

데이터 유실 없이 Google Spread Sheet 연동하기
들어가며
Google Sheet API를 활용하여 비즈니스 서버에서 발생하는 다양한 데이터를 외부 Google 시트와 연동해 저장할 수 있는데요, 예를 들어, 특정 과정이나 직무에 대한 모집 지원서를 제출하면, 지원자의 답변 내용이 Google 시트에 한 줄씩 기록되는 기능이 있습니다. 즉, 한 명의 지원자가 지원을 완료할 때마다 해당 지원자의 데이터가 시트에 순차적으로 쌓이게 됩니다.
하지만 Google Sheet API에는 엄격한 rate limit(요청 제한)이 존재하는데요, 기본적으로 계정당 1분에 60회, 프로젝트당 1분에 300회의 쓰기 요청만 허용됩니다. 이러한 제한은 평상시에는 큰 문제가 되지 않지만, 지원자가 단기간에 몰리는 상황(예시: 여러 모집 공고가 동시에 열리고, 각 모집에 많은 지원자가 한꺼번에 지원하는 경우)에는 문제가 발생할 수 있습니다. 특히, N개의 모집 공고에 M명의 지원자가 동시에 지원하는 상황에서는 API rate limit에 쉽게 도달하게 되고, 이로 인해 일부 데이터가 시트에 정상적으로 기록되지 못하고 유실되는 문제가 발생합니다.
이처럼 Google Sheet API의 rate limit은 대규모 데이터 입력이 필요한 비즈니스 환경에서 데이터 손실이라는 리스크를 초래할 수 있습니다. 이는 시스템의 신뢰성이 저하될 뿐만 아니라, 실제로 이러한 오류로 인해 지원자가 정상적으로 지원을 완료했음에도 불구하고 지원 내역이 누락되어 지원자에게 피해가 발생할 수 있습니다.
실제로 이러한 문제가 종종 발생해 CS로 문의가 들어오곤 했습니다. 이때마다 내부 데이터베이스에 저장된 값을 수동으로 Google 시트에 갱신하는 방식으로 문제를 해결했습니다. 그러나 이 방식은 고객의 문의가 들어오기 전까지는 문제 상황을 인지하기 어렵다는 한계가 있었으며, 이러한 반복적인 오류로 인해 외부 관계사들이 우리 시스템의 신뢰성을 조금은 낮게 평가하는 결과로 이어졌습니다.

기능 문제로 인해 직접적인 CS가 들어오곤 했다.
어떤 문제점들이 있는가?
우선, Google Sheet API가 제공하는 rate limit 규정에 맞춰 요청이 제한에 걸리지 않도록 데이터를 적절히 쌓아가는 것이 중요합니다. 하지만, 기존 시스템에는 다음과 같은 두 가지 주요 문제가 있습니다.
-
첫째, 요청 방식의 비효율성
현재는 지원서가 한 번 제출될 때마다 Google Sheet API를 1회 호출하는 구조입니다. 즉, 1,000명의 지원자가 동시에 지원하면 시트 API도 1,000번 호출됩니다. 제한된 요청 횟수 내에서 각 지원마다 개별적으로 호출하는 방식은 매우 비효율적입니다.
-
둘째, 실패 대응 체계의 부재
만약 시트 쓰기 요청이 실패하더라도, 이를 자동으로 재시도하거나 관리자에게 알림을 보내는 시스템이 마련되어 있지 않습니다. 이러한 문제로 인해 rate limit에 쉽게 도달할 수 있고, 데이터 유실이나 누락이 발생해도 즉각적으로 대응하기 어렵습니다.
어떻게 해결할 것인가?
위에서 살펴본 바와 같이, 요청 방식의 비효율성을 개선하고 실패 대응 체계를 확립하면 데이터 유실 문제를 효과적으로 해결할 수 있을 것으로 보입니다.
먼저, 요청 방식을 기존의 1:1 방식에서 배치(batch) 방식으로 전환하려고 합니다. 기존에는 지원서가 제출될 때마다 Google Sheet API를 한 번씩 호출했기 때문에, 1000명의 지원자가 동시에 지원하면 1000번의 API 호출이 발생했습니다.
이를 개선하여 한꺼번에 모아서 배치로 작업을 수행하려고 합니다. 예를 들어, 50개 또는 100개씩 데이터를 버퍼에 모아두었다가 한 번에 시트에 기록하는 방식으로 변경하려고 합니다. 이 방식은 실시간으로 시트에 반영되지 않는다는 단점이 있지만, 실제 비즈니스 요구사항이나 사용성을 고려했을 때 실시간 반영은 반드시 필요하지는 않습니다. 실시간성보다는 데이터의 안정적 동기화와 보존이 더 중요하기 때문에, 최대한 실시간에 가깝게 (예시: 1분 간격) 데이터를 모아 한 번에 저장하는 방식을 선택했습니다.
또한, 실패 대응 체계도 강화하려고 합니다. 우선, API 호출이 rate limit에 걸려 실패할 경우 자동으로 재시도하는 기능을 도입합니다. Google Sheet API의 정책상 최대 1분 뒤에 다시 시도할 수 있으므로, 일정 시간(예시: 1분) 딜레이 후 재시도하도록 설계했습니다. 만약 재시도마저 실패하거나, 예기치 못한 오류로 인해 데이터가 시트에 저장되지 못하는 경우에는 개발자가 신속하게 문제를 인지하고 수동으로 복구할 수 있도록 슬랙이나 이메일 등으로 알림을 보내는 시스템도 함께 구축할 예정입니다.
Google Sheet 연동 시 데이터 버퍼링 전략
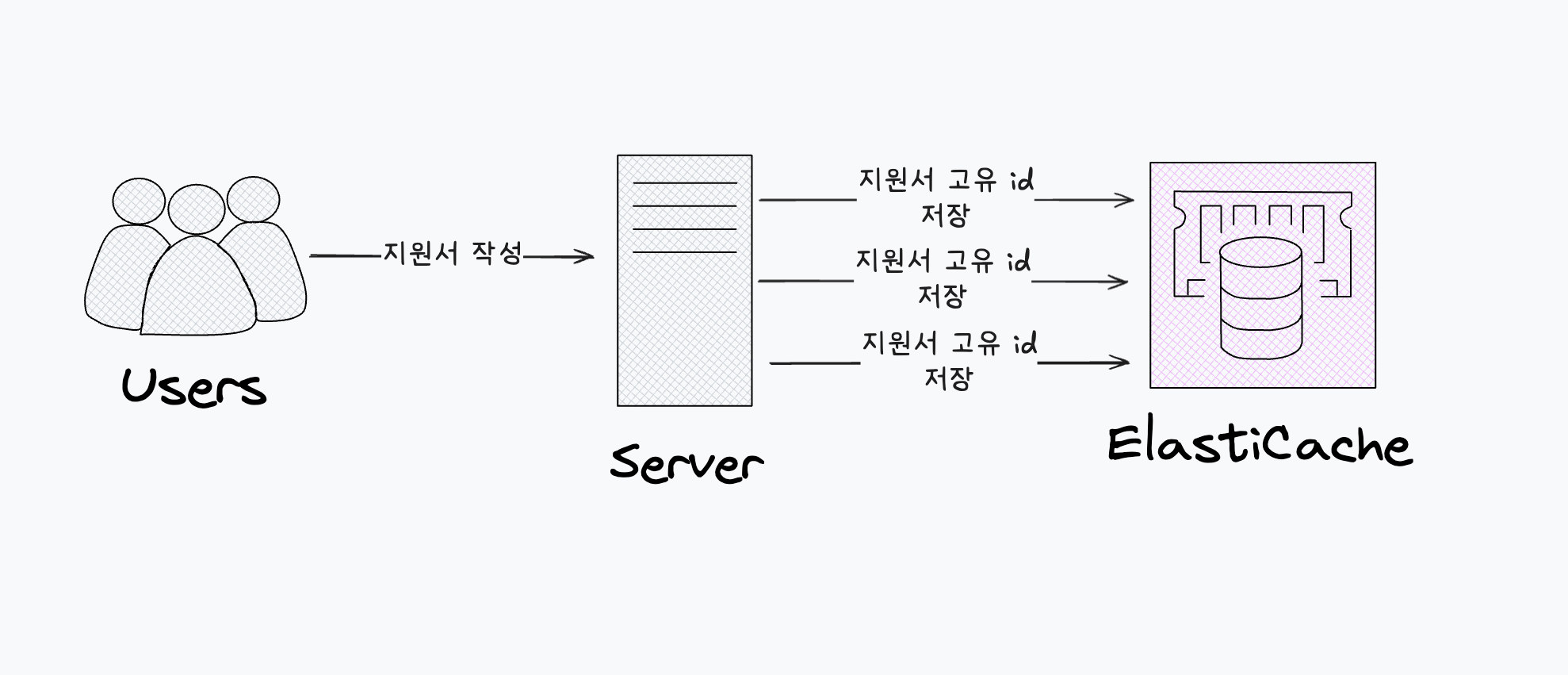
API 요청의 결과값은 redis에 buffering 한다.
지원서가 작성되면, 응답 정보를 즉시 Google 시트에 저장하지 않고 우선 Redis에 임시로 저장합니다. 이때 Redis의 key는 시트마다 고유하게 생성됩니다.
예를 들어, 아래와 같은 정보를 가진 시트가 있다고 가정해보겠습니다.
시트 id: "1o0ZFjwqHdVL2uwvp7er009lken0JLIpANXe1Kpb1d7g"
시트 gid: "1"
시트 권한을 가진 유저 id: "100124216219163297708_8qx6m_google"
이 경우 Redis key는 다음과 같은 형태로 구성됩니다.
spread-sheet:buffer:${시트 권한을 가진 유저 id}:${시트 id}:${시트 gid}
해당 key의 자료구조는 List이며, 지원서 데이터가 들어올 때마다 rpush 명령어를 사용해 계속해서 데이터를 리스트에 추가합니다. 이렇게 쌓인 데이터는 N분마다 배치 작업을 통해 한 번에 시트로 저장됩니다.
Google Sheet 연동 시 데이터 일괄 처리 전략
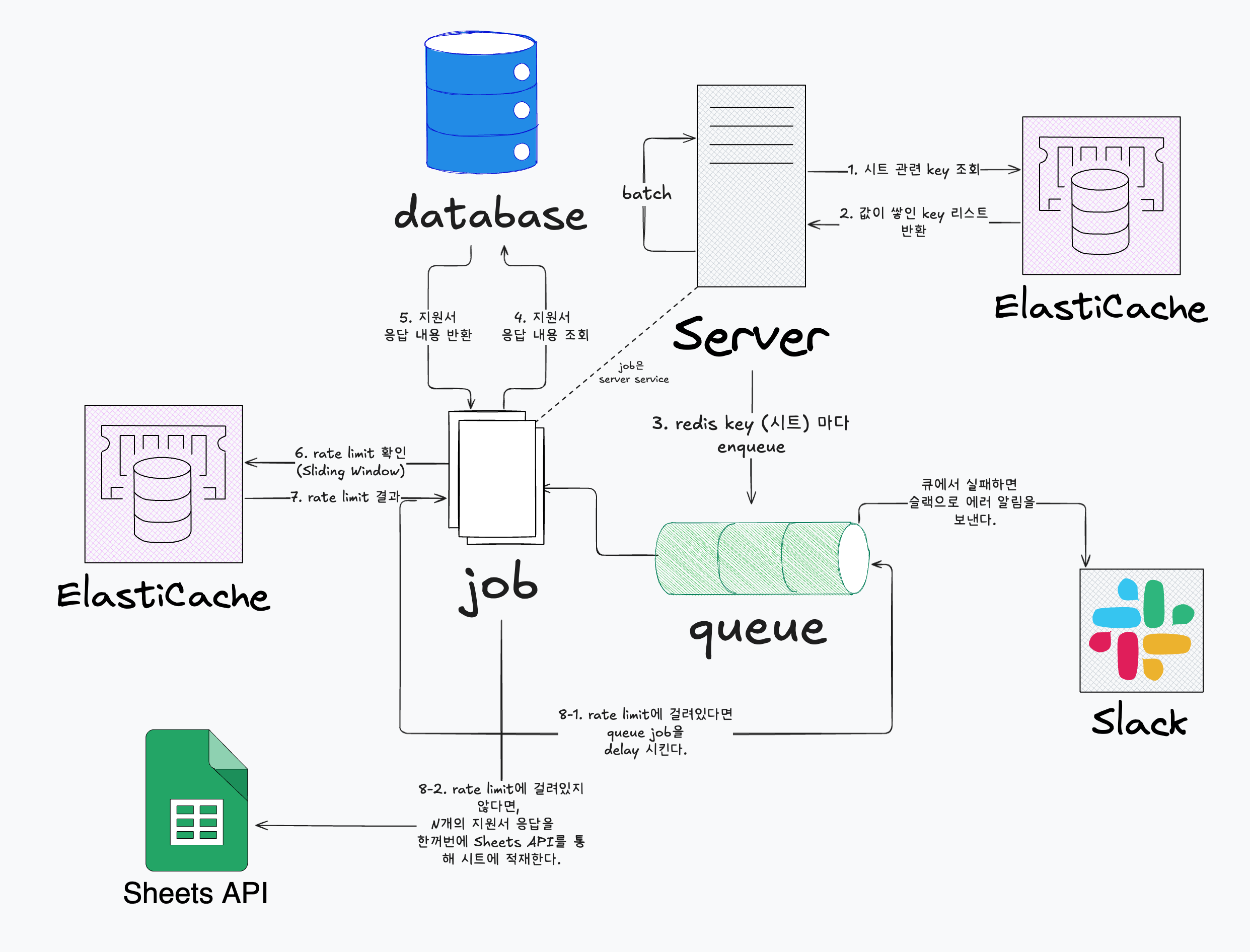
전체적인 데이터 일괄 flush 구상도
- Google Sheet 연동 시 데이터 버퍼링 전략에 따라, 시트별로 쌓여 있는 응답 데이터의 Redis key 목록을 조회합니다.
- 응답 데이터가 존재하는 key에 대해서는 큐에 등록하여 순차적으로 작업을 실행합니다.
- 각 key에 쌓인 응답 데이터를 파싱한 뒤, 각 응답의 고유 ID를 이용해 데이터베이스에서 실제 데이터를 조회합니다. 이 과정을 통해 버퍼에 모인 모든 데이터를 종합하여 응답 배열로 만듭니다.
- Sliding window 방식으로 구현된 rate limiter를 활용해, 1분에 60건의 요청 제한 내에서 현재 작업을 실행할 수 있는지 확인합니다.
- 만약 rate limit에 도달했다면, 해당 key의 작업을 일정 시간 지연시키고, 3회 연속 지연 시 슬랙으로 에러 알림을 전송합니다.
- rate limit에 여유가 있다면, N개의 응답 데이터를 한 번에 Google Sheet API를 통해 시트에 일괄 저장합니다.
버퍼에 쌓는 시점
@Injectable()
export class AppendSubmissionAnswerToSheetInterceptor
implements NestInterceptor
{
constructor(
@InjectLogger()
private readonly logger: PinoLogger,
@InjectRedis() private readonly redis: Redis,
private readonly submissionService: SubmissionService,
) {}
intercept(context: ExecutionContext, next: CallHandler) {
const request = context.switchToHttp().getRequest<PostAnswerRequest>();
const { id: submissionId } = request.params;
const { answerId, status } = request.query;
if (status !== SubmissionAnswerStatus.SUBMITTED) {
return next.handle();
}
return next.handle().pipe(
tap((body) => {
if (body && body.answerId) {
from(
this.appendSubmittedAnswerInSheet({
submissionId,
submissionAnswerId: body.answerId,
}),
)
.pipe(
catchError((error: HttpException) => {
this.logger.error({
message: error.message,
submissionId,
submissionAnswerId: answerId,
error,
});
return of(EMPTY);
}),
)
.subscribe();
}
}),
);
}
private async appendSubmittedAnswerInSheet({
submissionId,
submissionAnswerId,
}: {
submissionId: string;
submissionAnswerId: string;
}) {
// connectedSpreadSheetList: 연동된 시트 정보 리스트를 가져옴
...
await Promise.all(
connectedSpreadSheetList.map(async (spreadSheet) => {
const { spreadSheetId, sheetId, createUserId } = spreadSheet;
const submissionAnswerSheetRedisKey =
submissionAnswerSheetRedisKeyFactory
.buffer({
sheetCreateUserId: createUserId,
submissionId,
spreadSheetId,
sheetId: String(sheetId),
})
.toKey();
// 시트별로 생성된 Redis key의 리스트에 rpush를 통해 응답 데이터를 버퍼로 쌓음
// 각 데이터에는 응답의 고유 ID와 응답 질문 ID 등 필요한 식별 정보를 함께 저장
await this.redis.rpush(
submissionAnswerSheetRedisKey,
JSON.stringify({
submissionId,
submissionAnswerId,
}),
);
}),
);
}
}
지원서 제출 API가 호출되면, 제출이 완료된 이후 response interceptor를 통해 해당 지원서 데이터를 버퍼에 쌓는 작업을 진행합니다. 사용자가 지원서를 제출하면, API 응답을 가로채는 interceptor에서 Redis에 데이터를 저장하는 로직이 동작합니다.
버퍼에서 데이터를 꺼내오는 시점
@Cron(CronExpression.EVERY_MINUTE, {
name: 'submissionAnswerSheetFlushScheduler',
timeZone: 'Asia/Seoul',
})
async processSubmissionAnswerSheetFlush() {
...
const currentLock = await this.redisLockService.getLock({
key: lockKey,
});
if (currentLock) {
return;
}
const lockAcquired = await this.redisLockService.acquireLock({
key: lockKey,
value: String(true),
ttl: 1000,
});
if (!lockAcquired) {
return;
}
const keyList = await this.redisService.getKeyListByPattern({
pattern: submissionAnswerSheetRedisKeyFactory
.bufferPattern()
.toKey(),
});
const filteredKeyList =
await this.bullMQService.getQueueUnProcessingKeyList({
keyList,
delayKey: submissionAnswerSheetFlushQueueRedisKeyFactory
.delayed()
.toKey(),
activeKey: submissionAnswerSheetFlushQueueRedisKeyFactory
.active()
.toKey(),
waitKey: submissionAnswerSheetFlushQueueRedisKeyFactory
.wait()
.toKey(),
});
filteredKeyList.forEach((key) => {
this.submissionAnswerSheetFlushQueue.add(
QUEUE.SUBMISSION_ANSWER_SHEET_FLUSH,
{
key,
},
{
jobId: key,
removeOnComplete: true,
removeOnFail: true,
},
);
});
}
쌓아둔 데이터를 1분마다 스케줄러가 실행되어 꺼내옵니다. 서버가 여러 대로 구성된 환경에서는, 여러 서버가 동시에 같은 배치 작업을 처리하지 않도록 분산 락을 사용해 한 번에 한 서버만 작업을 수행하도록 합니다.
특정 서버가 배치 작업을 진행 중이면 락이 걸려 다른 서버는 접근할 수 없습니다. 락을 획득한 서버는 Redis 버퍼 중 실제 데이터가 존재하는 key만 조회합니다. 각 key(시트)에 대한 작업을 큐에 넣기 전에, 이미 큐에 등록된 key가 있는지 필터링합니다. 이는 rate limit 등으로 인해 재시도 중인 작업이 중복 등록되는 것을 방지하기 위함입니다. 필터링이 완료된 key들만 큐에 job으로 하나씩 enqueue합니다.
redis service
import { Injectable } from '@nestjs/common';
import { Redis } from 'ioredis';
import { InjectRedis } from '../decorator/inject-redis.decorator';
import { LockOptions, UnlockOptions } from '../interface';
@Injectable()
export class RedisLockService {
constructor(@InjectRedis() private readonly redis: Redis) {}
async acquireLock({ key, value, ttl }: LockOptions): Promise<boolean> {
const result = await this.redis.set(key, value, 'PX', ttl);
return result === 'OK';
}
async releaseLock({ key, value }: UnlockOptions): Promise<boolean> {
const multi = this.redis.multi();
multi.watch(key);
const currentValue = await this.redis.get(key);
if (currentValue !== value) {
return false;
}
multi.del(key);
await multi.exec();
return true;
}
async getLock({ key }: { key: string }) {
return await this.redis.get(key);
}
async extendLock({ key, value, ttl }: LockOptions): Promise<boolean> {
const multi = this.redis.multi();
multi.watch(key);
const currentValue = await this.redis.get(key);
if (!currentValue || currentValue !== value) {
return false;
}
multi.pexpire(key, ttl);
const results = await multi.exec();
return results !== null;
}
}
lock을 get, acquire, release하는 메서드들입니다.
문제점: 다중 환경에서 동시에 접근하면 분산락이 잘 적용되는가?
사실 위 redis 메서드나 버퍼에서 데이터를 꺼내오는 시점에서 락을 거는 방식은 잘못되었습니다. 우선 테스트 코드부터 짜서 실행해보겠습니다.
it('동시에 여러 서버가 락을 시도해도 하나만 성공해야 한다', async () => {
const getLockAndAcquireLock = async () => {
const lockKey = 'test-lock';
const currentLock = await redisLockService.getLock({
key: lockKey,
});
if (currentLock) {
return false;
}
const lockAcquired = await redisLockService.acquireLock({
key: lockKey,
value: String(true),
ttl: 1000,
});
if (!lockAcquired) {
return false;
}
return true;
}
const results = await Promise.all([
getLockAndAcquireLock(),
getLockAndAcquireLock(),
getLockAndAcquireLock(),
getLockAndAcquireLock(),
]);
expect(results.filter(Boolean).length).toBe(1);
})
it('동시에 여러 서버가 락을 시도해도 하나만 성공해야 한다', async () => {
const lockKey = 'test-lock';
const results = await Promise.all([
redisLockService.acquireLock({ key: lockKey, value: 'test', ttl: 1000 }),
redisLockService.acquireLock({ key: lockKey, value: 'test', ttl: 1000 }),
redisLockService.acquireLock({ key: lockKey, value: 'test', ttl: 1000 }),
redisLockService.acquireLock({ key: lockKey, value: 'test', ttl: 1000 }),
]);
expect(results.filter(Boolean).length).toBe(1);
});
첫 번째 테스트 코드는 여러 서버(또는 요청)가 동시에 getLock으로 락이 걸린 키의 상태를 조회한 후, acquireLock으로 락을 획득하려고 시도하는 방식입니다.
두 번째 테스트 코드는 여러 서버가 동시에 acquireLock을 호출하여 락을 획득하려고 시도하는 방식입니다.
기대하는 결과는 두 테스트 모두에서 오직 한 서버(또는 요청)만 락을 획득하는 데 성공하는 것입니다.
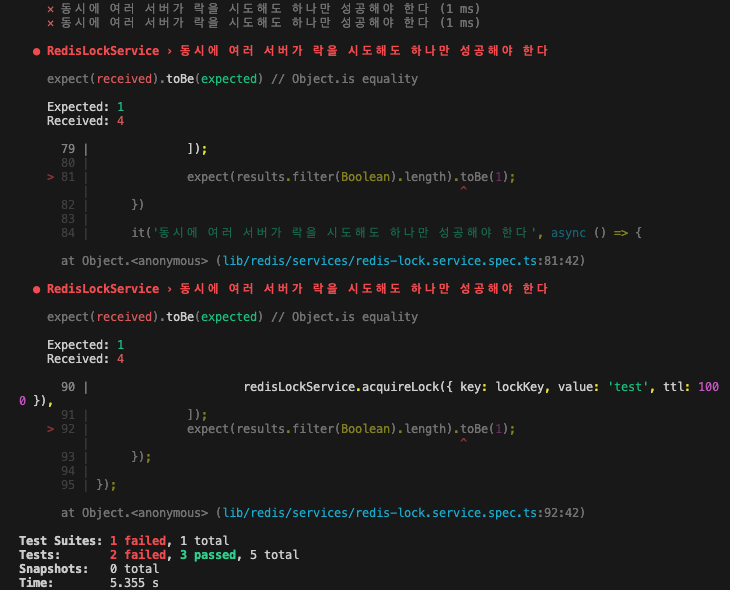
4개 동시요청이 모두 lock을 얻으며 테스트가 실패한다.
하지만 위 결과를 보면 네개의 요청(서버) 모두 성공적으로 acquireLock에 성공한 것을 확인할 수 있습니다.
생각해보면 당연하다!
생각해보면 그렇습니다. N개의 요청이 모두 동시에 발생한다면, 각 요청은 자신이 lock이 없다고 판단하고 lock을 요청하여 획득하려고 할 것입니다.
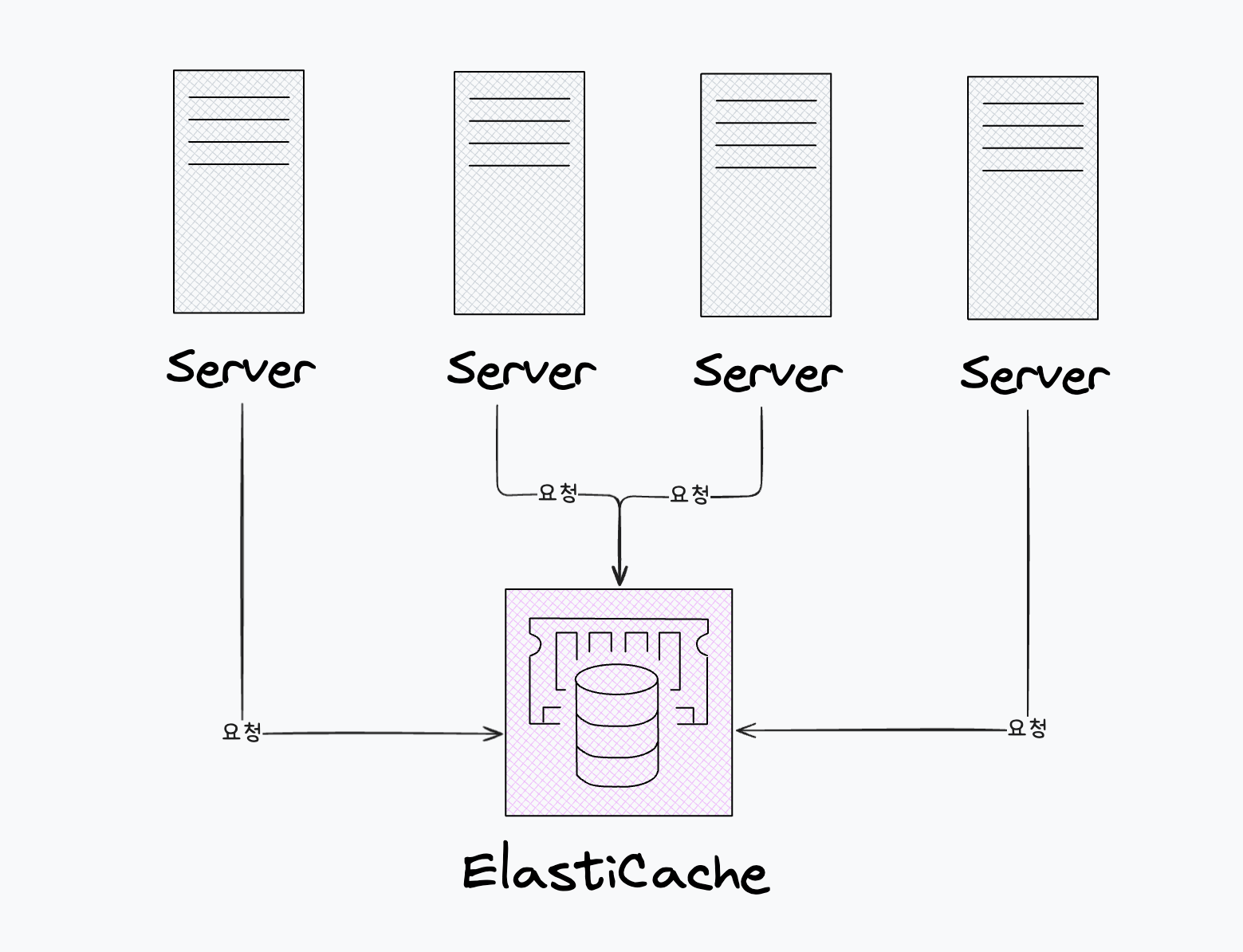
4개 동시요청이 모두 lock이 없다고 생각하여 모두 lock을 획득한다.
const currentLock = await redisLockService.getLock({
key: lockKey,
});
if (currentLock) {
return false;
}
동시에(거의 동시에) 여러 서버가 key 값을 조회하면, 아직 값이 쓰여지기 전이기 때문에 빈 값이 반환될 수 있습니다. 따라서 getLock 메서드를 사용하는 것은 사실상 의미가 없습니다.
const lockAcquired = await redisLockService.acquireLock({
key: lockKey,
value: String(true),
ttl: 1000,
});
if (!lockAcquired) {
return false;
}
이 부분도 동일합니다. acquireLock를 동시에(거의 동시에) 요청하게 되면, 모두 값이 없었기 때문에 key에 대해 value를 세팅할 수 있거든요. 따라서 lockAcquired은 매번 true로 성공합니다.
해결방법: SET 메서드의 NX 옵션을 사용하자
사실 해결 방법은 꽤 간단합니다. Redis에서는 race condition에 대응할 수 있도록 NX 옵션을 제공하고 있습니다.
NX: Only set the key if it does not already exist.
즉, 해당 key가 존재하지 않을 때만 값을 설정하는데요, 여러 서버가 동시에 요청하더라도 오직 한 서버만 성공적으로 값을 세팅할 수 있습니다.
4개 동시요청이 모두 lock을 얻으며 테스트가 실패한다.
이 패턴은 Redis에서 간단한 락 시스템을 구현할 때 공식적으로도 추천하는 방법입니다. (물론, Redlock 알고리즘을 더 권장합니다.)
async acquireLock({ key, value, ttl }: LockOptions): Promise<boolean> {
const result = await this.redis.set(key, value, 'PX', ttl, 'NX');
return result === 'OK';
}
동시성 처리가 전혀 되지 않은 getLock 메서드(redis GET) 사용은 무의미하여 사용할 필요가 없습니다. NX 옵션을 적용한 SET 메서드를 사용하기만 하면 되는데요, 해당 메서드인 acquireLock을 시도해서 성공하면 락을 얻은 것이고, 실패하면 락을 얻지 못한 것입니다. 서버가 여러 대일 때도 오직 한 서버만 락을 획득하고, 나머지는 실패하게 됩니다.
문제점 해결 확인
그럼 테스트 코드를 다시 실행해볼까요?
it('동시에 여러 서버가 락을 시도해도 하나만 성공해야 한다', async () => {
const lockKey = 'test-lock';
const results = await Promise.all([
redisLockService.acquireLock({ key: lockKey, value: 'test', ttl: 1000 }),
redisLockService.acquireLock({ key: lockKey, value: 'test', ttl: 1000 }),
redisLockService.acquireLock({ key: lockKey, value: 'test', ttl: 1000 }),
redisLockService.acquireLock({ key: lockKey, value: 'test', ttl: 1000 }),
]);
expect(results.filter(Boolean).length).toBe(1);
});
동일한 테스트 코드를 실행해 보겠습니다.

4개 동시요청이 중 1개만 lock을 얻으며 테스트가 성공한다.
이번에는 여러 요청이 동시에 들어가도 오직 한 개만 락을 획득하는 것을 확인할 수 있습니다.
코드를 수정해보자
AS-IS
@Cron(CronExpression.EVERY_MINUTE, {
name: 'submissionAnswerSheetFlushScheduler',
timeZone: 'Asia/Seoul',
})
async processSubmissionAnswerSheetFlush() {
...
const currentLock = await this.redisLockService.getLock({
key: lockKey,
});
if (currentLock) {
return;
}
const lockAcquired = await this.redisLockService.acquireLock({
key: lockKey,
value: String(true),
ttl: 1000,
});
if (!lockAcquired) {
return;
}
...
}
TO-BE
@Cron(CronExpression.EVERY_MINUTE, {
name: 'submissionAnswerSheetFlushScheduler',
timeZone: 'Asia/Seoul',
})
async processSubmissionAnswerSheetFlush() {
...
const lockAcquired = await this.redisLockService.acquireLock({
key: lockKey,
value: String(true),
ttl: 1000,
});
if (!lockAcquired) {
return;
}
...
}
AS-IS -> TO-BE와 같이 불필요한 getLock 메서드를 제외해두었습니다.
rate limit을 고려해 Google Sheet API를 통해 시트에 적재
@Processor(QUEUE.SUBMISSION_ANSWER_SHEET_FLUSH)
export class SubmissionAnswerSheetFlushConsumer extends WorkerHost {
constructor(
private readonly rateLimiter: RateLimiter,
@InjectRedis() private readonly redis: Redis,
private readonly googleSpreadSheetService: GoogleSpreadSheetService,
private readonly submissionAnswerService: SubmissionAnswerService,
) {
super();
}
async process(job: Job<SubmissionAnswerSheetFlushJob>) {
try {
const { key } = job.data;
const { sheetCreateUserId, spreadSheetId, sheetId } =
this.getInfoFromKey(key);
await this.checkAndDelayIfRateLimited({
sheetCreateUserId,
job,
});
await this.writeToGoogleSpreadsheet({
spreadSheetId,
sheetId,
sheetCreateUserId,
key,
});
await this.redis.ltrim(key, 1, 0);
} catch (error) {
if (error instanceof DelayedError) {
throw error;
}
if (error instanceof BadRequestException) {
throw new UnrecoverableError(error.message);
}
throw new UnrecoverableError('예상하지 못한 오류가 발생했습니다.');
}
}
private async checkAndDelayIfRateLimited({
sheetCreateUserId,
job,
}: {
sheetCreateUserId: string;
job: Job<SubmissionAnswerSheetFlushJob>;
}) {
const canProcess = await this.rateLimiter.checkLimit({
key: submissionAnswerSheetRedisKeyFactory
.limit({ sheetCreateUserId })
.toKey(),
options: {
limit: RATE_LIMIT_COUNT,
windowMs: RATE_LIMITER_WINDOW_MS,
},
});
if (!canProcess) {
await job.moveToDelayed(Date.now() + RATE_LIMITER_WINDOW_MS);
throw new DelayedError();
}
}
...
}
먼저, 키값을 기준으로 Google Sheet API의 rate limit에 걸려 있는지 확인합니다. 만약 rate limit에 걸려 있다면, 큐에서 해당 작업을 1분간 지연시킨 후 1분 뒤에 다시 시도합니다. rate limit에 걸려 있지 않다면, Google Sheet API를 통해 데이터를 한 번에 시트에 적재합니다. 임시로 버퍼에 쌓아둔 Redis 키의 List 값을, ltrim 명령어를 사용해 모두 비워줍니다.
checkAndDelayIfRateLimited
private async checkAndDelayIfRateLimited({
sheetCreateUserId,
job,
}: {
sheetCreateUserId: string;
job: Job<SubmissionAnswerSheetFlushJob>;
}) {
const canProcess = await this.rateLimiter.checkLimit({
key: submissionAnswerSheetRedisKeyFactory
.limit({ sheetCreateUserId })
.toKey(),
options: {
limit: RATE_LIMIT_COUNT,
windowMs: RATE_LIMITER_WINDOW_MS,
},
});
if (!canProcess) {
await job.moveToDelayed(Date.now() + RATE_LIMITER_WINDOW_MS);
throw new DelayedError();
}
}
rate limit을 체크하고, 걸려있다면 Job을 큐에서 딜레이 (1분) 시키는 코드입니다.
RateLimiter (Sliding Window Algorithm)
@Injectable()
export class RateLimiter {
constructor(@InjectRedis() private readonly redis: Redis) {}
async checkLimit({
key,
options,
}: {
key: string;
options: RateLimitOptions;
}): Promise<boolean> {
const { limit = 60, windowMs = 60 * 1000 } = options;
const now = Date.now();
const multi = this.redis.multi();
multi.zadd(key, now, `${now}-${uuid()}`);
multi.zremrangebyscore(key, 0, now - windowMs);
multi.zcard(key);
multi.expire(key, Math.ceil(windowMs / 1000) * 2);
const results = await multi.exec();
if (!results?.[2]?.[1]) {
return false;
}
const count = results?.[2]?.[1] as number;
return count <= limit;
}
}
Sliding-window 는 마치 시간이 흐르면서 옆으로 움직이는 창문처럼, 최근 일정 시간 동안의 요청만 세어서 제한을 거는 방식 입니다.
rateLimiter 클래스는 Sliding Window 방식의 rate limiter로, 최근 windowMs(1분) 동안의 요청 횟수를 체크하여, limit 이하일 때만 true를 반환합니다.
- Redis 트랜잭션(multi)을 시작합니다.
- 현재 시간(now)을 score로, key의 Sorted Set에 추가합니다. (zadd)
- windowMs(예: 1분) 이전의 score(=timestamp)를 가진 값들을 Sorted Set에서 제거합니다. 즉슨, 현재 윈도우 범위 내의 데이터만 남깁니다. (zremrangebyscore)
- 해당 Sorted Set의 전체 원소 개수(=현재 윈도우 내 요청 수)를 구합니다. (zcard)
- 해당 key의 만료 시간을 윈도우 크기의 2배(초 단위)로 설정합니다. 오래된 데이터가 자동으로 삭제되도록 만료 정책을 적용합니다. (expire)
- 위에서 쌓은 모든 명령을 한 번에 실행하고, 결과(count)를 받아옵니다.
- 윈도우 내 요청 수가 limit 이하이면 true(요청 허용), limit을 초과하면 false(요청 차단)를 반환합니다.

전체 시스템 테스트
이제 구현을 완료했으니 1000개의 요청(동시에 100개씩)이 한꺼번에 들어왔을때 해당 시스템이 잘 시트를 처리할 수 있는지 확인하겠습니다. 요청을 테스트해보기 위해서는 Apache의 ab를 사용하도록 하겠습니다.
request (cli)
ab -n 1000 -c 100 \
-p <(echo '{"answerList": [지원서 작성 데이터]}') \
-T application/json \
"API 서버 url"
cli에 위와 같은 request를 통해 테스트를 진행합니다. 1000개의 요청을 100개씩 POST method로 서버에 보내는 방식입니다.
실행 결과
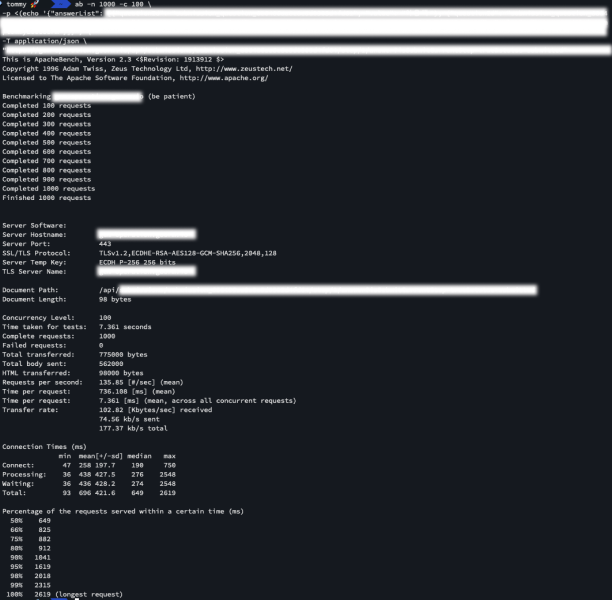
요청에 대한 결과가 날아온다.
문제 없이 잘 실행 되었네요. 결과는 아래와 같습니다!
성공, Complete requests : 1000개
실패, Failed requests : 0개
지원 데이터: document 1000개 생성 완료
시트 적재 결과
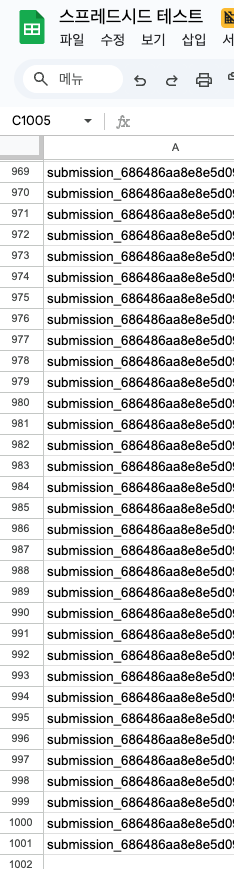
시트에 정상적으로 잘 적재되었다!
가장 중요한 현재 시스템이 수행하는 작업을 확인할 수 있는 시트 연동 현황입니다. 1000개의 요청이 있었으니, 시트에는 1000개의 행(헤더 포함 1001행)이 쌓여야 합니다. 결과적으로, 데이터가 정상적으로 잘 쌓인 것을 확인할 수 있었습니다.
마치며
이전에는 문제가 발생해 불안정하게 운영되던 시트 기능들을 보다 안정적으로 개선할 수 있어, 매우 의미 있는 작업이었다고 생각합니다. rate limit은 구글 API뿐만 아니라 거의 모든 API에 존재하는데, 비즈니스에 영향을 주지 않도록 적절히 우회하고 효율적으로 활용하는 것이 중요하다고 봅니다. 이를 위해 다양한 기술을 조사하고, 적합성을 판단하며, 아키텍처 설계와 구현, 동시성 상황 테스트, 실제 배포 및 운영까지 전 과정을 경험한 점이 뜻깊었습니다.
물론 하나의 계정을 사용하다 보니 시트가 늘어날수록 rate limit에 걸려 지연이 발생할 가능성이 높아집니다. 이런 부분과 시스템의 완성도를 더욱 높이기 위해 추가적인 고민이 필요하다고 생각합니다.
앞으로도 이러한 문제를 보완하기 위해 더 깊이 리서치하고, 운영과 수정 과정을 반복하며 기술과 전체 흐름을 더욱 깊이 이해해보고자 합니다.