

마케팅 트래킹을 위한 고정 URL 적용해보기
들어가며
운영 중인 모집 및 설문조사 서비스에서는 각 설문 폼에 대해 고유한 ID를 URL에 포함시키는 방식을 사용해왔습니다.
예를 들어, 구글 폼처럼 https://docs.google.com/forms/d/고유ID와 같이 각 폼이 고유하게 식별되는 구조입니다. 이러한 구조는 각 설문을 독립적으로 관리하고, 개별 응답을 손쉽게 추적할 수 있다는 장점이 있습니다.
하지만 저희 서비스의 경우, 구글 폼과는 달리 동일한 내용의 폼을 여러 회차에 걸쳐 반복적으로 사용하는 특성이 있습니다.
예를 들어, 하나의 교육과정이 여러 회차(1회차, 2회차, 3회차 등)로 운영될 때, 각 회차마다 별도의 고유 ID를 가진 URL(submission/1, submission/2, submission/3 등)이 생성됩니다.
어떤 문제점들이 있어서?
회차별로 URL과 데이터가 분산되면, 데이터를 본래 목적에 맞게 일관성 있게 수집·분석하기 어렵고, 마케팅에 활용할 수 있는 신뢰도 높은 지표를 얻기 힘듭니다. 또한 DA팀의 DX 업무 효율이 저하되며, 외부 분석 도구 역시 이러한 분산 구조로 인해 분석에 한계가 발생합니다.
마케팅 지표의 신뢰성
마케팅 팀에서는 UTM 파라미터를 활용해 광고별 효과와 유입 경로를 체계적으로 추적하고 있습니다. 이를 통해 어떤 광고가 더 효과적인지, 어떤 채널을 통해 유입이 많이 발생하는지 등 다양한 마케팅 성과 지표를 지속적으로 분석할 수 있습니다.
하지만, 과정(기수)이 바뀔 때마다 URL이 변경된다면, 동일한 지원서임에도 불구하고 유입 데이터가 분산되어 수집됩니다. 이로 인해 아래와 같은 문제가 발생할 수 있는데요,
첫번째는 지표의 일관성 저하로, 동일한 마케팅 활동임에도 URL이 달라지면 데이터가 여러 지점에 분산되어 실질적인 성과 분석이 어려워집니다.
두번째는 추가 변수 발생으로, URL 변경이 새로운 변수로 작용해 실제 광고 효과와 무관한 데이터 변동이 생길 수 있습니다.
마지막으로는 성과 비교의 어려움입니다. 기수별로 URL이 다르면, 기간별·캠페인별 성과를 정확히 비교하기 어렵습니다.
따라서, 과정별(기수별)로 URL을 통일하면 데이터가 한 곳에 집계되어 분석의 일관성과 신뢰성이 크게 높아집니다. 이는 마케팅 지표의 신뢰도를 유지하고, 효과적인 의사결정을 내리는 데 매우 중요한 요소입니다.
마케팅 비용의 증가
광고에 등록되는 URL이 매번 달라지면, 이를 조정하고 관리하는 데 상당한 인력과 시간이 소요됩니다.
매 기수마다 새로운 URL을 생성하고 각 광고 채널에 적용하는 작업이 반복되면서, 마케팅 운영팀의 업무 부담이 커지고 관리 효율이 떨어집니다. 이러한 비효율성은 단순히 인력 투입의 증가로만 끝나는 것이 아니라, 광고 성과 분석과 최적화에도 부정적인 영향을 미칩니다. 광고 효과를 빠르게 파악하고 예산을 최적화하는 데 시간이 더 걸리기 때문에 불필요한 비용이 추가로 발생할 수밖에 없습니다.
또한, URL에 특정 사업명이나 과정명이 포함되지 않으면 SEO 점수 역시 하락하게 되어, 검색을 통한 유입이 줄어들고 이를 보완하기 위한 유료 광고 집행이 늘어나고 있었습니다.
이처럼 URL 관리의 비효율성은 관리 공수 증가, 광고 효율 저하, SEO 성과 악화 등 여러 측면에서 마케팅 비용을 높이는 주요 원인으로 작용합니다.
데이터 분석의 어려움과 대시보드 관리 부담
새로운 링크가 반복적으로 생성되면, 각 링크별로 유입 데이터를 별도로 집계하고 분석해야 하므로 데이터팀의 업무가 복잡해집니다.
동일한 지원서임에도 불구하고 여러 링크로 인해 데이터가 분산되어, 전체적인 성과를 한눈에 파악하기 어렵고, 이를 보완하기 위해 같은 대시보드도 반복적으로 새로 만들어야 하는 상황이 발생합니다. 이로 인해 데이터 분석의 일관성과 신뢰성이 저하될 수 있으며 데이터 분석팀의 불필요한 반복 업무가 수행됩니다.
고정 URL로 해결해보자
이 글에서는 이러한 문제상황에서 출발하여, 데이터 집계와 분석의 효율성을 높이기 위한 고정 URL 설계와 도입을 진행하려고 합니다.
어떻게 해결할 것인가?
고정된 URL로 접속한 사용자의 요청에서 파라미터를 추출해 서버에 전달하면, 서버는 redis 캐시 또는 DB에서 submissionId를 찾아 기존 API 로직을 그대로 활용해 데이터를 반환하도록 할 예정입니다.
흐름도
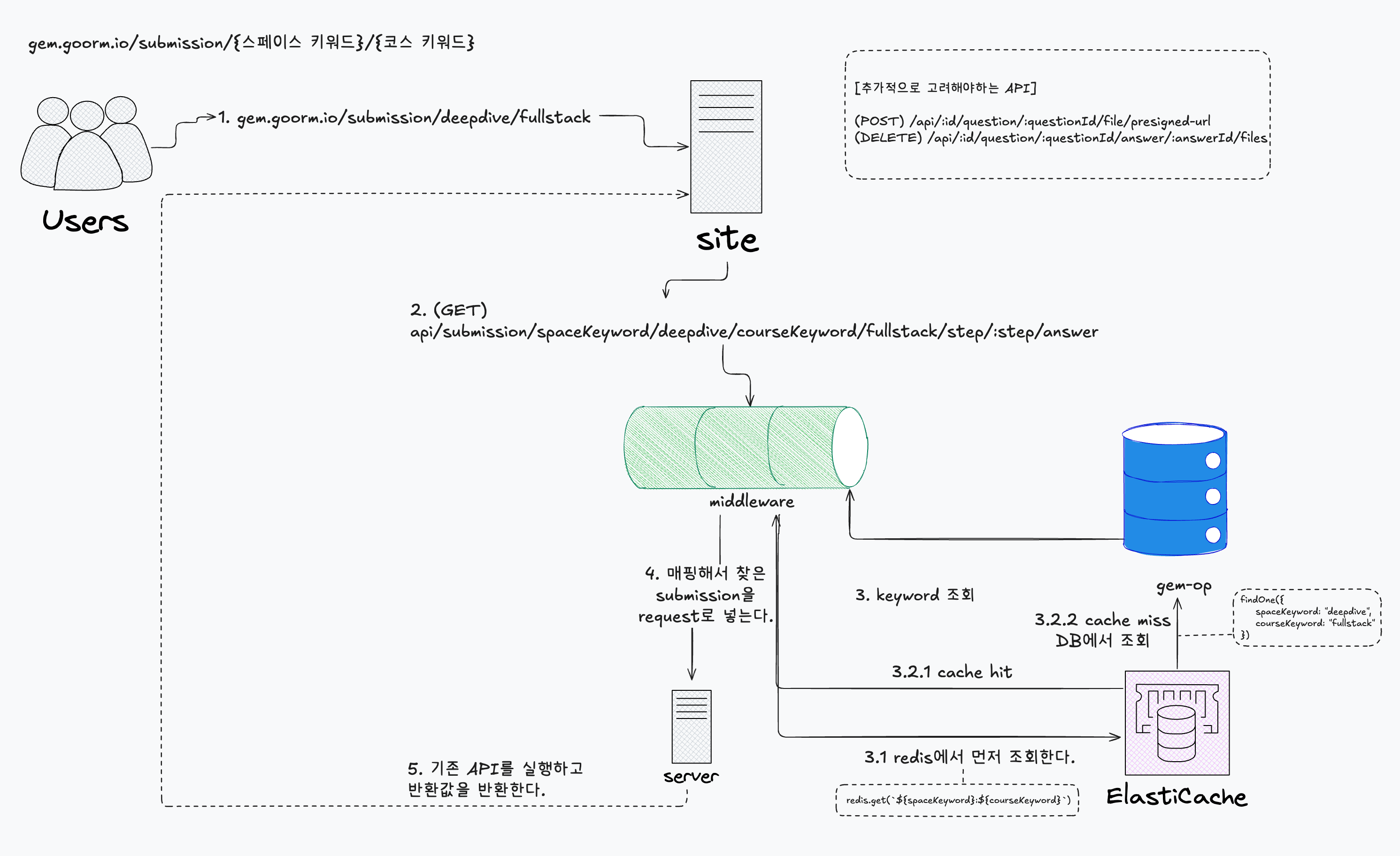
전체적인 흐름은 위와같다.
1. 사용자 접근
- 사용자는 고정된 링크(예: /submission/kdt/full-stack)로 접속합니다.
2. 프론트엔드 파라미터 추출
- 프론트엔드는 URL에서 kdt, full-stack 등의 파라미터를 추출합니다.
3. API 요청
- 추출한 파라미터를 활용해 서버에 다음과 같은 API를 요청합니다. (GET) api/submission/spaceKeyword/:spaceKeyword/courseKeyword/:courseKeyword/step/:step/answer
4. 서버 미들웨어 처리
- 서버는 미들웨어 통해 요청을 가로채고, spaceKeyword와 courseKeyword를 바탕으로 submissionId를 탐색합니다.
- 예시대로면 spaceKeyword로는 kdt, courseKeyword는 full-stack 입니다!
5. 캐시 확인: 우선 redis에 해당 키값이 있는지 확인합니다.
- 캐시 HIT: 캐시에 있으면 해당 submissionId를 사용합니다.
- 캐시 MISS: 캐시에 없으면 DB의 keywords collection을 조회하여 submissionId를 가져옵니다.
6. 기존 API 로직 연동
- 서버는 데이터베이스에서 매핑된 submissionId를 가져와 req.submission에 할당하고, 기존 API 로직을 그대로 사용합니다.
7. 응답 반환
- 서버는 요청된 API에 맞는 결과를 프론트엔드로 반환합니다.
스키마
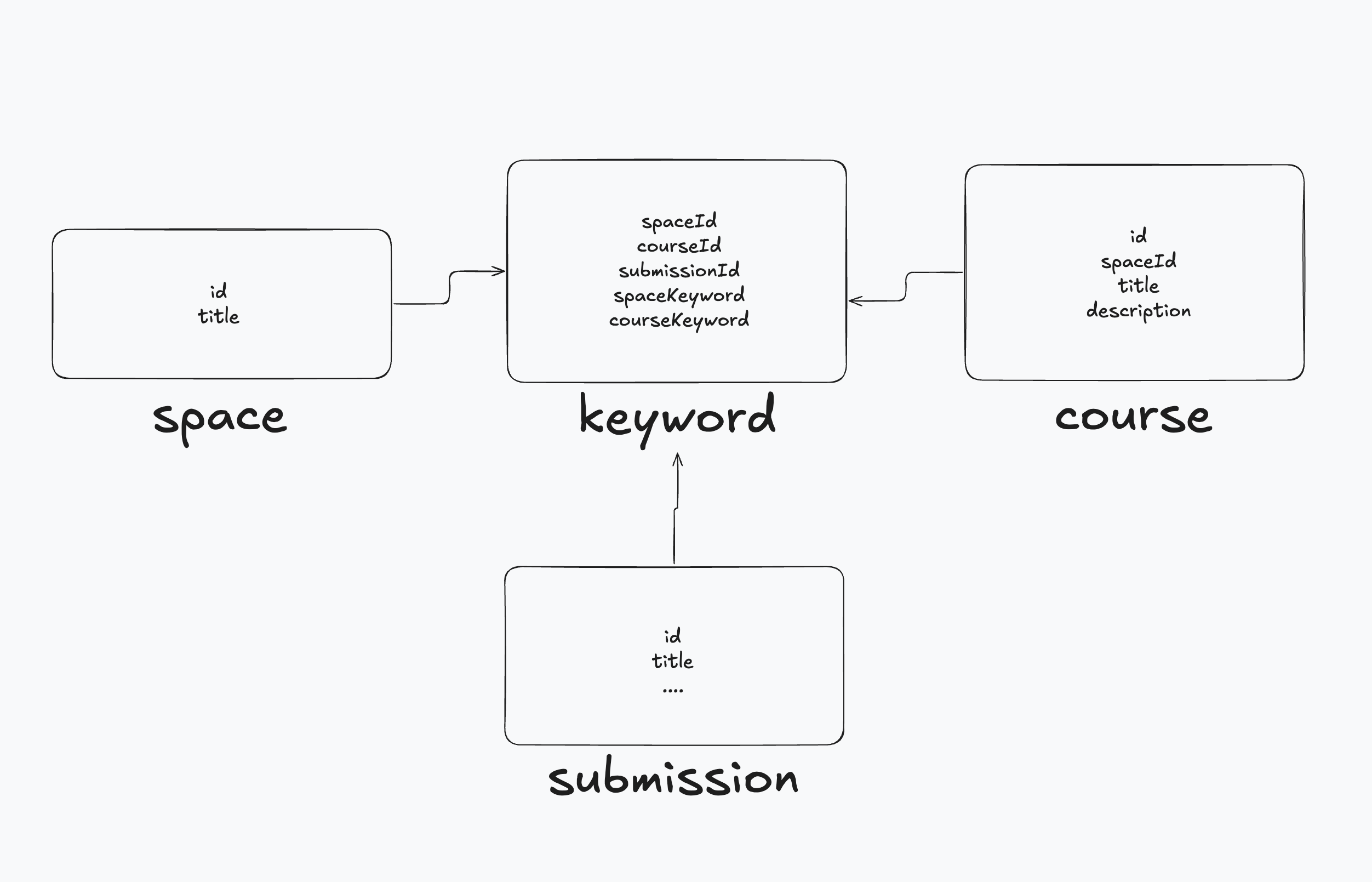
정말 간단한 매핑 컬렉션이다.
정말로 간단한 매핑 컬렉션인데요, URL 호출에 따라 매핑할 리소스를 저장하는 컬렉션입니다.
middleware?
interceptor가 아닌 미들웨어를 사용하는 이유는 기존 API에서 가드를 사용하고 있기 때문입니다. 해당 API는 권한을 체크하기 위한 가드를 사용하고 있는데요, 해당 가드에서 지원서의 고유 id인 submissionId가 필요합니다.
이렇게 되면 라이프사이클 상 가드보다 앞단에서 고정 URL로 들어온 keyword을 submissionId으로 바꿔줘야하는데요. 그렇다기에는 해당 가드보다 먼저 호출하는 가드로 사용하기에는 가드는 인증 / 인가 / 권한 체크 용도로 사용하는게 nest에서 권장하는 방식이라서 목적에 어울리지는 않다고 생각하였습니다. 따라서 라이프사이클상 해당 route에 대해서 가장 앞단에서 만나는 middleware로 적용해두었습니다.
라이프사이클은 middleware(keyword -> submissionId) -> gaurd(submissionId 기반 권한 체크) -> controller -> service -> response 형태로 갑니다.
redis, fallback
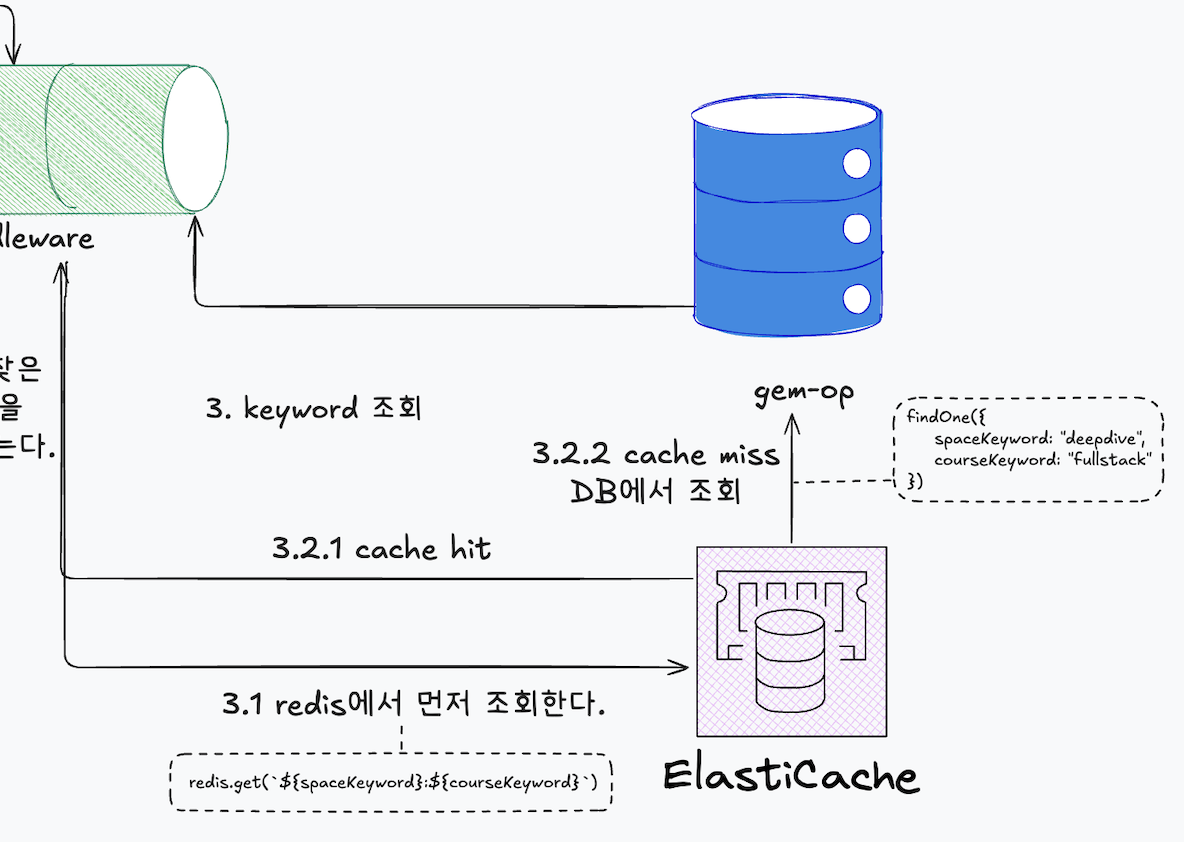
캐싱과 fallback
middleware에서 고정 URL의 spaceKeyword과 courseKeyword를 바탕으로 알맞은 리소스 조회를 진행합니다.
우선 redis에서 pinned-link-keyword:spaceKeyword:courseKeyword 키값으로 조회합니다. 존재하면 해당 키값에 저장된 value인 submissionId를 가져옵니다. 존재하지 않으면 DB를 탐색하는데요, pinned-link-keywords 컬렉션에 쿼리를 날려 submissionId를 가져옵니다.
캐싱을 도입한 이유는, 해당 조회 API가 운영 중인 모집 및 설문조사 서비스에서 가장 빈번하게 사용되는 API이며, 특히 지원자가 많은 부트캠프의 마감 시간에는 트래픽이 집중되어 호출이 급증하기 때문입니다.
캐싱을 통해 응답 속도를 개선하고, 데이터베이스 부하를 줄여 서비스의 안정적인 운영과 데이터베이스의 안정성을 확보하고자 했습니다.
@Injectable()
export class MapPinnedLinkMiddleware implements NestMiddleware {
constructor(
private readonly pinnedLinkKeywordRepository: PinnedLinkKeywordRepository,
private readonly submissionRepository: SubmissionRepository,
@InjectRedis() private readonly redis: Redis,
) {}
async use(
req: Request & {
submissionId: string;
param?: Record<string, string>;
},
res: Response,
next: NextFunction,
) {
const { spaceKeyword, courseKeyword } = req.params;
if (!spaceKeyword || !courseKeyword) {
throw new BadRequestException(
SUBMISSION_ERROR.MISSING_PINNED_KEYWORD,
{
cause: SUBMISSION_ERROR.MISSING_PINNED_KEYWORD.code,
},
);
}
const submissionIdFromRedis = await this.getSubmissionIdFromRedis({
spaceKeyword,
courseKeyword,
});
const submissionId =
submissionIdFromRedis ??
(await this.getSubmissionIdFromDatabase({
spaceKeyword,
courseKeyword,
}));
req.submissionId = submissionId;
next();
}
private async getSubmissionIdFromRedis({
spaceKeyword,
courseKeyword,
}: {
spaceKeyword: string;
courseKeyword: string;
}) {
const pinnedLinkKeywordValue = await this.redis.get(
pinnedLinkKeywordRedisKeyFactory
.key({
spaceKeyword,
courseKeyword,
})
.toKey(),
);
return pinnedLinkKeywordValue;
}
private async getSubmissionIdFromDatabase({
spaceKeyword,
courseKeyword,
}: {
spaceKeyword: string;
courseKeyword: string;
}) {
const pinnedLinkKeyword =
await this.pinnedLinkKeywordRepository.findByKeywords({
spaceKeyword,
courseKeyword,
});
if (!pinnedLinkKeyword) {
throw new BadRequestException(
SUBMISSION_ERROR.INVALID_PINNED_KEYWORD,
{ cause: SUBMISSION_ERROR.INVALID_PINNED_KEYWORD.code },
);
}
return pinnedLinkKeyword.submissionId;
}
}
코드는 위와 같습니다.
고정 URL의 key값을 기반으로 미들웨어에서 submissionId를 조회합니다. 먼저 redis 캐시에서 submissionId를 탐색하고, 캐시에 없을 경우 데이터베이스에서 조회합니다. 데이터베이스에서도 해당 값이 없으면 에러를 반환하도록 처리합니다.
테스트
이제 해당 컬렉션과 미들웨어를 통해서 고정 URL 요청이 와도 올바른 리소스로 매핑하여서 맞는 설문조사 문항을 반환하는데요, 기능에 더불에 캐싱이 정말 유효한지에 대해 알아보겠습니다.
JMeter
JMeter를 활용해 캐시 성능을 측정할 계획입니다. 만약 테스트 결과 성능 개선 효과가 크지 않다면, 캐싱을 도입하지 않는 것이 더 합리적이라고 판단했습니다. 이는 트래픽이 많지 않은 상황에서 굳이 캐시를 쌓고 삭제하며, 데이터베이스와 동기화하는 복잡한 과정을 추가하는 것이 오히려 불필요한 부담이 될 수 있기 때문입니다. 따라서, 캐싱의 실질적인 이점이 없다면 과감히 포기하는 방향이 더 효율적이라고 생각합니다.
요청 세팅
4000명의 동시 요청이 발생하는 상황을 가정하여, 캐시를 적용한 경우와 적용하지 않은 경우 각각의 성능을 테스트해보았습니다.
캐시가 없을 때
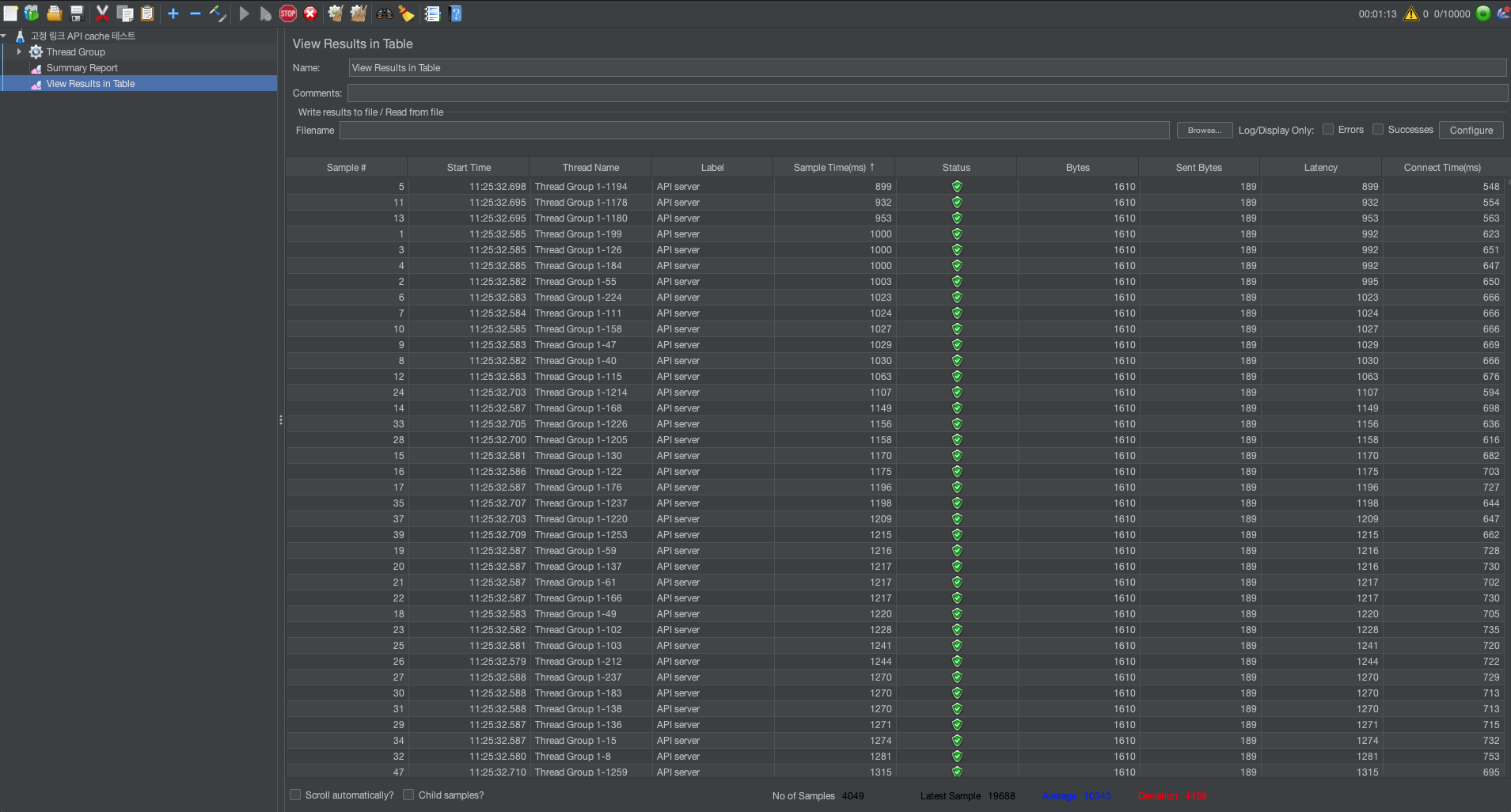
캐시가 없을 때 - 테이블 형태 결과
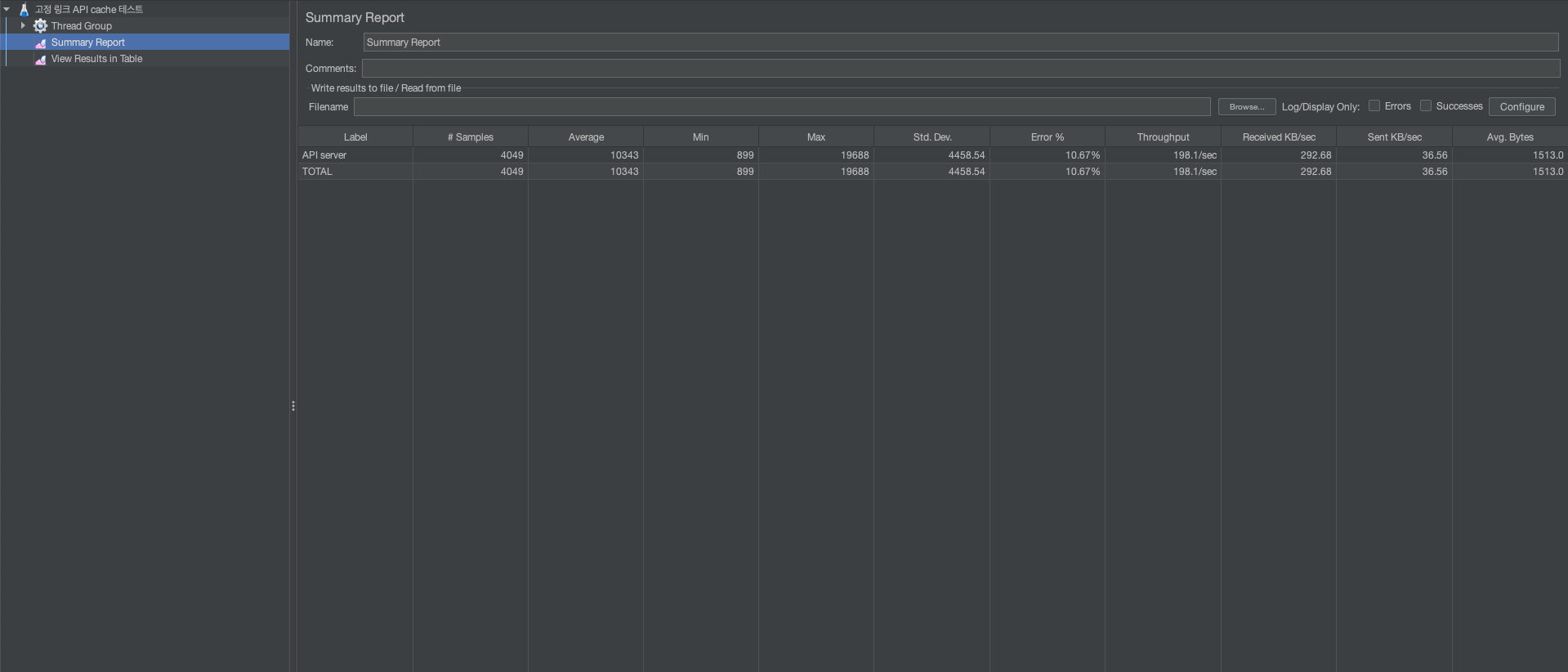
캐시가 없을 때 - 요약 결과
평균적으로 10443ms가 걸렸으며, 가장 오래걸린 작업으로는 19688ms가 걸린 작업이 있습니다.
캐시가 있을 때
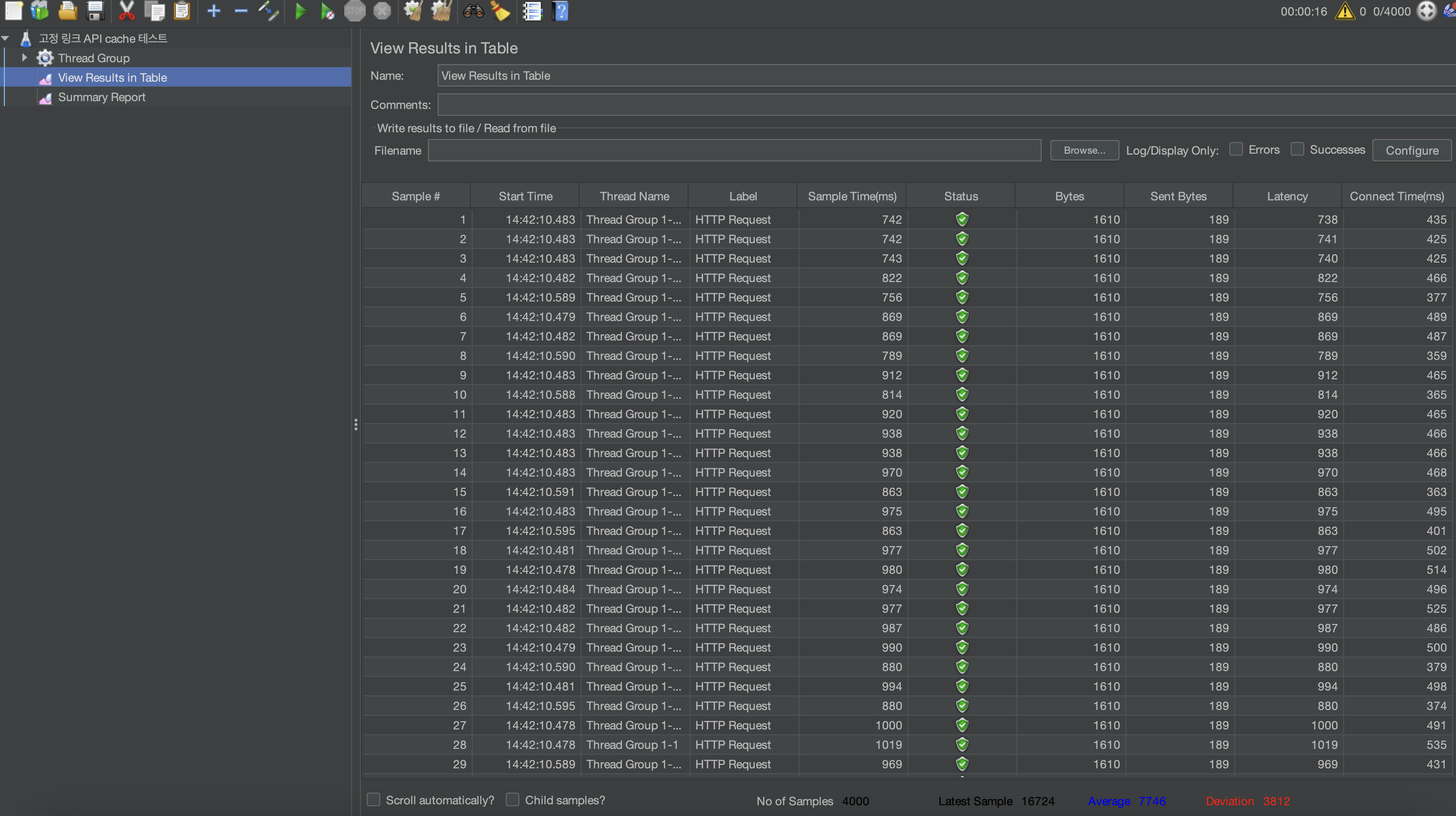
캐시가 있을 때 - 테이블 형태 결과
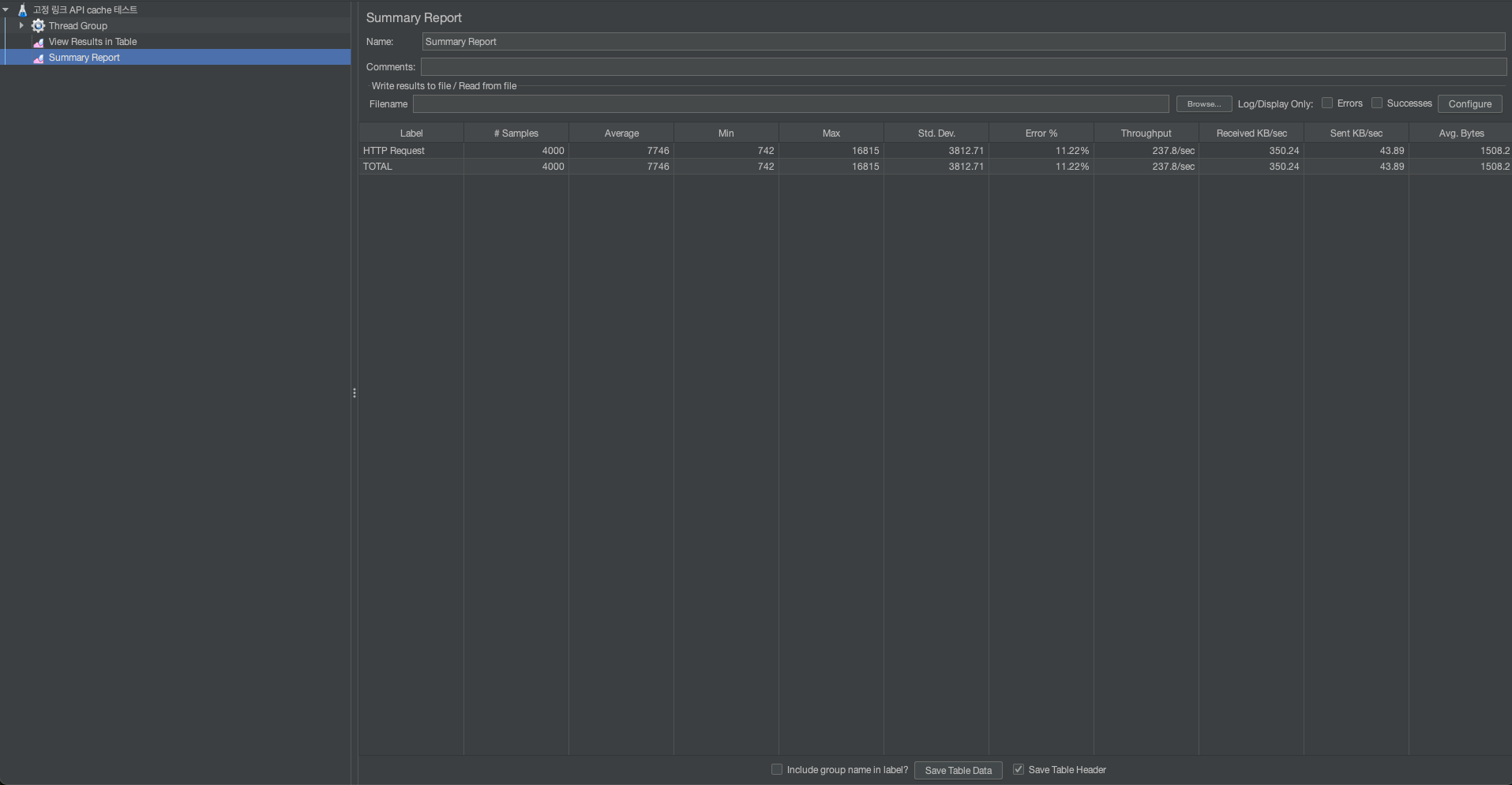
캐시가 있을 때 - 요약 결과
평균적으로 7746ms가 걸렸으며, 가장 오래걸린 작업으로는 16815ms가 걸린 작업이 있습니다.
결론
평균적으로 2697ms의 차이는 충분히 의미 있는 성능 개선이라고 판단했습니다. 실제 서비스 트래픽이 4000명까지 몰리는 상황은 아니지만, 캐시 관리의 부담에 대해 고민해본 결과 구조가 단순하고, 관련 리소스가 수정·삭제될 때도 간단히 캐스케이드로 처리할 수 있어 캐시 적용을 도입하기로 결정했습니다.
마치며
고정 URL을 도입하면서 과정 단위로 모든 이벤트 데이터를 한 곳에 집계할 수 있게 되었고, 퍼널 분석, 전환율 및 이탈률 계산, 행동 이력 추적 등 데이터 기반 마케팅과 운영 의사결정의 신뢰성과 효율성이 크게 향상되었습니다.
또한 DA팀에서는 외부 분석 도구(GA4 등)와의 연동, 내부 데이터 정합성 및 연속성 확보를 통해, 매번 대시보드를 새로 만들어야 하는 번거로움이 줄어들었고, 개발 경험(DX)도 한층 개선되었습니다.
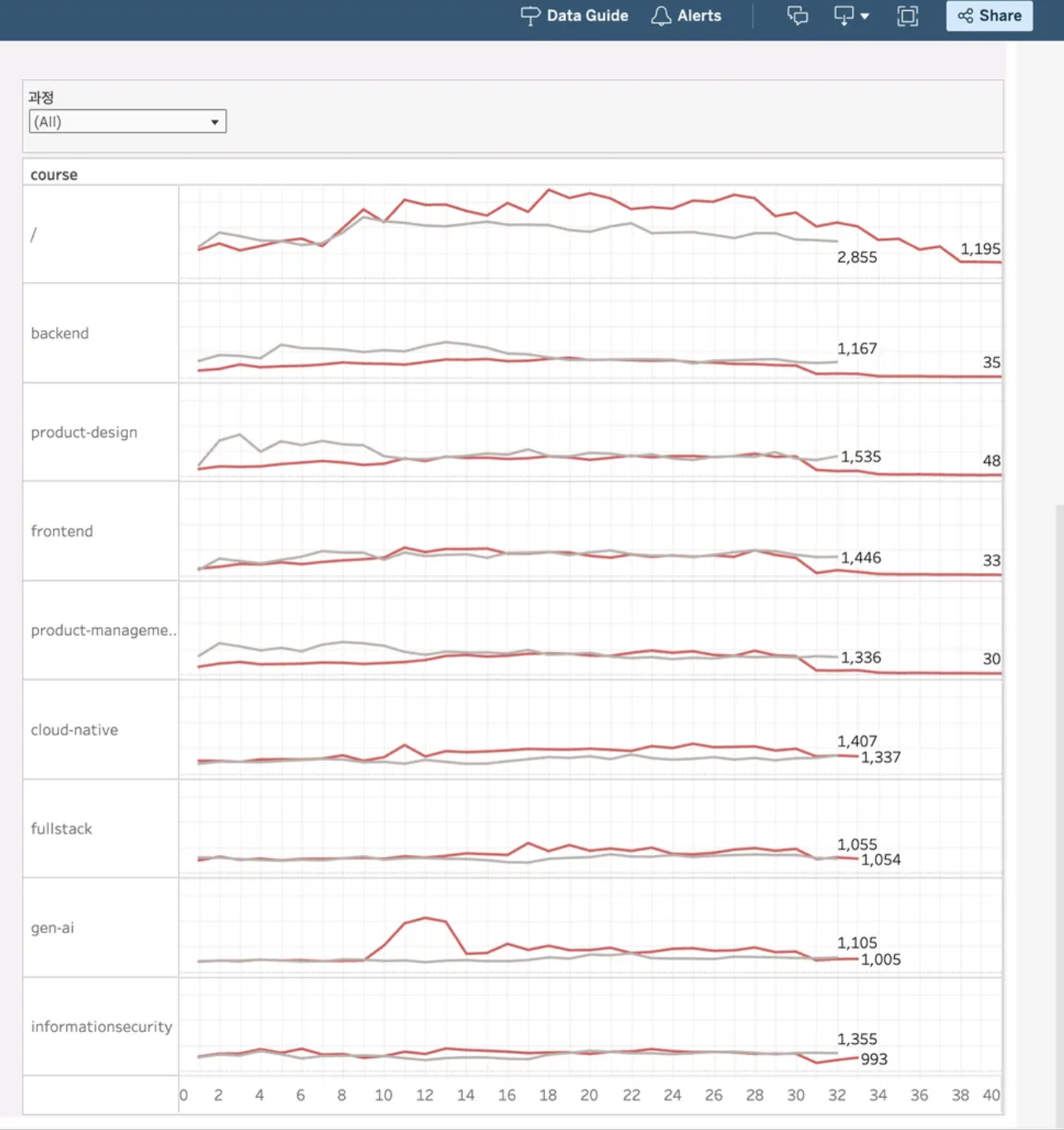
DA팀에서 기존에 사용하고 필요한 통합 과정 데이터이다.
이번 프로젝트를 통해 개발뿐 아니라 실제 데이터와 마케팅을 위한 비즈니스가 어떻게 운영되는지 깊이 이해할 수 있었습니다. 사업을 발전시키고, 어떤 분야에 집중해야 할지 결정하는 데에는 데이터 기반의 의사결정이 필수적임을 실감했고, 이런 데이터를 잘 쌓기 위한 구조를 만드는 일은 앱단 엔지니어들도 적극적으로 고민하고 기여해야 한다는 점을 직접 체감한 소중한 경험이었습니다.