분만에 처리하며 처리 시간이 약 70% 단축되었고 CPU 사용률은 800%에서 안정적인 100~200% 수준(최대 300%)으로 낮아져, 서비스 운영이 한층 원활해지고 데이터 처리의 안정성을 확보할 수 있었습니다. 이로 인해 더 이상 슬랙을 통한 경고 메시지가 발생하지 않았습니다.
6. 아직 남은 과제
- 초기 배치 시스템에서는 작업이 자주 실패하거나 로직 오류로 인해 데이터가 잘못 적재되는 문제가 있었습니다.
- 이러한 문제를 해결하기 위해, 백오피스 기능을 통해 실패한 배치 작업을 다시 실행할 수 있는 기능을 추가했습니다.
- 이 백오피스를 활용하여 잘못 수집된 데이터를 삭제하고, 다시 수집함으로써 데이터의 일관성과 멱등성을 유지하려고 노력했습니다.
- 다행히 배치 작업이 안정화되었지만, 복구 백오피스는 이후 예외 상황에서 매우 유용하게 사용되어 중요한 역할을 했습니다.
7. 결론 및 후기
- 사내에서 운영 중인 해당 서비스는 가장 많은 트래픽과 데이터를 처리하고 있지만, 대규모 트래픽이라고 보기에는 다소 부족한 면이 있습니다.
- 대규모 트래픽을 경험하는 것도 중요하지만, 그러한 기회는 쉽게 찾아오지 않는다고 생각합니다.
- 다만, 시스템의 규모와 상관없이 부하 지점을 정확히 파악하고 이를 개선할 수 있는 역량을 갖추는 것이 더 중요하다고 생각합니다.
- 이번 기회를 통해 데이터베이스의 지표를 분석하고, 시스템의 부하 지점을 정의하며, 이를 해결하기 위한 새로운 방법을 고민하고 설계, 구현해보는 값진 경험을 할 수 있었습니다.
- 물론 더 나은 방법이 있었을 수도 있고, 지표를 잘못 해석했을 가능성도 있습니다.
- 하지만 이러한 과정 속에서 운영을 통해 지속적으로 분석하며, 보다 나은 방향으로 서비스를 개선해 나갈 계획입니다.
- 물론 더 나은 방법이 있었을 수도 있고, 지표를 잘못 해석했을 가능성도 있습니다.